TensorFlow 2.0 Beta : 上級 Tutorials : カスタマイズ :- カスタム訓練: ウォークスルー (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 10/29/2019
* 本ページは、TensorFlow org サイトの TF 2.0 – Advanced Tutorials – Customization の以下のページを翻訳した上で
適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- Windows PC のブラウザからご参加が可能です。スマートデバイスもご利用可能です。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ |
| Facebook: https://www.facebook.com/ClassCatJP/ |
カスタマイズ :- カスタム訓練: ウォークスルー
このガイドはアイリス花を種で分類するために機械学習を使用します。それは TensorFlow を次のために使用します : 1. モデルを構築する、2. サンプルデータ上でこのモデルを訓練する、そして 3. 未知のデータについて予測を行なうためにモデルを使用する。
TensorFlow プログラミング
このガイドはこれらの高位 TensorFlow 概念を使用します :
- TensorFlow のデフォルト eager execution 開発環境を使用します、
- Datasets API でデータをインポートします、
- TensorFlow の Keras API でモデルと層を構築します。
このチュートリアルは多くの TensorFlow プログラムのように構造化されています :
- データセットをインポートして解析します。
- モデルのタイプを選択します。
- モデルを訓練します。
- モデルの有効性を評価します。
- 予測を行なうために訓練されたモデルを使用します。
プログラムのセットアップ
インポートを configure する
TensorFlow と他の必要な Python モジュールをインポートします。デフォルトでは、TensorFlow は演算を直ちに評価するために eager execution を使用し、後で実行される 計算グラフ を作成する代わりに具体的な値を返します。もし貴方が REPL か python 対話的コンソールに慣れているのであれば、これは身近に感じるでしょう。
from __future__ import absolute_import, division, print_function, unicode_literals import os import matplotlib.pyplot as plt
import tensorflow as tf
print("TensorFlow version: {}".format(tf.__version__))
print("Eager execution: {}".format(tf.executing_eagerly()))
TensorFlow version: 2.0.0 Eager execution: True
アイリス分類問題
貴方が植物学者で見つけた各アイリス花を分類するための自動化された方法を求めていると想像してください。機械学習は花を統計的に分類する多くのアルゴリズムを提供します。例えば、洗練された機械学習プログラムは写真を基にして花を分類できるでしょう。私達の野望はより控えめなものです — アイリス花をそれらのがく片 (= sepal) と花弁 (= petal) の長さと幅を基にして分類していきます。
アイリス属は約 300 種を必然的に伴いますが、私達のプログラムは以下の3つだけを分類します :
- アイリス・セトサ
- アイリス・バージニカ
- アイリス・バージカラー

Figure 1. アイリス・セトサ (by Radomil, CC BY-SA 3.0)、アイリス・バージカラー (by Dlanglois, CC BY-SA 3.0)、そして アイリス・バージニカ (by Frank Mayfield, CC BY-SA 2.0) 。
幸いなことに、がく片と花弁の測定を持つ 120 アイリス花のデータセット を既に誰かが作成しています。これは初心者の機械学習分類問題に対してポピュラーである古典的なデータセットです。
訓練データセットをインポートして解析する
データセットファイルをダウンロードしてそれをこの Python プログラムで使用できる構造に変換します。
データセットをダウンロードする
tf.keras.utils.get_file 関数を使用して訓練データセット・フアイルをダウンロードします。これはダウンロードされたファイルのファイルパスを返します :
train_dataset_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv"
train_dataset_fp = tf.keras.utils.get_file(fname=os.path.basename(train_dataset_url),
origin=train_dataset_url)
print("Local copy of the dataset file: {}".format(train_dataset_fp))
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/iris_training.csv 8192/2194 [================================================================================================================] - 0s 0us/step Local copy of the dataset file: /home/kbuilder/.keras/datasets/iris_training.csv
データを調べる
このデータセット, iris_training.csv, はプレーンテキスト・ファイルでカンマ区切り値としてフォーマットされた表データ (CSV) をストアしています。最初の 5 エントリを見るために head -n5 コマンドを使用します :
!head -n5 {train_dataset_fp}
120,4,setosa,versicolor,virginica 6.4,2.8,5.6,2.2,2 5.0,2.3,3.3,1.0,1 4.9,2.5,4.5,1.7,2 4.9,3.1,1.5,0.1,0
データセットのこのビューから、次のことが分かります :
- 最初の行はデータセットについての情報を含むヘッダです :
- 120 総計サンプルがあります。各サンプルは4つの特徴と3つの可能なラベル名の1つを持ちます。
- 続く行はデータレコードで、行毎に1つの サンプル で、そこでは :
それをコードに書き出しましょう :
# column order in CSV file
column_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width', 'species']
feature_names = column_names[:-1]
label_name = column_names[-1]
print("Features: {}".format(feature_names))
print("Label: {}".format(label_name))
Features: ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] Label: species
各ラベルは文字列名 (例えば、”setosa”) に関連付けられますが、機械学習は典型的には数値に依拠します。ラベルの数字は命名された表現にマップされます、次のように :
- 0: アイリス・セトサ
- 1: アイリス・バージカラー
- 2: アイリス・バージニカ
特徴とラベルについてのより多くの情報については、ML Terminology section of the Machine Learning Crash Course を見てください。
class_names = ['Iris setosa', 'Iris versicolor', 'Iris virginica']
tf.data.Dataset を作成する
TensorFlow の Dataset API はデータをモデルにロードするための多くの一般的なケースを処理します。これはデータを読みそしてそれを訓練のために使用される形式に変形するための高位 API です。より多くの情報のためには Dataset クイックスタート・ガイド を見てください。
データセットは CSV 形式のテキストファイルですので、データを適切なフォーマットにパースするために make_csv_dataset 関数を使用します。この関数は訓練モデルのためのデータを生成しますので、デフォルトの動作はデータをシャッフルして (shuffle=True, shuffle_buffer_size=10000)、データセットを永久に繰り返します (num_epochs=None)。batch_size パラメータもまた設定します。
batch_size = 32
train_dataset = tf.data.experimental.make_csv_dataset(
train_dataset_fp,
batch_size,
column_names=column_names,
label_name=label_name,
num_epochs=1)
WARNING:tensorflow:From /tmpfs/src/tf_docs_env/lib/python3.6/site-packages/tensorflow_core/python/data/experimental/ops/readers.py:521: parallel_interleave (from tensorflow.python.data.experimental.ops.interleave_ops) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.interleave(map_func, cycle_length, block_length, num_parallel_calls=tf.data.experimental.AUTOTUNE)` instead. If sloppy execution is desired, use `tf.data.Options.experimental_determinstic`.
make_csv_dataset 関数は (features, label) ペアの tf.data.Dataset を返します、ここで features は辞書 : {‘feature_name’: 値} です。
これらの Dataset オブジェクトは iterable です。features のバッチを見てみましょう :
features, labels = next(iter(train_dataset)) print(features)
OrderedDict([('sepal_length', <tf.Tensor: id=68, shape=(32,), dtype=float32, numpy=
array([5. , 5.7, 5.9, 5. , 4.4, 4.4, 6.4, 4.6, 4.6, 6.1, 5. , 6.9, 6.3,
5.8, 6.1, 7.6, 5. , 4.6, 5.7, 6.5, 5.4, 4.7, 6. , 6.1, 6.3, 5.8,
6.1, 6.7, 7.7, 4.8, 6.3, 6.7], dtype=float32)>), ('sepal_width', <tf.Tensor: id=69, shape=(32,), dtype=float32, numpy=
array([3.6, 2.8, 3.2, 3.2, 3.2, 2.9, 3.1, 3.1, 3.2, 3. , 2. , 3.1, 3.4,
2.8, 2.6, 3. , 2.3, 3.6, 3.8, 3. , 3. , 3.2, 2.2, 2.8, 2.7, 2.7,
2.8, 3.3, 3.8, 3.4, 2.5, 3.1], dtype=float32)>), ('petal_length', <tf.Tensor: id=66, shape=(32,), dtype=float32, numpy=
array([1.4, 4.1, 4.8, 1.2, 1.3, 1.4, 5.5, 1.5, 1.4, 4.9, 3.5, 5.1, 5.6,
5.1, 5.6, 6.6, 3.3, 1. , 1.7, 5.8, 4.5, 1.6, 5. , 4.7, 4.9, 5.1,
4. , 5.7, 6.7, 1.6, 5. , 4.4], dtype=float32)>), ('petal_width', <tf.Tensor: id=67, shape=(32,), dtype=float32, numpy=
array([0.2, 1.3, 1.8, 0.2, 0.2, 0.2, 1.8, 0.2, 0.2, 1.8, 1. , 2.3, 2.4,
2.4, 1.4, 2.1, 1. , 0.2, 0.3, 2.2, 1.5, 0.2, 1.5, 1.2, 1.8,
同様な特徴は一緒にグループ化、あるいはバッチ化されることが分かるでしょう。各サンプルの行のフィールドは対応する特徴配列に付加されます。これらの特徴配列にストアされるサンプル数を設定するためには batch_size を変更します。
バッチから幾つかの特徴をプロットすることで幾つかのクラスタを見ることから始めることができます :
plt.scatter(features['petal_length'],
features['sepal_length'],
c=labels,
cmap='viridis')
plt.xlabel("Petal length")
plt.ylabel("Sepal length")
plt.show()
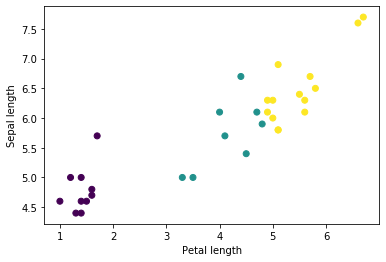
モデル構築ステップを単純化するために、特徴辞書を shape: (batch_size, num_features) を持つシングル配列に再パッケージする関数を作成します。
この関数は tf.stack メソッドを使用します、これは tensor のリストからの値を取得して指定された次元で結合された tensor を作成します。
def pack_features_vector(features, labels): """Pack the features into a single array.""" features = tf.stack(list(features.values()), axis=1) return features, labels
それから各 (features,label) ペアの特徴を訓練データセットにパックするために tf.data.Dataset.map メソッドを使用します :
train_dataset = train_dataset.map(pack_features_vector)
Dataset の特徴要素は今では shape (batch_size, num_features) を持つ配列です。最初の幾つかのサンプルを見てみましょう :
features, labels = next(iter(train_dataset)) print(features[:5])
tf.Tensor( [[5.1 3.7 1.5 0.4] [5.5 2.6 4.4 1.2] [4.6 3.4 1.4 0.3] [5.5 2.4 3.7 1. ] [5.6 2.5 3.9 1.1]], shape=(5, 4), dtype=float32)
モデルのタイプを選択する
何故モデルなのでしょう?
モデル は特徴とラベルの間の関係性です。アイリス分類問題については、モデルはがく片と花弁の測定と予測されるアイリス種の間の関係性を定義します。ある単純なモデルは代数の 2, 3 行で記述できますが、複雑な機械学習モデルは要約することが難しい巨大な数のパラメータを持ちます。
貴方は機械学習を使用することなしに4つの特徴とアイリス種の間の関係性を決定できるでしょうか?つまり、貴方はモデルを作成するために伝統的なプログラミング技術 (例えば、多くの条件ステートメント) を利用できますか?多分 (可能でしょう) — もし貴方がデータセットを特定の種へのがく片と花弁の測定の間の関係性を決定するために十分に長く解析したのであれば。そしてこれはより複雑なデータセット上では難しく — 多分不可能に — なるでしょう。良い機械学習アプローチは貴方のためにモデルを決定します。もし十分な代表的なサンプルを正しい機械学習モデル・タイプに供給すれば、プログラムはその関係性を貴方のために解くでしょう。
モデルを選択する
私達は訓練するモデルの種類を選択する必要があります。多くのモデルのタイプがあり良い一つを選択するには経験が必要です。このチュートリアルではアイリス分類問題を解くためにニューラルネットワークを使用します。ニューラルネットワーク は特徴とラベル間の複雑な関係性を見つけることができます。それは高度に構造化されたグラフで、一つかそれ以上の 隠れ層 へと体系化されます。各隠れ層は一つかそれ以上の ニューロン から成ります。ニューラルネットワークの幾つかのカテゴリがあり、このプログラムは dense、あるいは 完全結合ニューラルネットワーク を使用します : 一つの層のニューロンは前の層の総てのニューロンからの入力接続を受け取ります。例えば、Figure 2 は入力層、2つの隠れ層、そして出力層から成る dense ニューラルネットワークを示します :
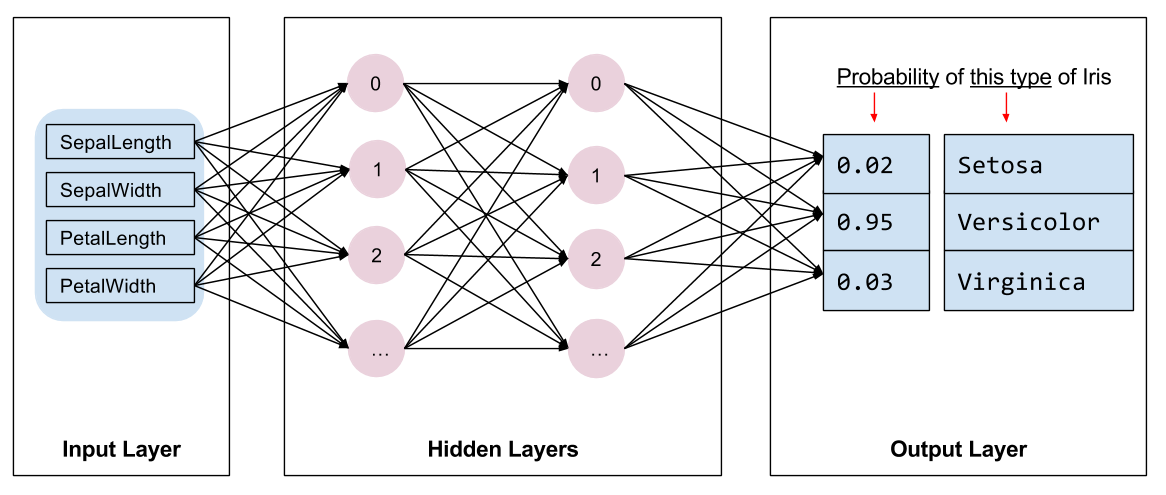
Figure 2 からのモデルが訓練されてラベル付けされていないサンプルが供給されたとき、それは3つの予測を生成します : この花が与えられたアイリス種である尤度です。この予測は 推論 と呼ばれます。このサンプルについて、出力予測の合計は 1.0 です。Figure 2 では、この予測は次のように分解されます : アイリス・セトサのために 0.02, アイリス・バージカラーのために 0.95, そしてアイリス・バージニカのために 0.03 です。これはモデルは — 95% の確率で — ラベル付けされていないサンプル花がアイリス・バージカラーであると予測していることを意味します。
Keras を使用してモデルを作成する
TensorFlow tf.keras API はモデルと層を作成するための好ましい方法です。これがモデルと実験の構築を容易にする一方で Keras は総てを一緒に接続する複雑さを処理します。
tf.keras.Sequential モデルは層の線形スタックです。そのコンストラクタは層インスタンスのリストを取り、この場合では、それぞれ 10 ノードを持つ2つの Dense 層、そしてラベル予測を表わす3つのノードを持つ出力層です。最初の層の input_shape パラメータは dataset からの特徴の数に相当し、そしてこれは必要です :
model = tf.keras.Sequential([ tf.keras.layers.Dense(10, activation=tf.nn.relu, input_shape=(4,)), # input shape required tf.keras.layers.Dense(10, activation=tf.nn.relu), tf.keras.layers.Dense(3) ])
活性化関数 は層の各ノードの出力 shape を決定します。これらの非線形性は重要です — それらなしではモデルはシングル層と同じでしょう。多くの 利用可能な活性 がありますが、隠れ層のためには ReLU が一般的です。
隠れ層とニューロンの理想的な数は問題とデータセットに依拠します。機械学習の多くの様相のように、ニューラルネットワークの最善の shape の選択は知識と実験の混合を必要とします。おおよそのところは、隠れ層とニューロンの数を増加させると典型的にはよりパワフルなモデルを作成し、これは効果的に訓練するためにより多くのデータを必要とします。
モデルを使用する
このモデルが特徴のバッチに何を遂行するかを素早く見てみましょう :
predictions = model(features) predictions[:5]
<tf.Tensor: id=231, shape=(5, 3), dtype=float32, numpy=
array([[-0.543846 , -0.52378184, -0.10649145],
[-0.02903301, -0.12047299, -0.14458351],
[-0.5125149 , -0.5001465 , -0.08259603],
[-0.18031298, -0.22815299, -0.10972097],
[-0.1382576 , -0.19937445, -0.12546575]], dtype=float32)>
ここで、各サンプルは各クラスのために ロジット を返します。
これらのロジットを各クラスのための確率に変換するために、softmax 関数を使用します :
tf.nn.softmax(predictions[:5])
<tf.Tensor: id=236, shape=(5, 3), dtype=float32, numpy=
array([[0.2802006 , 0.28587934, 0.43392003],
[0.35669807, 0.32552838, 0.31777358],
[0.28172362, 0.28522974, 0.43304664],
[0.33042237, 0.31498712, 0.35459054],
[0.33857134, 0.31849852, 0.3429301 ]], dtype=float32)>
クラスに渡る tf.argmax を取れば予測されたクラス・インデックスを与えます。しかし、モデルはまだ訓練されていませんので、これらは良い予測ではありません :
print("Prediction: {}".format(tf.argmax(predictions, axis=1)))
print(" Labels: {}".format(labels))
Prediction: [2 0 2 2 2 0 0 2 0 0 0 0 0 2 0 0 2 0 0 0 0 2 0 2 2 0 2 0 0 0 0 2]
Labels: [0 1 0 1 1 1 1 0 1 2 2 1 2 0 2 2 1 1 1 2 1 1 2 0 0 1 0 2 2 2 2 0]
モデルを訓練する
訓練 はモデルが徐々に最適化される、あるいはモデルがデータセットを学習する際の機械学習のステージです。目標は、初見のデータについて予測を行なうために訓練データセットの構造について十分に学習することです。もし訓練データセットについて学習し過ぎる場合には、予測はそれが見たデータに対して動作するのみで一般化できないでしょう。この問題は overfitting と呼ばれます — それは問題をどのように解くかを理解する代わりに答えを覚えるようなものです。
アイリス分類問題は 教師あり機械学習 の例です : モデルはラベルを含むサンプルから訓練されます。教師なし機械学習 では、サンプルはラベルを含みません。代わりに、モデルは典型的には特徴内のパターンを見つけます。
損失と勾配関数を定義する
訓練と評価ステージの両者はモデルの 損失 を計算する必要があります。これはモデルの予測が望まれるラベルからどのくらい離れているかを測定します、換言すれば、モデルがどのくらい悪く遂行しているかです。私達はこの値を最小化、あるいは最適化することを望みます。
私達のモデルは tf.keras.losses.SparseCategoricalCrossentropy 関数を使用してその損失を計算します、これはモデルのクラス確率予測と望まれるラベルを取り、サンプルに渡る平均損失を返します。
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
def loss(model, x, y):
y_ = model(x)
return loss_object(y_true=y, y_pred=y_)
l = loss(model, features, labels)
print("Loss test: {}".format(l))
Loss test: 1.2178399562835693
モデルを最適化するために使用される 勾配 を計算するために tf.GradientTape コンテキストを使用します :
def grad(model, inputs, targets):
with tf.GradientTape() as tape:
loss_value = loss(model, inputs, targets)
return loss_value, tape.gradient(loss_value, model.trainable_variables)
optimizer を作成する
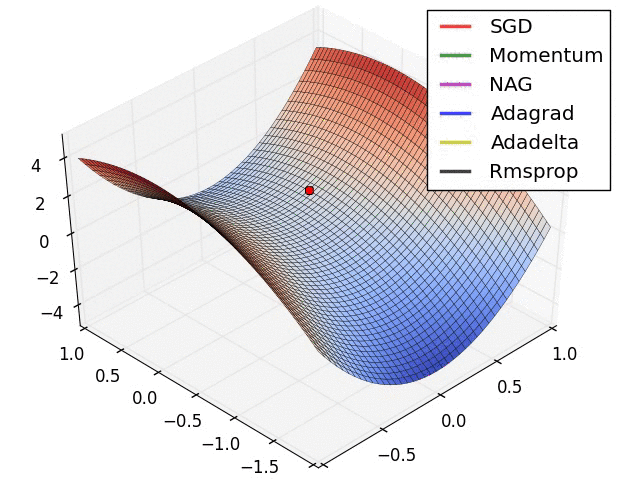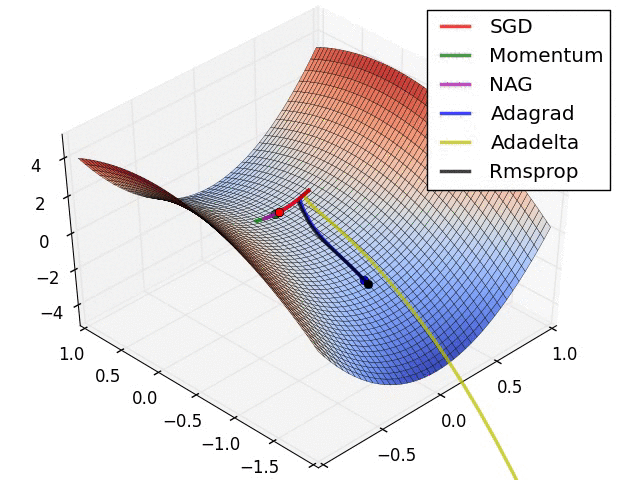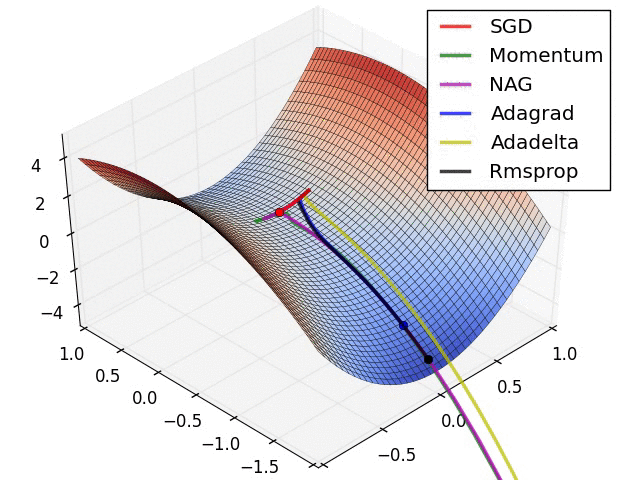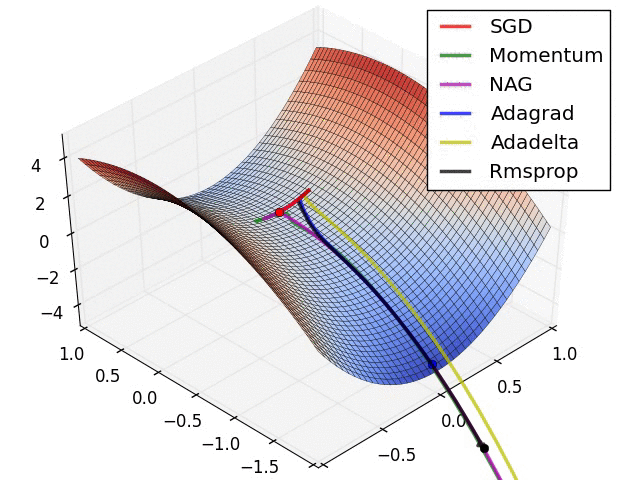
optimizer は loss 関数を最小化するために計算された勾配をモデルの変数に適用します。貴方は損失関数を曲面 (Figure 3 参照) として考えることができて私達は歩き回ることによりその最も低いポイントを見つけることを望みます。勾配は上りの最も険しい方向をポイントします — 従って私達は反対の道に移動して進み丘を降ります。各バッチに対する損失と勾配を反復的に計算することにより、訓練の間にモデルを調整するでしょう。徐々に、モデルは損失を最小化するための重みとバイアスの最善の組み合わせを見つけるでしょう。そして損失がより小さくなれば、モデルの予測はより良くなります。
(ソース: Stanford class CS231n, MIT License, Image credit: Alec Radford)
TensorFlow は訓練のために利用可能な多くの 最適化アルゴリズム を持ちます。このモデルは 確率的勾配降下 (SGD, stochastic gradient descent) アルゴリズムを実装する tf.train.GradientDescentOptimizer を使用します。learning_rate は各反復のための丘を降りるためのステップサイズを設定します。これはより良い結果を得るために一般に調整するハイパーパラメータです。
optimizer をセットアップしましょう :
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
単一の最適化ステップを計算するためにこれを使用します :
loss_value, grads = grad(model, features, labels)
print("Step: {}, Initial Loss: {}".format(optimizer.iterations.numpy(),
loss_value.numpy()))
optimizer.apply_gradients(zip(grads, model.trainable_variables))
print("Step: {}, Loss: {}".format(optimizer.iterations.numpy(),
loss(model, features, labels).numpy()))
Step: 0, Initial Loss: 1.2178399562835693 Step: 1, Loss: 1.144298791885376
訓練ループ
総てのピースが所定の位置にあり、モデルは訓練のための準備ができました! 訓練ループは (モデルが) より良い予測を行なうことを手助けするためにデータセットのサンプルをモデルに供給します。次のコードブロックはこれらの訓練ステップをセットアップします :
- 各エポックを反復します。エポックはデータセットを通した一つのパスです。
- (一つの) エポック内では、特徴 (x) とラベル (y) を取り込んでいる訓練 Dataset の各サンプルに渡り反復します。
- サンプルの特徴を使用して、予測を行ないそれをラベルと比較します。予測の不正確さを測定してモデルの損失と勾配を計算するためにそれを使用します。
- モデル変数を更新するために optimizer を使用します。
- 可視化のために幾つかの統計情報を追跡します。
- 各エポックのために反復します。
num_epochs 変数はデータセット・コレクションに渡りループする回数です。直感に反して、モデルをより長く訓練することはより良いモデルを保証しません。num_epochs は貴方が調整可能な ハイパーパラメータ です。正しい数を選択することは通常は経験と実験の両者が必要です :
## Note: Rerunning this cell uses the same model variables
# Keep results for plotting
train_loss_results = []
train_accuracy_results = []
num_epochs = 201
for epoch in range(num_epochs):
epoch_loss_avg = tf.keras.metrics.Mean()
epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy()
# Training loop - using batches of 32
for x, y in train_dataset:
# Optimize the model
loss_value, grads = grad(model, x, y)
optimizer.apply_gradients(zip(grads, model.trainable_variables))
# Track progress
epoch_loss_avg(loss_value) # Add current batch loss
# Compare predicted label to actual label
epoch_accuracy(y, model(x))
# End epoch
train_loss_results.append(epoch_loss_avg.result())
train_accuracy_results.append(epoch_accuracy.result())
if epoch % 50 == 0:
print("Epoch {:03d}: Loss: {:.3f}, Accuracy: {:.3%}".format(epoch,
epoch_loss_avg.result(),
epoch_accuracy.result()))
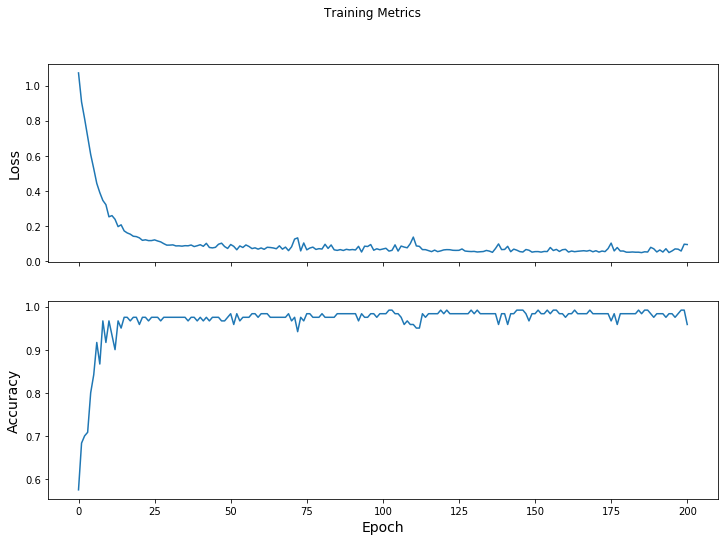
Epoch 000: Loss: 1.072, Accuracy: 57.500% Epoch 050: Loss: 0.092, Accuracy: 98.333% Epoch 100: Loss: 0.067, Accuracy: 98.333% Epoch 150: Loss: 0.052, Accuracy: 98.333% Epoch 200: Loss: 0.092, Accuracy: 95.833%
損失関数を時間に渡り可視化する
モデルの訓練進捗を表示出力することは有用である一方で、この進捗を見ることはしばしばより有用です。TensorBoard は TensorFlow とともにパッケージ化されている良い可視化ツールですが、matplotlib モジュールを使用して基本的なチャートを作成することができます。
これらのチャートを解釈することは何某かの経験が必要ですが、貴方は損失が下がり精度が上がることを見ることを実際に望むでしょう :
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].plot(train_loss_results)
axes[1].set_ylabel("Accuracy", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(train_accuracy_results)
plt.show()
モデルの有効性を評価する
モデルが訓練された今、そのパフォーマンスについて何某かの統計情報を得ることができます。
評価するとはモデルがどのくらい効果的に予測を行なうかを決めることを意味します。アイリス分類でのモデルの有効性を決定するために、幾つかのがく片と花弁の測定をモデルに渡してそれらがどのアイリス種を表わすかを予測するためにモデルに尋ねます。それから実際のラベルに対してモデルの予測を比較します。例えば、入力サンプルの半分の上で正しい種を選択したモデルは 0.5 の 精度 を持ちます。Figure 4 は少しばかりより効果的なモデルを示し、80 % 精度で 5 つの予測から 4 つを正しく得ます :
| サンプル特徴 | ラベル | モデル予測 | |||
| 5.9 | 3.0 | 4.3 | 1.5 | 1 | 1 |
| 6.9 | 3.1 | 5.4 | 2.1 | 2 | 2 |
| 5.1 | 3.3 | 1.7 | 0.5 | 0 | 0 |
| 6.0 | 3.4 | 4.5 | 1.6 | 1 | 2 |
| 5.5 | 2.5 | 4.0 | 1.3 | 1 | 1 |
テストデータセットをセットアップする
モデルを評価することはモデルを訓練することに類似しています。最大の違いはサンプルが訓練セットではなく別の テストセット に由来することです。モデルの有効性を公正に評価するためには、モデルを評価するために使用されるサンプルはモデルを訓練するために使用されたサンプルとは異なっていなければなりません。
テスト Dataset のセットアップは訓練 Dataset のセットアップと同様です。CSV テキストファイルをダウンロードしてその値をパースして、それからそれを少しばかりシャッフルします :
test_url = "https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv"
test_fp = tf.keras.utils.get_file(fname=os.path.basename(test_url),
origin=test_url)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/iris_test.csv 8192/573 [============================================================================================================================================================================================================================================================================================================================================================================================================================================] - 0s 0us/step
test_dataset = tf.data.experimental.make_csv_dataset(
test_fp,
batch_size,
column_names=column_names,
label_name='species',
num_epochs=1,
shuffle=False)
test_dataset = test_dataset.map(pack_features_vector)
テストデータセット上でモデルを評価する
訓練ステージとは違い、モデルはテストデータの単一の エポック を評価するだけです。次のコードセルでは、テストセットの各サンプルに渡り反復してモデルの予測を実際のラベルに対して比較しています。これはテストセット全体に渡るモデルの精度を測定するために使用されます :
test_accuracy = tf.keras.metrics.Accuracy()
for (x, y) in test_dataset:
logits = model(x)
prediction = tf.argmax(logits, axis=1, output_type=tf.int32)
test_accuracy(prediction, y)
print("Test set accuracy: {:.3%}".format(test_accuracy.result()))
Test set accuracy: 93.333%
例えば最後のバッチ上で、モデルは通常は正しいことを見て取れます :
tf.stack([y,prediction],axis=1)
<tf.Tensor: id=115075, shape=(30, 2), dtype=int32, numpy=
array([[1, 1],
[2, 2],
[0, 0],
[1, 1],
[1, 1],
[1, 1],
[0, 0],
[2, 2],
[1, 1],
[2, 2],
[2, 2],
[0, 0],
[2, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[0, 0],
[0, 0],
[2, 2],
[0, 0],
[1, 2],
[2, 2],
[1, 2],
[1, 1],
[1, 1],
[0, 0],
[1, 1],
[2, 2],
[1, 1]], dtype=int32)>
予測を行なうために訓練されたモデルを使用する
私達はモデルを訓練してそれが良いことを「証明」しました — しかし完全ではありません — アイリス種の分類において。今は ラベル付けされていないサンプル 上で幾つか予測を行なうために訓練されたモデルを使用しましょう ; つまり、特徴を含むけれどもラベルを含まないサンプル上です。
現実世界では、ラベル付けされていないサンプルはアプリケーション、CSV ファイル、そしてデータ供給を含む多くの異なるソースに由来するでしょう。当面は、ラベルを予測するために3つのラベル付けされていないサンプルを手動で提供します。思い出してください、次のようにラベル数字は名前付けられた表現にマップされています :
- 0: アイリス・セトサ
- 1: アイリス・バージカラー
- 2: アイリス・バージニカ
predict_dataset = tf.convert_to_tensor([
[5.1, 3.3, 1.7, 0.5,],
[5.9, 3.0, 4.2, 1.5,],
[6.9, 3.1, 5.4, 2.1]
])
predictions = model(predict_dataset)
for i, logits in enumerate(predictions):
class_idx = tf.argmax(logits).numpy()
p = tf.nn.softmax(logits)[class_idx]
name = class_names[class_idx]
print("Example {} prediction: {} ({:4.1f}%)".format(i, name, 100*p))
Example 0 prediction: Iris setosa (100.0%) Example 1 prediction: Iris versicolor (97.7%) Example 2 prediction: Iris virginica (99.9%)
以上