TensorFlow : コード解説 : 単語のベクタ表現 / Word2Vec
* TensorFlow : Tutorials : 単語のベクタ表現 (翻訳/解説) に、数式は排除/コード重視の方針で詳細な解説を加筆したものです。
TensorFlow & Word2Vec
このチュートリアルでは Mikolov et al による word2vec モデルを眺めます。このモデルは “単語埋め込み (word embeddings)” と呼ばれる、単語のベクタ表現を学習するために使われます。
特に TensorFlow で word2vec モデルを構築するにあたり、興味ある本質的な部分を強調することを意図しています。
- 何故単語をベクタとして表現したいのかという動機を与えることから始めます。
- モデルの背後にある直感と、モデルがどのように訓練されるかを見ます。また TensorFlow のモデルの単純な実装も示します。
- 最後に平凡なバージョンをより良くスケールする方法を見ます。
後でコードを通り抜けますが、直接コードを見ることを好むのであれば、
tensorflow/examples/tutorials/word2vec/word2vec_basic.py の最小限の実装を見てください。
この基本的なサンプルは何某かのデータをダウンロードし、その上で少し訓練して結果を視覚化するに必要なコードを含みます。
この基本版を読んで実行することに馴染んだら、tensorflow/models/embedding/word2vec.py へと進むことができます。これはより実践的な実装で、データをテキストモデルに移すためにどのように効率的にスレッドを使うか、訓練の間にどのようにチェックポイントを作成するか等についての幾つかのより進んだ TensorFlow の基本理念を紹介します。
最初に、単語埋め込みを何故第一に学習するのかを見ていきましょう。
動機 – 何故、単語埋め込みを学習するのか?
画像と音声処理システムはリッチで高次元なデータセットで動作します。物体あるいは音声認識のようなタスクのためにはタスクを成功裏に終わらせるために必要なすべての情報はデータにエンコードされていることを我々は知っています。何故なら人間はこれらのタスクを生データから遂行するからです。

けれども、自然言語処理システムは伝統的に単語を個別の原子的な記号として扱い、従って ‘cat’ は Id537 そして ‘dog’ は Id143 として表現できます。これらのエンコードは恣意(しい)的で、そして個々の記号間に存在するかもしれない関係に関してシステムに有用な情報はもたらしません。
これはモデルが ‘dogs’ についてのデータを処理している時に ‘cats’ について学習したこと(例えば両方とも動物であるとか、四つ足であるとか、ペットであるとか等)の非常に僅(わず)かしか利用できないことを意味しています。
単語を一意な、離散的な ID として表現することはさらにデータの疎性へとつながり、そして通常は統計モデルを成功的に訓練するためには更なるデータが必要であるかもしれないことを意味します。
ベクタ表現を使うことはこれらの障害の幾つかを乗り越えられます。
ベクタ空間モデル (VSM, Vector space models) は連続的なベクタ空間で単語を表します(埋め込みます)。そこでは意味論的に類似の単語が近いポイントにマップされています。(互いに近くに埋め込まれています。)
VSM は NLP において長い豊かな歴史を持ちますが、全てのメソッドは何らかの方法で Distributional Hypothesis(分布仮説) に依存しています。これは 同じ文脈において出現する単語は意味論的な意味を共有する、と主張するものです。
この原理を活用する異なるアプローチは2つのカテゴリーに分割されます: count-based メソッド(例えば潜在的意味解析, Latent Semantic Analysis)と、予測的 (predictive) メソッド(例えば、確率的ニューラル言語モデル, neural probabilistic language models)です。
この違いは Baroni et al. により更にたいへん詳しく説明されていますが、しかし手短に言えば:
- Count-based メソッドは、ある単語が大規模なテキスト・コーパスで隣接語とともにどの程度の頻度で共起するかの統計情報を計算して、そしてこれらの count-統計情報を各単語について小さな、密ベクタにマップします。
- 予測的モデルは、学習した小さな、密な埋め込みベクタ(モデルのパラメータと考えられる)の観点から隣接語から単語を直接的に予測を試みます。
Word2vec は生テキストから単語埋め込みを学習するための特に計算効率的な予測モデルです。それには2つの種類があります、CBOW – 連続 (Continuous) Bag-of-Words モデル と Skip-Gram モデル です。
アルゴリズム的には、これらのモデルは似ています、CBOW がソース文脈単語(’the cat sits on the ‘)からターゲット単語(ex) ‘mat’)を予測する一方で、skip-gram は逆を行ない、ターゲット単語からソース文脈単語を予測するという点を除いてです。
逆は任意の選択のように思われますが、統計的には CBOW は(全体の文脈を一つの観測として扱うことにより)たくさんの分布情報をなだらかする効果があります。多くの場合、これは小さめのデータセットのために有用なことと判明しています。けれども、skip-gram は各文脈ターゲット・ペアを新しい観測として扱い、そしてこれはより大きなデータセットを持つ時に上手くやる傾向があります。
このチュートリアルの残りでは、skip-gram モデルに焦点を当てていきます。
Noise-Contrastive 訓練によるスケールアップ
ニューラル確率的言語モデルは伝統的に、softmax 関数 の観点から前の単語 \(h\) (for "history") が与えられた時に次の単語 \(w_t\) (for "target") の確率を最大化する 最尤 (maximum likelihood (ML)) 原理を使用して訓練されます,
\[
\begin{align}
P(w_t | h) &= \text{softmax}(\text{score}(w_t, h))
\end{align}
\]
ここで \(\text{score}(w\_t, h)\) は単語 \(w\_t\) の文脈 \(h\) との適合性を計算します。
訓練セット上の対数尤度 (log-likelihod) を最大化することで私たちはこのモデルを訓練します。
すなわち、以下を最大化することによります
\[
\begin{align}
J_\text{ML} &= \log P(w_t | h)
\end{align}
\]
これは言語モデリングのための正規化された確率モデルを正しく生み出します。けれどもこれは非常に高コストです、何故なら全ての訓練ステップにおいて、現在の文脈 \(h\) で他の全ての \(V\) 個の単語 \(w'\) のためのスコアを用いて各確率を計算して正規化する必要があるからです。

一方、word2vec における特徴学習のためには、完全な確率モデルは必要ありません。
CBOW と skip-gram モデルは代わりに、同じ文脈で \(k\) 個の想像上の(ノイズ)単語 \(\tilde w\) から実際のターゲット単語を \(w_t\) を識別するために二項分類目的関数(ロジスティック回帰)を使用して訓練されます。
CBOW モデルのために下に図解しました。skip-gram については方向を単に反対にするだけです。

数学的には、目的関数はモデルが高い確率を実際の単語に、低い確率をノイズ単語に割り当てた時に最大化されます。技術的には、これは ネガティブ・サンプリング と呼称され、この損失関数を使用するに良い数学的な動機があります: これが提示する更新は softmax 関数の更新に極限において接近します。しかし計算的にはそれは特別に魅力的です、何故なら損失関数の計算は選択したノイズ単語 (\(k\)) の数にのみ比例して語彙 (\(V\)) の全ての単語ではないからです。これは訓練を非常に速くします。
実際には非常に良く似た noise-contrastive estimation (NCE) 損失を利用します、このために TensorFlow は便利なヘルパー関数 tf.nn.nce_loss() を持っています。
これが実際にどのように動作するのかについて直感的感覚を得てみましょう!
Skip-Gram モデル
例として次のデータセットを考えましょう
the quick brown fox jumped over the lazy dog
最初に単語のデータセットとそれらが現れる文脈を形成します。
どのような方法でも ‘コンテキスト(context, 文脈)’ を定義できるでしょう。実際に統語論的なコンテキスト – 現在のターゲット単語の統語論的な依存性(例えば Levy et al. を参照) – が考察されてきました。ターゲットの左側の単語群 (words-to-the-left of the target,)、ターゲットの右側の単語群、等々。
取り敢えずは普通の定義にこだわることにして、 ‘コンテキスト’ をターゲット単語の左側と右側の単語群の窓 (window of words to the left and to the right of a target word) として定義します。
窓サイズ 1 を使えば、(コンテキスト, ターゲット) ペアのデータセット
([the, brown], quick), ([quick, fox], brown), ([brown, jumped], fox), …
を得ます。
skip-gram はコンテキストとターゲットを逆にして、各コンテキスト単語をそのターゲット単語から予測を試みることを思い出してください。そのため目指すタスクは ‘quick’ から ‘the’ と ‘brown’ を、’brown’ から ‘quick’ と ‘fox’ 等を予測することになります。
従ってデータセットは (入力, 出力) ペアの
(quick, the), (quick, brown), (brown, quick), (brown, fox), …
になります。
目的関数はデータセット全体に渡り定義されますが、典型的にはこれを一度に一つのサンプルを使って(あるいは batch_sizeサンプルの ‘ミニバッチ’、ここで通常は 16 <= batch_size <= 512)、確率的勾配降下 (SGD) で最適化します。
さてこのプロセスの 1 ステップを見てみましょう。
訓練ステップ \(t\) について上の最初の訓練ケースを観測することを想像しましょう。ここでの目的は quick から the を予測することです。
あるノイズ分布、典型的にはユニグラム分布、 \(P(w)\) から引き出すことにより num_noise 個のノイズの(対称)サンプルを選択します。
単純化のために num_noise=1 としてノイズのサンプルとして仮に sheep を選択してみます。次に観測されたサンプルとノイズのサンプルのこのペアのために損失を計算します。ゴールは時間ステップ \(t\) における目的関数を改善する(この場合は、最大化する)ために埋め込み (embedding) パラメータ \(\theta\) を更新することです。埋め込みパラメータ \(\theta\) に関して損失の勾配を導出することによりこれを行ないます。幸いなことに TensorFlow はこれを行なうために簡単なヘルパー関数を提供しています! そして勾配の方向に小さなステップを取ることで埋め込みへの更新を遂行します。
このプロセスが全体の訓練セットに渡って繰り返された時、モデルがノイズ単語から実際の単語を識別することに成功するまで各単語について埋め込みベクタを ‘移動’ する効果を持ちます。
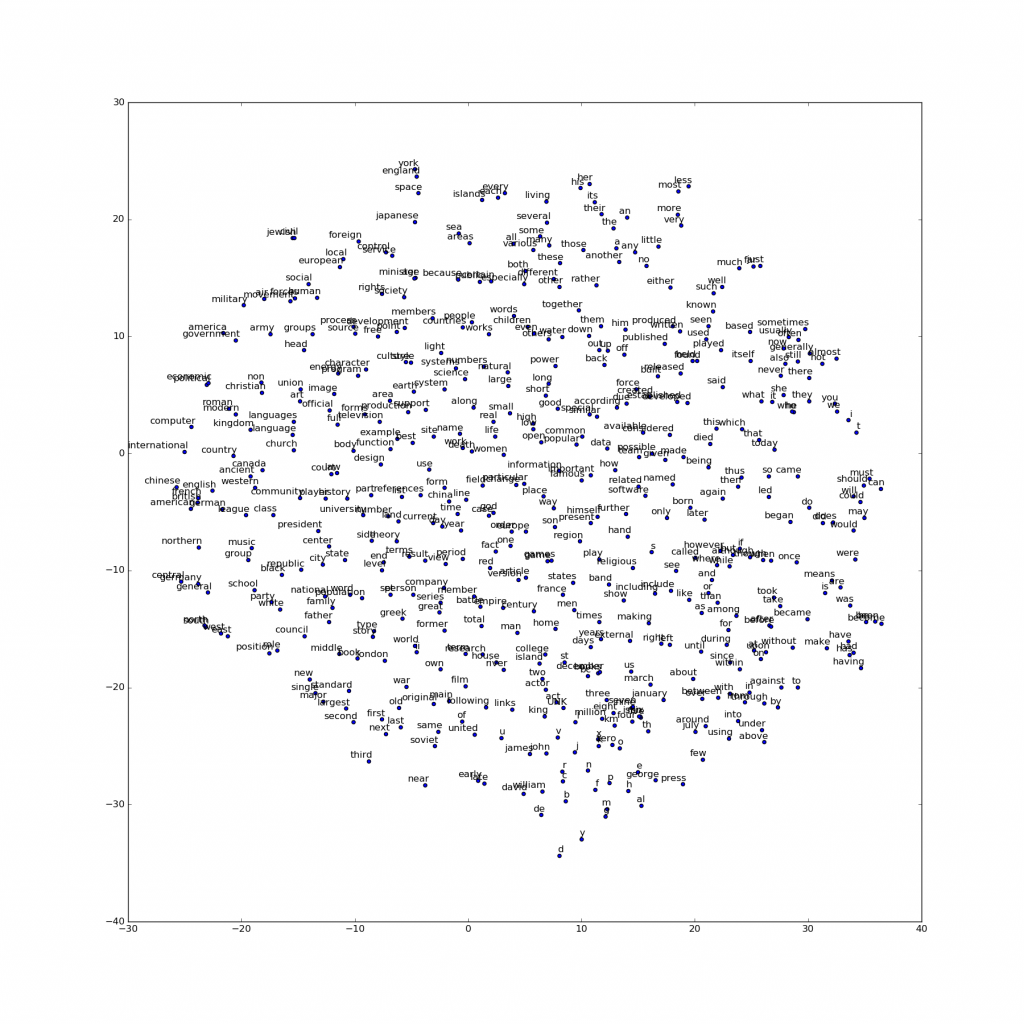
学習したベクタを、例えば t-SNE 次元削減テクニック のようなものを使って2次元に射影することで視覚化できます。これらの視覚化を詳しく調べることで単語とそれの他の単語との関係性についてある一般的な、そして実際にたいへん有用な、意味的な情報をベクタが捕えていることが明らかになります。
例えば下に図解されているように、導かれたベクタ空間のある方向がある意味的な関係、male-female, gender そして country-capital 単語間の関係の方向に特化されていることを最初に発見した時は非常に興味深かったです (例として Mikolov et al., 2013 も見てください)。

これらの図はまた何故これらのベクタが、多くの標準的な NLP 予測タスク、例えば品詞タグ付けや固有表現認識、に対する特徴として有用なのかを説明しています。(例として Collobert et al., 2011 (pdf) によるオリジナル・ワーク、あるいは Turian et al., 2010 によるフォローアップ・ワークを見てください)。
グラフを構築する
理論的な説明はこれまでにして、コードレベルでグラフの構築を見ていきましょう。
以下のグラフ構築のフェーズ以前に単語データベースの構築やバッチの生成は完了しています。
graph = tf.Graph()
with graph.as_default():
# 入力データ。
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
# GPU なしの実装なので、演算と変数を CPU にピン止めしておきます。
with tf.device('/cpu:0'):
# Look up embeddings for inputs.
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
# NCE 損失のための変数を構築。
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
埋め込みについての説明は終えているので、埋め込み行列を定義します。
これは最初は単なる大きなランダム行列で、単位立方体で一様になるように値を初期化します。
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
NCE (noise-contrastive estimation) 損失をロジスティック回帰モデルの観点から定義します。
このため、語彙の各単語のために重み(入力埋め込みへの対比として出力重みとも呼称します)とバイアスを定義する必要あります。それを定義しましょう。
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
然るべき場所にパラメータを持った今、skip-gram モデルグラフを定義できます。
単純化のために、テキスト・コーパスを語彙に既に整数化 (integerized) して各単語は整数として表されることを仮定しましょう。(詳細は tensorflow/examples/tutorials/word2vec/word2vec_basic.py を見てください。)
skip-gram モデルは2つの入力を取ります。一つはソース・コンテキスト単語群を表す整数で満ちたバッチで、他方はターゲット単語群のためです。これらの入力のためにプレースホルダー・ノードを作成しましょう、そうすれば後でデータを供給できます。
# 入力のためのプレースホルダー train_inputs = tf.placeholder(tf.int32, shape=[batch_size]) train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
今私たちが行なう必要があるのはバッチのソース単語の各々のためのベクタを検索する (look up) ことです。TensorFlow はこれを簡単にする便利なヘルパー関数を持ちます。
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
OK、 各単語に対する埋め込みを持った今、noise-contrastive 訓練 objective を使ってターゲット単語を予測してみましょう。
# 各時のネガティブ・ラベルのサンプルを使って NCE 損失を計算します。
loss = tf.reduce_mean(
tf.nn.nce_loss(nce_weights, nce_biases, embed, train_labels,
num_sampled, vocabulary_size))
損失ノードを持った今、勾配を計算してパラメータを更新する等に必要なノードを追加する必要があります。
このため確率的勾配降下を用います、TensorFlow はこれを容易にする便利なヘルパーも持ちます。
# SGD オプティマイザを使用します。 optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0).minimize(loss)
モデルを訓練する
そしてモデルの訓練は簡単で feed_dict を使ってデータをプレースホルダーにプッシュして
ループの中でこの新しいデータで session.run を呼び出すだけです。
with tf.Session(graph=graph) as session:
# We must initialize all variables before we use them.
tf.initialize_all_variables().run()
print("Initialized")
average_loss = 0
for step in xrange(num_steps):
batch_inputs, batch_labels = generate_batch(
batch_size, num_skips, skip_window)
feed_dict = {train_inputs : batch_inputs, train_labels : batch_labels}
# We perform one update step by evaluating the optimizer op (including it
# in the list of returned values for session.run()
_, loss_val = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += loss_val
完全なサンプルコードは tensorflow/examples/tutorials/word2vec/word2vec_basic.py を見てください。
学習した埋め込みを視覚化する
訓練が終了した後、t-SNE を使って学習した埋め込みを視覚化できます。

Et voila! 期待どおり類似の単語はお互いに近くにクラスタリングされる結果になりました。
【参考】 TensorFlow の進んだ特徴の多くを示す、word2vec のより本格的な実装については tensorflow/models/embedding/word2vec.py を見てください。
以下は、翻訳者が実際に実行してみた結果です :
埋め込みを評価する: 類推による推論 (Analogical Reasoning)
埋め込みは NLP の様々な予測タスクに有用です。
本格的な品詞モデルか固有表現モデルの訓練が不足する際、埋め込みを評価する一つの単純な方法は king が queen に対する時 father は何に対する?というような統語的そして意味的関係を予測するためにそれらを直接使用することです。
これは類推による推論 (analogical reasoning) と呼ばれタスクは Mikolov と同僚 により紹介され、そしてデータセットはここからダウンロードできます: https://word2vec.googlecode.com/svn/trunk/questions-words.txt
この評価をどのように行なうかを見るには、tensorflow/models/embedding/word2vec.py における build_eval_graph() と eval() 関数を見てください。
ハイパーパラメータの選択はこのタスクの精度に強く影響します。
このタスクで革新的な性能を達成するためには非常に大規模なデータセット上で訓練し、注意深くハイパーパラメータチューニングしそしてデータのサブサンプリングのようなトリックを使用する必要があります、これはこのチュートリアルの範囲外です。
実装を最適化する
上述の標準的な実装は TensorFlow の柔軟性を見せてくれます。
例えば、訓練目的(関数)の変更は単純で tf.nn.nce_loss() への呼び出しを tf.nn.sampled_softmax_loss() のような既製の他の選択肢に置き換えるだけです。もし損失関数のための新しいアイデアがあるならば、貴方は TensorFlow で新しい目的関数のための式を手作業で書くことができます。そしてその導関数をオプティマイザに計算させることができます。この柔軟性は、様々な異なるアイデアを試みて素早く反復する、機械学習モデル開発の探求フェイズで貴重です。
もし貴方が満足できるモデル構造を一度得たら、より効率的に実行するため(そしてより短時間でより多くのデータをカバーするため)に実装を最適化する価値があるかもしれません。
例えば、このチュートリアルで使用した素朴なコードは妥協した速度を経験するかもしれません、何故なら データ項目を読み供給するために Python を使用しているからです — それらの各々は TensorFlow バックエンドで非常に少ない作業しか必要としません。
もし貴方のモデルが入力データ上深刻なボトルネックがあることを見つけたのであれば、New Data Formats に記述されているように、その問題のために カスタム・データ reader を実装したいかもしれません。
Skip-Gram モデルのケースのためには、 tensorflow/models/embedding/word2vec.py のサンプルとして実際には既にこれを貴方のために行なっています。
もし貴方のモデルがもはや I/O バウンドはなくしかし依然として更なるパフォーマンスを望むのであれば、 新しい Op を追加する に記述されているように、貴方自身の TensorFlow OP を書くことで前に進むことができます。
再度 Skip-Gram ケースのためのこれのサンプル tensorflow/models/embedding/word2vec_optimized.py を提供しています。各々のステージにおけるパフォーマンス改善を計測するためにこれらを互いに対して自由にベンチマークしてみてください。
結論
このチュートリアルで word2vec モデルをカバーしました。
これは単語埋め込みの学習のために計算的に効率的なモデルです。私たちは何故埋め込みが有用であるかを動機付け、効率的な訓練テクニックを議論しそして TensorFlow においてこれら全てをどのように実装するかを示しました。
総括として、早期の実験のために必要な柔軟性とあつられて最適化した実装のために後で必要な制御を TensorFlow がどのように貴方に与えるかの紹介となることを望みます。
以上