TensorFlow ResNet (Deep Residual Learning) で CIFAR-100
CIFAR-10 については TensorFlow のチュートリアル : 畳み込み ニューラルネットワーク で解説されていますが、
CIFAR-100 についてはまだ試していなかったので TensorFlow 実装で試しておくことにします。
モデルとしては Deep Residual Learning(いわゆる ResNet)を利用しました。
これは Microsoft Research Asia (MSRA) が提唱したモデルで ILSVRC 2015 の分類タスクで優勝したモデルです。ゲートがない LSTM であるとの批評もあるようですが、興味深いモデルです。
CIFAR-100
CIFAR-100 のデータセットも CIFAR-10 と同じサイトから取得できます :
CIFAR-10 との違いは、単に 100 種類に分かれているのではなく、20 種類のスーパークラスに分割された上で更に 100 種類のサブクラスに分割されていることです :
| |
参考まで、CIFAR-100 のトレーニング・セットの最初の 25 枚の画像を表示しておきます :

画像が粗いので分かりにくいですが、最初の 10 枚の画像はそれぞれ以下のクラスに属します :
牛, 恐竜, リンゴ, 少年, 観賞魚, 電話, 電車, カップ, 雲, 象
Deep Residual Learning
Deep Residual Learning は Microsoft Research Asia (MSRA) が提唱したモデルで ILSVRC 2015 の分類タスクで優勝したモデルです :
ImageNet Large Scale Visual Recognition Challenge 2015 (ILSVRC2015)
and Results
ペーパーは以下 :
Deep Residual Learning for Image Recognition
K. He, X. Zhang, S. Ren and J. Sun
参考まで、abstract だけ翻訳しておきます :
ニューラルネットワークはより深くなるに従ってトレーニングがより困難になります。ネットワークのトレーニングを容易にすることが可能な residual learning フレームワークを公開します。これは前から使われていたものよりも本質的にはより深くなります。層を、learning unreferenced function の代わりに、learning residual function として明示的に再公式化 (reformulate) します。これらの residual ネットワークが最適化するのがより簡単であり、かなり増やした深さからでも精度を得られることを示す、包括的で実証的な証拠を提供します。ImageNet データセット上で 152 層まで増やした深さで residual ネットを評価します — これは VGG ネットよりも 8 倍深いですが依然として複雑の度合いは低いです。これらの residual ネットのアンサンブルは ImageNet テスト・セット上でエラー率 3.57 % を達成しています。結果は ILSVRC 2015 分類タスクにおいて1位を勝ち取りました。また 100 と 1000 層による CIFAR-10 上の解析も示します。表現の深さは多くのビジュアル認識タスクのために中心的な重要性があります。極めて深い表現のみによって、COCO 物体検知データセット上で 28% の相対的改善を得ました。deep residual ネットは ILSVRC & COCO 2015 コンペへの提示の拠り所で、そこではまた ImageNet 検知、ImageNet localization、COCO 検知、そして COCO セグメンテーションのタスクにおいて1 位を獲得しました。
それから関連記事も紹介しておきますと、ResNet については “ゲートのない LSTM と同等である” という興味深い議論もあります。以下で後者は評価しつつも、批判的なニュアンスもこめられています :
How does deep residual learning work?
Microsoft Wins ImageNet 2015 through Feedforward LSTM without Gates
以下は何故 Residual なのかという説明があります :
この説明は短いので粗く翻訳しておきます :
【質問】
何故 Deep Residual Lerning はそのように呼称されるのでしょう?F(X)=H(X)-X を学習することの本質は何でしょう?
フィッシャー・ベクトル (Fischer vectors) や他の residual テクニックとの関係は?
その関係がそこから名をとってこのテクニックに命名するに十分に本質的なのは何故でしょう?【回答】
深層 Convolutional ネットワークを解析し始めた時、直感に反して、より深いネットワークはより少ないエラーを持つわけではないことを発見しました。事実、追加層は恒等写像であるにもかかわらず、エラーはより浅いネットワークよりも大きいです。これは奇妙なことです、何故なら全ての追加層が恒等層であるならば、ネットワークは少なくとも基となったネットワークと同程度の性能は保持すべきです。この問題は、バッチ正規化で効果的に取り組まれてきた勾配消失問題とは異なっていました。この奇妙な挙動をガイド的な手がかりとして、特徴マッピングを学習するために、residual を学習して元の特徴ベクトルを追加することによりネットワークをトレーニングすることを決めました。こうして、residual が 0 だとしてもネットワークは恒等写像を学習します。residual は H(x) = F(x) – x によって与えられます、ここで x は画像で F(x) は通常ネットワークが学習するマッピング(写像)です。
この大きなアイデアは、もし AlexNet, VGG あるいは GoogLeNet のような成功したネットワークがあれば、そしてそれに更なる多くの層を追加したならば、後の層で基本的な恒等写像を学習することが今や可能になります。その結果、少なくとも元のネットワークと同程度には性能が出ます。この residual 公式化 (formulation) はそれを可能にします。
結果、1000 層以上を持つネットワークをトレーニングすることが今や可能となり、そして追加された深さは認識タスクにおいてより良い性能を提供する役割を果たします。
ResNet の TensorFlow 実装とトレーニング
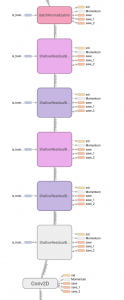 上記の abstract によればオリジナル・モデルは 152 層 – VGG の 8 倍の深さがあるわけですが、TensorFlow による実装は実は簡単です。
上記の abstract によればオリジナル・モデルは 152 層 – VGG の 8 倍の深さがあるわけですが、TensorFlow による実装は実は簡単です。
サンプルを流用することもできますし、各種ビルディング・ブロックも用意されています。但しビルディング・ブロックで構築した場合には右図の TensorBoard によるモデル・グラフ画像のようにブロックが積層されていることしか分かりませんが。
トレーニングは取り敢えず 200 epochs 回してみました。
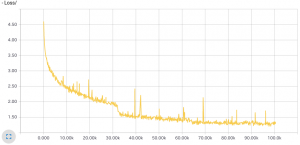
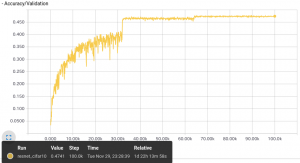
その結果が下図です。左が損失グラフで、右がテストセットに対する精度です。
精度は約 50 % が獲得できています。この数字は必ずしも悪いわけではありません。
CIFAR-100 は決して易しい問題ではなく、公式記録では 76 % 程度が最高で 55 % もあればベスト 30 に入ります。
|  |
以上