TensorFlowOnSpark GetStarted EC2 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
日時 : 02/17/2017
* 本ページは、github TensorFlowOnSpark の GetStarted_EC2 : Running TensorFlowOnSpark on EC2 をベースに実際に実験した上で翻訳して解説を加えたものです :
https://github.com/yahoo/TensorFlowOnSpark/wiki/GetStarted_EC2
EC2 上で TensorFlowOnSpark を実行する
このガイドは 既存の AMI イメージを us-west-2 リージョンで使用して TensorFlowOnSpark を適用するための基本ステップの概要を説明します。
1. standalone Spark クラスタを EC2 上でセットアップ
TFoS AMI で p2.xlarge (1 GPU, 4 vCPUs) 上、 3 スレーブで Spark クラスタを起動するために scripts/spark-ec2 を実行します。TFoS _HOME は TensorFlowOnSpark ソースコードのホームディレクトリを参照することを仮定しています。
* 以下のスクリプトを実行する前に TFoS_HOME の他にも、EC2_KEY(キー名)と EC2_PEM_FILE 変数を設定して export しておきましょう。
export AMI_IMAGE=ami-f6d25596
export EC2_REGION=us-west-2
export EC2_ZONE=us-west-2a
export SPARK_WORKER_INSTANCES=3
export EC2_INSTANCE_TYPE=p2.xlarge
export EC2_MAX_PRICE=0.8
${TFoS_HOME}/scripts/spark-ec2 \
--key-pair=${EC2_KEY} --identity-file=${EC2_PEM_FILE} \
--region=${EC2_REGION} --zone=${EC2_ZONE} \
--ebs-vol-size=50 \
--instance-type=${EC2_INSTANCE_TYPE} \
--master-instance-type=${EC2_INSTANCE_TYPE} \
--ami=${AMI_IMAGE} -s ${SPARK_WORKER_INSTANCES} \
--spot-price ${EC2_MAX_PRICE} \
--copy-aws-credentials \
--hadoop-major-version=yarn --spark-version 1.6.0 \
--no-ganglia \
--user-data ${TFoS_HOME}/scripts/ec2-cloud-config.txt \
launch TFoSdemo
上のスクリプトを実行すると、以下のように直ちにクラスタの構築が開始されます :
Warning: Unrecognized EC2 instance type for instance-type: p2.xlarge Warning: Unrecognized EC2 instance type for master-instance-type: p2.xlarge Setting up security groups... Searching for existing cluster TFoSdemo in region us-west-2... Launching instances... Requesting 3 slaves as spot instances with price $0.800 Waiting for spot instances to be granted... All 3 slaves granted Launched master in us-west-2a, regid = r-0963a9d66d2d84831 Waiting for AWS to propagate instance metadata... Waiting for cluster to enter 'ssh-ready' state....
* p2.xlarge を Unrecognized EC2 instance type とする警告が出ますが、実際には問題なく p2.xlarge インスタンスが起動されました。
* ssh-ready ステート待ちで 5 分ほど時間がかかります。最終的に 10 分ほどで作業が完了しました。
最後に次の例のような行が見られます、これは Spark マスタのホスト名を含みます。
Spark standalone cluster started at http://ec2-52-49-81-151.us-west-2.compute.amazonaws.com:8080 Done!
2. Spark マスタ上への ssh
ssh -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null -i ${EC2_PEM_FILE} root@<SPARK_MASTER_HOST>
実際にログインして OS を確認してみたところ、Ubuntu 16.04.1 LTS が使用されていました :
# cat /etc/os-release NAME="Ubuntu" VERSION="16.04.1 LTS (Xenial Xerus)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 16.04.1 LTS" VERSION_ID="16.04" HOME_URL="http://www.ubuntu.com/" SUPPORT_URL="http://help.ubuntu.com/" BUG_REPORT_URL="http://bugs.launchpad.net/ubuntu/" VERSION_CODENAME=xenial UBUNTU_CODENAME=xenial
3. MNIST ファイルを TensorFlow Record フォーマットに変換する
次の Spark コマンドを、MNIST データファイルを TensorFlow Record フォーマットに変換して HDFS ファイルシステムにストアするために実行します。
* ${TFoS_HOME} は “/root/TensorFlowOnSpark” に設定されています。
pushd ${TFoS_HOME}
spark-submit --master local[4] \
--jars ${TFoS_HOME}/tensorflow-hadoop-1.0-SNAPSHOT.jar \
--conf spark.executorEnv.LD_LIBRARY_PATH="/usr/local/cuda/lib64" \
--driver-library-path="/usr/local/cuda/lib64" \
${TFoS_HOME}/examples/mnist/mnist_data_setup.py \
--output mnist/tfr \
--format tfr
popd
hadoop fs -ls mnist/tfr
3m40.774s で変換完了しました、HDFS 上のファイルを確認しておきましょう :
# hadoop fs -ls mnist/tfr Found 2 items drwxr-xr-x - root supergroup 0 2017-02-16 16:55 mnist/tfr/test drwxr-xr-x - root supergroup 0 2017-02-16 16:54 mnist/tfr/train # hadoop fs -ls mnist/tfr/train Found 11 items -rw-r--r-- 3 root supergroup 0 2017-02-16 16:54 mnist/tfr/train/_SUCCESS -rw-r--r-- 3 root supergroup 4865957 2017-02-16 16:53 mnist/tfr/train/part-r-00000 -rw-r--r-- 3 root supergroup 5853920 2017-02-16 16:53 mnist/tfr/train/part-r-00001 -rw-r--r-- 3 root supergroup 5844694 2017-02-16 16:53 mnist/tfr/train/part-r-00002 -rw-r--r-- 3 root supergroup 5851485 2017-02-16 16:53 mnist/tfr/train/part-r-00003 -rw-r--r-- 3 root supergroup 5844411 2017-02-16 16:54 mnist/tfr/train/part-r-00004 -rw-r--r-- 3 root supergroup 5824177 2017-02-16 16:54 mnist/tfr/train/part-r-00005 -rw-r--r-- 3 root supergroup 5843674 2017-02-16 16:54 mnist/tfr/train/part-r-00006 -rw-r--r-- 3 root supergroup 5835612 2017-02-16 16:54 mnist/tfr/train/part-r-00007 -rw-r--r-- 3 root supergroup 5833012 2017-02-16 16:54 mnist/tfr/train/part-r-00008 -rw-r--r-- 3 root supergroup 5444489 2017-02-16 16:54 mnist/tfr/train/part-r-00009 # hadoop fs -ls mnist/tfr/test Found 11 items -rw-r--r-- 3 root supergroup 0 2017-02-16 16:55 mnist/tfr/test/_SUCCESS -rw-r--r-- 3 root supergroup 944145 2017-02-16 16:55 mnist/tfr/test/part-r-00000 -rw-r--r-- 3 root supergroup 941762 2017-02-16 16:55 mnist/tfr/test/part-r-00001 -rw-r--r-- 3 root supergroup 944395 2017-02-16 16:55 mnist/tfr/test/part-r-00002 -rw-r--r-- 3 root supergroup 944966 2017-02-16 16:55 mnist/tfr/test/part-r-00003 -rw-r--r-- 3 root supergroup 944537 2017-02-16 16:55 mnist/tfr/test/part-r-00004 -rw-r--r-- 3 root supergroup 956450 2017-02-16 16:55 mnist/tfr/test/part-r-00005 -rw-r--r-- 3 root supergroup 961667 2017-02-16 16:55 mnist/tfr/test/part-r-00006 -rw-r--r-- 3 root supergroup 964471 2017-02-16 16:55 mnist/tfr/test/part-r-00007 -rw-r--r-- 3 root supergroup 964857 2017-02-16 16:55 mnist/tfr/test/part-r-00008 -rw-r--r-- 3 root supergroup 955109 2017-02-16 16:55 mnist/tfr/test/part-r-00009
4. MNIST モデルをトレーニングする
HDFS フォルダ /user/root/mnist/tfr/train にある mnist データセットを使用して DNN モデルをトレーニングしてテストします。
pushd ${TFoS_HOME}/src
zip -r ${TFoS_HOME}/tfspark.zip *
popd
#adjust these setting per instance types
#Instance type: p2.8xlarge
#export NUM_GPU=8
#export CORES_PER_WORKER=32
#Instance type: p2.xlarge
export NUM_GPU=1
export CORES_PER_WORKER=4
export SPARK_WORKER_INSTANCES=3
export TOTAL_CORES=$((${CORES_PER_WORKER}*${SPARK_WORKER_INSTANCES}))
export MASTER=spark://$(hostname):7077
spark-submit --master ${MASTER} \
--conf spark.cores.max=${TOTAL_CORES} \
--conf spark.task.cpus=${CORES_PER_WORKER} \
--py-files ${TFoS_HOME}/tfspark.zip,${TFoS_HOME}/examples/mnist/tf/mnist_dist.py \
--conf spark.executorEnv.LD_LIBRARY_PATH="/usr/local/cuda/lib64:$JAVA_HOME/jre/lib/amd64/server:$HADOOP_HOME/lib/native" \
--conf spark.executorEnv.JAVA_HOME="$JAVA_HOME" \
--conf spark.executorEnv.HADOOP_HDFS_HOME=”$HADOOP_HOME” \
--conf spark.executorEnv.CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath --glob) \
--driver-library-path="/usr/local/cuda/lib64" \
${TFoS_HOME}/examples/mnist/tf/mnist_spark.py \
--cluster_size ${SPARK_WORKER_INSTANCES} \
--images mnist/tfr/train --format tfr \
--mode train --model mnist_model --tensorboard
トレーニングされたモデルとそのチェックポイントは HDFS 上に置かれます。
4m22.633s でトレーニングが完了しました。他のクラスタ環境と比較してみないと妥当な数字かは判断つきませんが、チェックポイントは作成されています :
# hadoop fs -ls /user/root/mnist_model Found 17 items -rw-r--r-- 3 root supergroup 265 2017-02-16 17:02 /user/root/mnist_model/checkpoint -rw-r--r-- 3 root supergroup 142712 2017-02-16 17:00 /user/root/mnist_model/graph.pbtxt -rw-r--r-- 3 root supergroup 814164 2017-02-16 17:02 /user/root/mnist_model/model.ckpt-385.data-00000-of-00001 -rw-r--r-- 3 root supergroup 372 2017-02-16 17:02 /user/root/mnist_model/model.ckpt-385.index -rw-r--r-- 3 root supergroup 56854 2017-02-16 17:02 /user/root/mnist_model/model.ckpt-385.meta -rw-r--r-- 3 root supergroup 814164 2017-02-16 17:02 /user/root/mnist_model/model.ckpt-512.data-00000-of-00001 -rw-r--r-- 3 root supergroup 372 2017-02-16 17:02 /user/root/mnist_model/model.ckpt-512.index -rw-r--r-- 3 root supergroup 56854 2017-02-16 17:02 /user/root/mnist_model/model.ckpt-512.meta -rw-r--r-- 3 root supergroup 814164 2017-02-16 17:02 /user/root/mnist_model/model.ckpt-634.data-00000-of-00001 -rw-r--r-- 3 root supergroup 372 2017-02-16 17:02 /user/root/mnist_model/model.ckpt-634.index -rw-r--r-- 3 root supergroup 56854 2017-02-16 17:02 /user/root/mnist_model/model.ckpt-634.meta -rw-r--r-- 3 root supergroup 814164 2017-02-16 17:02 /user/root/mnist_model/model.ckpt-762.data-00000-of-00001 -rw-r--r-- 3 root supergroup 372 2017-02-16 17:02 /user/root/mnist_model/model.ckpt-762.index -rw-r--r-- 3 root supergroup 56854 2017-02-16 17:02 /user/root/mnist_model/model.ckpt-762.meta -rw-r--r-- 3 root supergroup 814164 2017-02-16 17:02 /user/root/mnist_model/model.ckpt-889.data-00000-of-00001 -rw-r--r-- 3 root supergroup 372 2017-02-16 17:02 /user/root/mnist_model/model.ckpt-889.index -rw-r--r-- 3 root supergroup 56854 2017-02-16 17:02 /user/root/mnist_model/model.ckpt-889.meta
Spark の UI ももちろん確認できます :
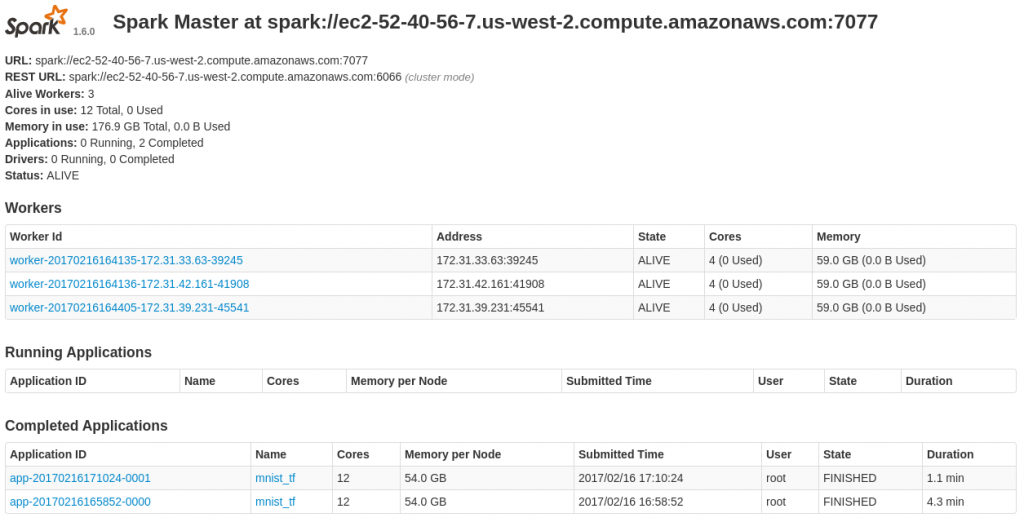
4. MNIST モデルを使用して Image 推論を実行する
次のコマンドを実行するだけです、環境変数はトレーニング時と同じです。
spark-submit --master ${MASTER} \
--conf spark.cores.max=${TOTAL_CORES} \
--conf spark.task.cpus=${CORES_PER_WORKER} \
--py-files ${TFoS_HOME}/tfspark.zip,${TFoS_HOME}/examples/mnist/tf/mnist_dist.py \
--conf spark.executorEnv.LD_LIBRARY_PATH="/usr/local/cuda/lib64:$JAVA_HOME/jre/lib/amd64/server:$HADOOP_HOME/lib/native" \
--conf spark.executorEnv.JAVA_HOME="$JAVA_HOME" \
--conf spark.executorEnv.HADOOP_HDFS_HOME=”$HADOOP_HOME” \
--conf spark.executorEnv.CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath --glob) \
--driver-library-path="/usr/local/cuda/lib64" \
${TFoS_HOME}/examples/mnist/tf/mnist_spark.py \
--cluster_size ${SPARK_WORKER_INSTANCES} \
--images mnist/tfr/test \
--mode inference \
--model mnist_model \
--output predictions
1m10.731s で完了です。
ここで予測結果を吟味できます: 元のラベル vs. 予測です。
# hadoop fs -ls /user/root/predictions/ Found 2 items -rw-r--r-- 3 root supergroup 20000 2017-02-16 17:11 /user/root/predictions/part-00001 -rw-r--r-- 3 root supergroup 20000 2017-02-16 17:11 /user/root/predictions/part-00002 # hadoop fs -cat /user/root/predictions/* | head -n 20 7 7 2 2 1 1 0 0 4 4 1 1 4 4 9 9 5 6 9 9 0 0 6 6 9 9 0 0 1 1 5 5 9 9 7 7 3 3 4 4
5. Jupyter Notebook による対話的な学習
IPython Notebook に必要な追加のソフトウェアをインストールします。
pip install jupyter jupyter[notebook]
マスター・ノードで IPython notebook を起動します。
pushd ${TFoS_HOME}/examples/mnist
PYSPARK_DRIVER_PYTHON="jupyter" \
PYSPARK_DRIVER_PYTHON_OPTS="notebook --no-browser --ip=`hostname`" \
pyspark --master ${MASTER} \
--conf spark.cores.max=${TOTAL_CORES} \
--conf spark.task.cpus=${CORES_PER_WORKER} \
--py-files ${TFoS_HOME}/tfspark.zip,${TFoS_HOME}/examples/mnist/tf/mnist_dist.py \
--conf spark.executorEnv.LD_LIBRARY_PATH="/usr/local/cuda/lib64:$JAVA_HOME/jre/lib/amd64/server:$HADOOP_HOME/lib/native" \
--conf spark.executorEnv.JAVA_HOME="$JAVA_HOME" \
--conf spark.executorEnv.HADOOP_HDFS_HOME=”$HADOOP_HOME” \
--conf spark.executorEnv.CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath --glob) \
--driver-library-path="/usr/local/cuda/lib64"
サンプルノートブックを上の pyspark コマンドで与えられたセキュリティトークンと一緒に起動します :
http://<MASTER_HOST>:8888/notebooks/TFOS_demo.ipynb
以下は実際に接続した Jupyter notebook の画面です。
一応全部のセルを通して実行してみましたが、特に問題なく完了しました。
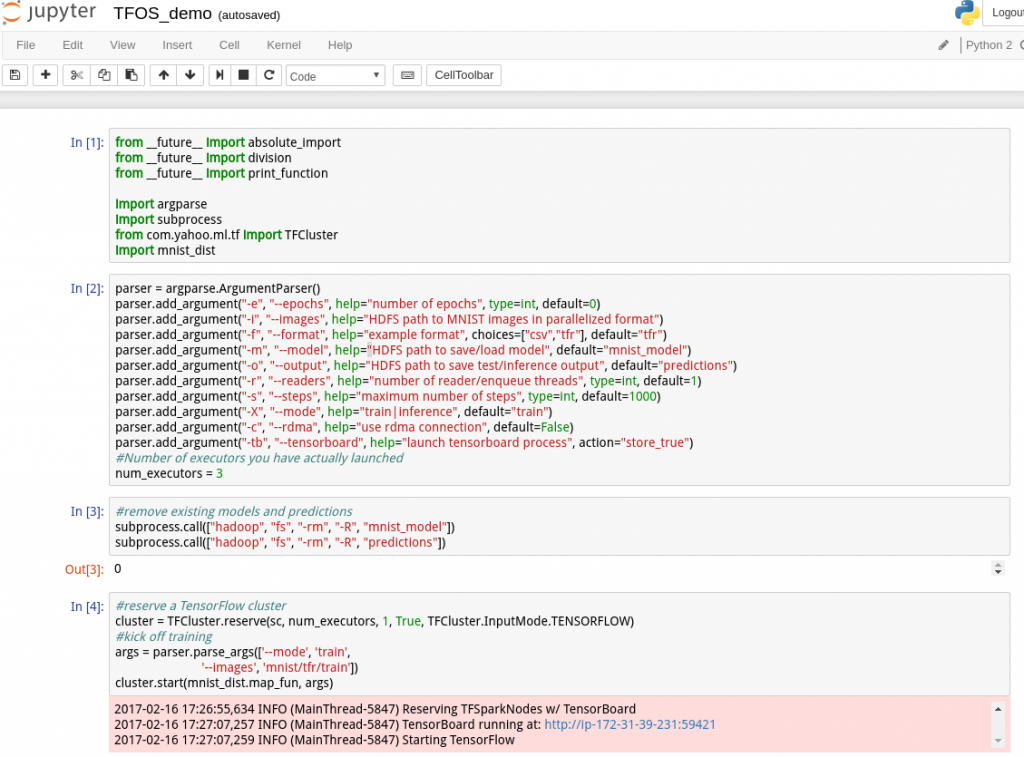
以下は全体画面です :
![]()
6. Spark クラスタを Destroy する
以下のコマンドでクラスタは terminate されます。
${TFoS_HOME}/scripts/spark-ec2 \
--key-pair=${EC2_KEY} --identity-file=${EC2_PEM_FILE} \
--region=${EC2_REGION} --zone=${EC2_ZONE} \
destroy TFoSdemo
以上