TensorFlow 2.0 : 上級 Tutorials : 生成 :- 畳み込み変分オートエンコーダ (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 11/23/2019
* 本ページは、TensorFlow org サイトの TF 2.0 – Advanced Tutorials – Generative の以下のページを翻訳した上で
適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- Windows PC のブラウザからご参加が可能です。スマートデバイスもご利用可能です。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ |
| Facebook: https://www.facebook.com/ClassCatJP/ |
生成 :- 畳み込み変分オートエンコーダ

このノートブックは変分オートエンコーダを訓練することにより手書き数字をどのように生成するかを実演します (1, 2)。
# to generate gifs !pip install -q imageio
TensorFlow と他のライブラリをインポートする
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf import os import time import numpy as np import glob import matplotlib.pyplot as plt import PIL import imageio from IPython import display
MNIST データセットをロードする
各 MNIST 画像は元々は 784 整数ベクトルで、その各々は 0-255 の間でピクセル強度を表します。私達のモデルでは各ピクセルを Bernoulli 分布でモデル化して、データセットを統計的に二値化します。
(train_images, _), (test_images, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
test_images = test_images.reshape(test_images.shape[0], 28, 28, 1).astype('float32')
# Normalizing the images to the range of [0., 1.]
train_images /= 255.
test_images /= 255.
# Binarization
train_images[train_images >= .5] = 1.
train_images[train_images < .5] = 0.
test_images[test_images >= .5] = 1.
test_images[test_images < .5] = 0.
TRAIN_BUF = 60000 BATCH_SIZE = 100 TEST_BUF = 10000
バッチを作成してデータセットをシャッフルするために tf.data を使用する
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(TRAIN_BUF).batch(BATCH_SIZE) test_dataset = tf.data.Dataset.from_tensor_slices(test_images).shuffle(TEST_BUF).batch(BATCH_SIZE)
生成と推論ネットワークを tf.keras.Sequential で配線する (= wire up)
私達の VAE サンプルでは、生成と推論ネットワークのために 2 つの小さな ConvNet を使用します。これらのニューラルネットは小さいので、コードを単純化するために tf.keras.Sequential を使用します。以下の記述において $x$ と $z$ をそれぞれ観測と潜在 (= latent) 変数を示すものとします。
生成ネットワーク (= Generative Network)
これは生成モデルを定義します、これは入力として潜在エンコーディングを取り、観測の条件付き分布, i.e. $p(x|z)$ のためのパラメータを出力します。更に、潜在変数のために単位ガウス事前分布 $p(z)$ を使用します。
推論ネットワーク
これは近似事後分布 $q(z|x)$ を定義します、これは入力として観測を取り潜在表現の条件付き分布のためのパラメータのセットを出力します。この例では、この分布を単純に対角ガウス分布 (= diagonal Gaussian) としてモデル化します。この場合、推論ネットワークは factorized Gaussian の平均 (= mean) と対数分散 (= log-variance) パラメータを出力します (分散の代わりの対数分散は直接的には数値的安定性のためです)。
再パラメータ化 (= Reparameterization) トリック
最適化の間、最初に単位ガウス分布からサンプリングすることにより $q(z|x)$ からサンプリングできて、それから標準偏差を乗じて平均を加えます。これは勾配がサンプルを通して推論ネットワーク・パラメータに渡せることを確かなものにします。
ネットワーク・アーキテクチャ
推論ネットワークのために、2 つの畳み込み層とそれに続く完全結合層を使用します。生成ネットワークでは、完全結合層と続く 3 つの convolution transpose 層を使用してこのアーキテクチャを反映 (= mirror) します (a.k.a. あるコンテキストでは deconvolutional 層)。注意してください、VAE を訓練するときバッチ正規化の使用を回避することは一般的な実践です、何故ならばミニバッチを使用することによる追加的な偶然性はサンプリングからの偶然性の上に不安定性を悪化させるかもしれないためです。
class CVAE(tf.keras.Model):
def __init__(self, latent_dim):
super(CVAE, self).__init__()
self.latent_dim = latent_dim
self.inference_net = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(
filters=32, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Conv2D(
filters=64, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Flatten(),
# No activation
tf.keras.layers.Dense(latent_dim + latent_dim),
]
)
self.generative_net = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(latent_dim,)),
tf.keras.layers.Dense(units=7*7*32, activation=tf.nn.relu),
tf.keras.layers.Reshape(target_shape=(7, 7, 32)),
tf.keras.layers.Conv2DTranspose(
filters=64,
kernel_size=3,
strides=(2, 2),
padding="SAME",
activation='relu'),
tf.keras.layers.Conv2DTranspose(
filters=32,
kernel_size=3,
strides=(2, 2),
padding="SAME",
activation='relu'),
# No activation
tf.keras.layers.Conv2DTranspose(
filters=1, kernel_size=3, strides=(1, 1), padding="SAME"),
]
)
@tf.function
def sample(self, eps=None):
if eps is None:
eps = tf.random.normal(shape=(100, self.latent_dim))
return self.decode(eps, apply_sigmoid=True)
def encode(self, x):
mean, logvar = tf.split(self.inference_net(x), num_or_size_splits=2, axis=1)
return mean, logvar
def reparameterize(self, mean, logvar):
eps = tf.random.normal(shape=mean.shape)
return eps * tf.exp(logvar * .5) + mean
def decode(self, z, apply_sigmoid=False):
logits = self.generative_net(z)
if apply_sigmoid:
probs = tf.sigmoid(logits)
return probs
return logits
損失関数と optimizer を定義する
VAE は周辺対数尤度上のエビデンス下限 (ELBO, evidence lower bound) を最大化することにより訓練されます :
$$\log p(x) \ge \text{ELBO} = \mathbb{E}_{q(z|x)}\left[\log \frac{p(x, z)}{q(z|x)}\right].$$
実際に、この期待値の単一サンプル・モンテカルロ推定を最適化します :
$$\log p(x| z) + \log p(z) - \log q(z|x),$$
ここで $z$ は $q(z|x)$ からサンプリングされます。
Note: 私達はまた KL 項を解析的に計算することもできますが、ここでは単純化のために総ての 3 つの項をモンテカルロ estimator に組み入れます。
optimizer = tf.keras.optimizers.Adam(1e-4)
def log_normal_pdf(sample, mean, logvar, raxis=1):
log2pi = tf.math.log(2. * np.pi)
return tf.reduce_sum(
-.5 * ((sample - mean) ** 2. * tf.exp(-logvar) + logvar + log2pi),
axis=raxis)
@tf.function
def compute_loss(model, x):
mean, logvar = model.encode(x)
z = model.reparameterize(mean, logvar)
x_logit = model.decode(z)
cross_ent = tf.nn.sigmoid_cross_entropy_with_logits(logits=x_logit, labels=x)
logpx_z = -tf.reduce_sum(cross_ent, axis=[1, 2, 3])
logpz = log_normal_pdf(z, 0., 0.)
logqz_x = log_normal_pdf(z, mean, logvar)
return -tf.reduce_mean(logpx_z + logpz - logqz_x)
@tf.function
def compute_apply_gradients(model, x, optimizer):
with tf.GradientTape() as tape:
loss = compute_loss(model, x)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
訓練
- データセットに渡り反復することから始めます。
- 各反復の間、近似事後分布 $q(z|x)$ の平均と対数分散パラメータのセットを得るために画像をエンコーダに渡します。
- それから $q(z|x)$ からサンプリングするために再パラメータ化トリックを適用します。
- 最後に、生成分布 $p(x|z)$ のロジットを得るために再パラメータ化されたサンプルをデコーダに渡します。
- Note: 訓練セットの 60k データポイントとテストセットの 10k データポイント持つ、keras によりロードされたデータセットを使用しますので、テストセット上の結果としての ELBO は (Larochelle の MNIST の動的二値化 (= dynamic binarization) を使用している) 文献で報告されている結果よりも僅かにより高いです。
画像を生成する
- 訓練の後、幾つかの画像を生成する時です。
- 単位ガウス事前分布 $p(z)$ から潜在ベクトルのセットをサンプリングすることから始めます。
- それから generator は潜在サンプル $z$ を観測のロジットに変換し、分布 $p(x|z)$ を与えます。
- ここで Bernoulli 分布の確率をプロットします。
epochs = 100
latent_dim = 50
num_examples_to_generate = 16
# keeping the random vector constant for generation (prediction) so
# it will be easier to see the improvement.
random_vector_for_generation = tf.random.normal(
shape=[num_examples_to_generate, latent_dim])
model = CVAE(latent_dim)
def generate_and_save_images(model, epoch, test_input):
predictions = model.sample(test_input)
fig = plt.figure(figsize=(4,4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0], cmap='gray')
plt.axis('off')
# tight_layout minimizes the overlap between 2 sub-plots
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
generate_and_save_images(model, 0, random_vector_for_generation)
for epoch in range(1, epochs + 1):
start_time = time.time()
for train_x in train_dataset:
compute_apply_gradients(model, train_x, optimizer)
end_time = time.time()
if epoch % 1 == 0:
loss = tf.keras.metrics.Mean()
for test_x in test_dataset:
loss(compute_loss(model, test_x))
elbo = -loss.result()
display.clear_output(wait=False)
print('Epoch: {}, Test set ELBO: {}, '
'time elapse for current epoch {}'.format(epoch,
elbo,
end_time - start_time))
generate_and_save_images(
model, epoch, random_vector_for_generation)
Epoch: 100, Test set ELBO: -78.4385757446289, time elapse for current epoch 2.0967400074005127
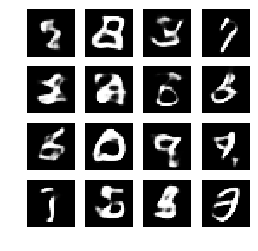
エポック数を使用して画像を表示する
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
plt.imshow(display_image(epochs))
plt.axis('off')# Display images
(-0.5, 287.5, 287.5, -0.5)

総てのセーブされた画像の GIF を生成する
anim_file = 'cvae.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
last = -1
for i,filename in enumerate(filenames):
frame = 2*(i**0.5)
if round(frame) > round(last):
last = frame
else:
continue
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
import IPython
if IPython.version_info >= (6,2,0,''):
display.Image(filename=anim_file)
Colab で作業している場合には下のコードでアニメーションをダウンロードできます :
try: from google.colab import files except ImportError: pass else: files.download(anim_file)
以上