Keras 2 : examples : コンピュータビジョン – スクラッチから画像分類 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 10/30/2021 (keras 2.6.0)
* 本ページは、Keras の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
- Code examples : Computer Vision : Image classification from scratch (Author: fchollet)
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- テレワーク & オンライン授業を支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- ウェビナー運用には弊社製品「ClassCat® Webinar」を利用しています。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ ; Facebook |

Keras 2 : examples : コンピュータビジョン – スクラッチから画像分類
イントロダクション
このサンプルは、事前訓練済みの重みや事前作成済みの Keras アプリケーションモデルを活用することなしに、ディスク上の JPEG 画像から始めて、スクラッチから画像分類を行なう方法を示します。Kaggle の猫 vs 犬の二値分類データセット上のワークフローを実演します。
データセットを生成するために image_dataset_from_directory ユティリティを使用します、そして画像標準化とデータ増強のために Keras 画像前処理層を使用します。
セットアップ
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
データをロードする : 猫 vs 犬 データセット
Raw データ・ダウンロード
最初に、raw データの 786 ZIP アーカイブをダウンロードしましょう :
!curl -O https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_3367a.zip
!unzip -q kagglecatsanddogs_3367a.zip
!ls
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 786M 100 786M 0 0 44.4M 0 0:00:17 0:00:17 --:--:-- 49.6M
image_classification_from_scratch.ipynb MSR-LA - 3467.docx readme[1].txt
kagglecatsanddogs_3367a.zip PetImages
今は PetImages フォルダを持ちます、これは 2 つのサブフォルダ, Cat と Dog を含みます。各サブフォルダは各カテゴリーの画像ファイルを含みます。
!ls PetImages
Cat Dog
!ls PetImages/Cat | wc -l
!ls PetImages/Dog | wc -l
12502 12502
破損した画像のフィルタリング
多くの現実世界の画像データで作業するとき、破損した画像は一般的に発生します。ヘッダに文字列 “JFIF” を含まない、上手くエンコードできない画像をフィルタしましょう。
import os
num_skipped = 0
for folder_name in ("Cat", "Dog"):
folder_path = os.path.join("PetImages", folder_name)
for fname in os.listdir(folder_path):
fpath = os.path.join(folder_path, fname)
try:
fobj = open(fpath, "rb")
is_jfif = tf.compat.as_bytes("JFIF") in fobj.peek(10)
finally:
fobj.close()
if not is_jfif:
num_skipped += 1
# Delete corrupted image
os.remove(fpath)
print("Deleted %d images" % num_skipped)
Deleted 1590 images
!ls PetImages/Cat | wc -l
!ls PetImages/Dog | wc -l
11742 11670
データセットの生成
image_size = (180, 180)
batch_size = 32
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
"PetImages",
validation_split=0.2,
subset="training",
seed=1337,
image_size=image_size,
batch_size=batch_size,
)
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
"PetImages",
validation_split=0.2,
subset="validation",
seed=1337,
image_size=image_size,
batch_size=batch_size,
)
Found 23410 files belonging to 2 classes. Using 18728 files for training. Found 23410 files belonging to 2 classes. Using 4682 files for validation.
データの可視化
ここに訓練データセットの最初の 9 画像があります。ご覧のように、ラベル 1 は “dog” でラベル 0 は “cat” です。
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(int(labels[i]))
plt.axis("off")
画像データ増強を使用する
大規模な画像データセットを持たないとき、ランダム水平反転や小さなランダム回転のような、訓練画像にランダムなしかし現実的な変換を適用してサンプルの多様性を人工的に導入することは良い実践です。これは overfitting のペースを落としながら、モデルを訓練データの様々な様相に晒す役に立ちます。
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
]
)
データセットの最初の画像に data_augmentation を繰り返し適用して、増強されたサンプルがどのように見えるか可視化しましょう :
plt.figure(figsize=(10, 10))
for images, _ in train_ds.take(1):
for i in range(9):
augmented_images = data_augmentation(images)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype("uint8"))
plt.axis("off")

データの標準化
画像は既に標準サイズ (180×180) にあります、それらはデータセットにより連続的な float32 バッチとして生成されているからです。けれども、RGB チャネル値は [0, 255] 範囲内にあります。これはニューラルネットワークのためには理想的ではありません ; 一般に入力値を小さくするように努めるべきです。ここでは、モデルの最初に Rescaling 層を使用して値を [0, 1] 内になるように標準化します。
データを前処理するための 2 つのオプション
data_augmentation preprocessor を使用できる 2 つの方法があります :
オプション 1 : このように、それをモデルの一部にします :
inputs = keras.Input(shape=input_shape)
x = data_augmentation(inputs)
x = layers.Rescaling(1./255)(x)
... # Rest of the model
このオプションでは、データ増強はモデル実行の残りと同期的にデバイス上で発生します、つまりそれは GPU 高速化から恩恵を受けます。
データ増強はテスト時には無効であることに注意してください、従って入力サンプルは、evaluate() や predict() を呼び出すときではなく、fit() の間だけ増強されます。
GPU 上で訓練している場合、これはより良い選択肢です。
オプション 2 : 増強された画像のバッチを生成するデータセットを取得するように、このように、それをデータセットに適用します
augmented_train_ds = train_ds.map(
lambda x, y: (data_augmentation(x, training=True), y))
このオプションでは、データ増強は CPU 上で 非同期的に発生します、そしてモデルに入る前にバッファリングされます。
CPU 上で訓練している場合、これはより良い選択肢です、何故ならばデータ増強を非同期に非ブロッキングに行なうからです。
私達のケースでは、最初のオプションで進みます。
パフォーマンスのためにデータセットを configure する
バッファリングされた先取りを確実に使用しましょう、I/O がブロックされることなくデータをディスクから yield できます :
train_ds = train_ds.prefetch(buffer_size=32)
val_ds = val_ds.prefetch(buffer_size=32)
モデルを構築する
Xception ネットワークの小さいバージョンを構築します。アーキテクチャの最適化を特に試してはいません ; 最善のモデル configuration のためにシステマティックな探索を行ないたい場合は、KerasTuner の使用を考えてください。
以下に注意してください :
- モデルは data_augmentation preprocessor で始めて、Rescaling 層が続きます。
- 最後の分類層の前に Dropout 層を含めます。
def make_model(input_shape, num_classes):
inputs = keras.Input(shape=input_shape)
# Image augmentation block
x = data_augmentation(inputs)
# Entry block
x = layers.Rescaling(1.0 / 255)(x)
x = layers.Conv2D(32, 3, strides=2, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.Conv2D(64, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
previous_block_activation = x # Set aside residual
for size in [128, 256, 512, 728]:
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.SeparableConv2D(size, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.MaxPooling2D(3, strides=2, padding="same")(x)
# Project residual
residual = layers.Conv2D(size, 1, strides=2, padding="same")(
previous_block_activation
)
x = layers.add([x, residual]) # Add back residual
previous_block_activation = x # Set aside next residual
x = layers.SeparableConv2D(1024, 3, padding="same")(x)
x = layers.BatchNormalization()(x)
x = layers.Activation("relu")(x)
x = layers.GlobalAveragePooling2D()(x)
if num_classes == 2:
activation = "sigmoid"
units = 1
else:
activation = "softmax"
units = num_classes
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(units, activation=activation)(x)
return keras.Model(inputs, outputs)
model = make_model(input_shape=image_size + (3,), num_classes=2)
keras.utils.plot_model(model, show_shapes=True)
('Failed to import pydot. You must `pip install pydot` and install graphviz (https://graphviz.gitlab.io/download/), ', 'for `pydotprint` to work.')
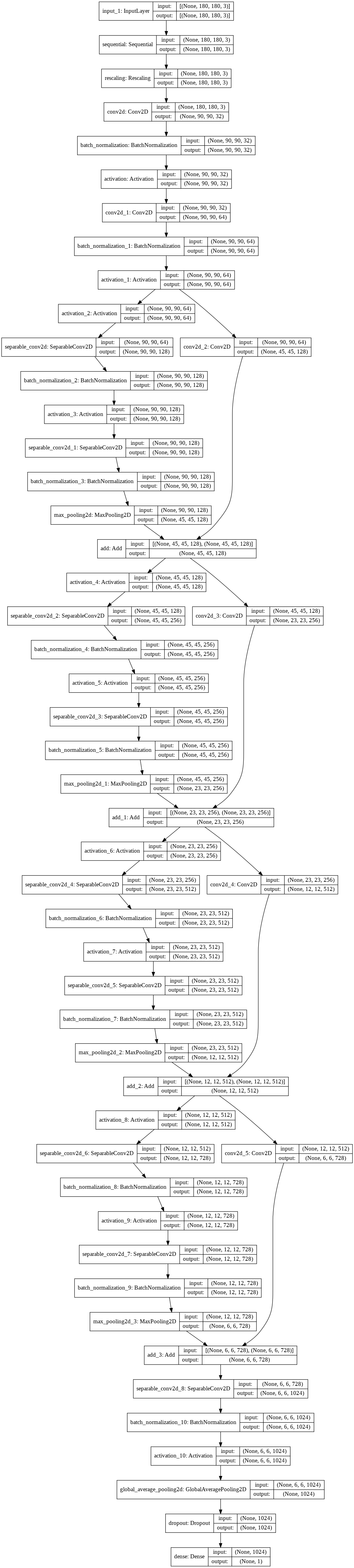
モデルを訓練する
epochs = 50
callbacks = [
keras.callbacks.ModelCheckpoint("save_at_{epoch}.h5"),
]
model.compile(
optimizer=keras.optimizers.Adam(1e-3),
loss="binary_crossentropy",
metrics=["accuracy"],
)
model.fit(
train_ds, epochs=epochs, callbacks=callbacks, validation_data=val_ds,
)
Epoch 1/50 586/586 [==============================] - 81s 139ms/step - loss: 0.6233 - accuracy: 0.6700 - val_loss: 0.7698 - val_accuracy: 0.6117 Epoch 2/50 586/586 [==============================] - 80s 137ms/step - loss: 0.4638 - accuracy: 0.7840 - val_loss: 0.4056 - val_accuracy: 0.8178 Epoch 3/50 586/586 [==============================] - 80s 137ms/step - loss: 0.3652 - accuracy: 0.8405 - val_loss: 0.3535 - val_accuracy: 0.8528 Epoch 4/50 586/586 [==============================] - 80s 137ms/step - loss: 0.3112 - accuracy: 0.8675 - val_loss: 0.2673 - val_accuracy: 0.8894 Epoch 5/50 586/586 [==============================] - 80s 137ms/step - loss: 0.2585 - accuracy: 0.8928 - val_loss: 0.6213 - val_accuracy: 0.7294 Epoch 6/50 586/586 [==============================] - 81s 138ms/step - loss: 0.2218 - accuracy: 0.9071 - val_loss: 0.2377 - val_accuracy: 0.8930 Epoch 7/50 586/586 [==============================] - 80s 137ms/step - loss: 0.1992 - accuracy: 0.9169 - val_loss: 1.1273 - val_accuracy: 0.6254 Epoch 8/50 586/586 [==============================] - 80s 137ms/step - loss: 0.1820 - accuracy: 0.9243 - val_loss: 0.1955 - val_accuracy: 0.9173 Epoch 9/50 586/586 [==============================] - 80s 137ms/step - loss: 0.1694 - accuracy: 0.9308 - val_loss: 0.1602 - val_accuracy: 0.9314 Epoch 10/50 586/586 [==============================] - 80s 137ms/step - loss: 0.1623 - accuracy: 0.9333 - val_loss: 0.1777 - val_accuracy: 0.9248 Epoch 11/50 586/586 [==============================] - 80s 137ms/step - loss: 0.1522 - accuracy: 0.9365 - val_loss: 0.1562 - val_accuracy: 0.9400 Epoch 12/50 586/586 [==============================] - 80s 137ms/step - loss: 0.1458 - accuracy: 0.9417 - val_loss: 0.1529 - val_accuracy: 0.9338 Epoch 13/50 586/586 [==============================] - 80s 137ms/step - loss: 0.1368 - accuracy: 0.9433 - val_loss: 0.1694 - val_accuracy: 0.9259 Epoch 14/50 586/586 [==============================] - 80s 137ms/step - loss: 0.1301 - accuracy: 0.9461 - val_loss: 0.1250 - val_accuracy: 0.9530 Epoch 15/50 586/586 [==============================] - 80s 137ms/step - loss: 0.1261 - accuracy: 0.9483 - val_loss: 0.1548 - val_accuracy: 0.9353 Epoch 16/50 586/586 [==============================] - 81s 137ms/step - loss: 0.1241 - accuracy: 0.9497 - val_loss: 0.1376 - val_accuracy: 0.9464 Epoch 17/50 586/586 [==============================] - 80s 137ms/step - loss: 0.1193 - accuracy: 0.9535 - val_loss: 0.1093 - val_accuracy: 0.9575 Epoch 18/50 586/586 [==============================] - 80s 137ms/step - loss: 0.1107 - accuracy: 0.9558 - val_loss: 0.1488 - val_accuracy: 0.9432 Epoch 19/50 586/586 [==============================] - 80s 137ms/step - loss: 0.1175 - accuracy: 0.9532 - val_loss: 0.1380 - val_accuracy: 0.9421 Epoch 20/50 586/586 [==============================] - 81s 138ms/step - loss: 0.1026 - accuracy: 0.9584 - val_loss: 0.1293 - val_accuracy: 0.9485 Epoch 21/50 586/586 [==============================] - 80s 137ms/step - loss: 0.0977 - accuracy: 0.9606 - val_loss: 0.1105 - val_accuracy: 0.9573 Epoch 22/50 586/586 [==============================] - 80s 137ms/step - loss: 0.0983 - accuracy: 0.9610 - val_loss: 0.1023 - val_accuracy: 0.9633 Epoch 23/50 586/586 [==============================] - 80s 137ms/step - loss: 0.0776 - accuracy: 0.9694 - val_loss: 0.1176 - val_accuracy: 0.9530 Epoch 38/50 586/586 [==============================] - 80s 136ms/step - loss: 0.0596 - accuracy: 0.9768 - val_loss: 0.0967 - val_accuracy: 0.9633 Epoch 44/50 586/586 [==============================] - 80s 136ms/step - loss: 0.0504 - accuracy: 0.9792 - val_loss: 0.0984 - val_accuracy: 0.9663 Epoch 50/50 586/586 [==============================] - 80s 137ms/step - loss: 0.0486 - accuracy: 0.9817 - val_loss: 0.1157 - val_accuracy: 0.9609 <tensorflow.python.keras.callbacks.History at 0x7f1694135320>
完全なデータセット上で 50 エポック訓練した後、~96% 検証精度に到達しています。
新しいデータで推論を実行する
データ増強と dropout は推論時には無効であることに注意してください。
img = keras.preprocessing.image.load_img(
"PetImages/Cat/6779.jpg", target_size=image_size
)
img_array = keras.preprocessing.image.img_to_array(img)
img_array = tf.expand_dims(img_array, 0) # Create batch axis
predictions = model.predict(img_array)
score = predictions[0]
print(
"This image is %.2f percent cat and %.2f percent dog."
% (100 * (1 - score), 100 * score)
)
This image is 84.34 percent cat and 15.66 percent dog.
以上