Keras 2 : examples : 時系列 – 天気予報のための時系列予測 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 06/24/2022 (keras 2.9.0)
* 本ページは、Keras の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
- Code examples : Timeseries : Timeseries forecasting for weather prediction (Author: Prabhanshu Attri, Yashika Sharma, Kristi Takach, Falak Shah)
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP

Keras 2 : examples : 時系列 – 天気予報のための時系列予測
Description : このノートブックは LSTM モデルを使用して時系列予測を行なう方法を実演します。
セットアップ
This example requires TensorFlow 2.3 or higher.
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
気候データ時系列
Max Planck Institute for Biogeochemistry (生物地球化学) により記録された Jena 気候データセットを使用していきます。データセットは、気温、気圧、湿度 等のような 14 の特徴で構成され、10 分毎に一度記録されています。
場所 : Weather Station, Max Planck Institute for Biogeochemistry in Jena, Germany
考慮された時間枠 : Jan 10, 2009 – December 31, 2016
下のテーブルはカラム名、それらの値形式、そしてそれらの説明を示します。

from zipfile import ZipFile
import os
uri = "https://storage.googleapis.com/tensorflow/tf-keras-datasets/jena_climate_2009_2016.csv.zip"
zip_path = keras.utils.get_file(origin=uri, fname="jena_climate_2009_2016.csv.zip")
zip_file = ZipFile(zip_path)
zip_file.extractall()
csv_path = "jena_climate_2009_2016.csv"
df = pd.read_csv(csv_path)
Raw データの可視化
作業しているデータの感覚を得るために、各特徴は下でプロットされます。これは 2009 から 2016 年の期間に渡る各特徴の明白なパターンを示します。それはまた、正規化の際に対処される、異常がどこに存在するかも示します。
titles = [
"Pressure",
"Temperature",
"Temperature in Kelvin",
"Temperature (dew point)",
"Relative Humidity",
"Saturation vapor pressure",
"Vapor pressure",
"Vapor pressure deficit",
"Specific humidity",
"Water vapor concentration",
"Airtight",
"Wind speed",
"Maximum wind speed",
"Wind direction in degrees",
]
feature_keys = [
"p (mbar)",
"T (degC)",
"Tpot (K)",
"Tdew (degC)",
"rh (%)",
"VPmax (mbar)",
"VPact (mbar)",
"VPdef (mbar)",
"sh (g/kg)",
"H2OC (mmol/mol)",
"rho (g/m**3)",
"wv (m/s)",
"max. wv (m/s)",
"wd (deg)",
]
colors = [
"blue",
"orange",
"green",
"red",
"purple",
"brown",
"pink",
"gray",
"olive",
"cyan",
]
date_time_key = "Date Time"
def show_raw_visualization(data):
time_data = data[date_time_key]
fig, axes = plt.subplots(
nrows=7, ncols=2, figsize=(15, 20), dpi=80, facecolor="w", edgecolor="k"
)
for i in range(len(feature_keys)):
key = feature_keys[i]
c = colors[i % (len(colors))]
t_data = data[key]
t_data.index = time_data
t_data.head()
ax = t_data.plot(
ax=axes[i // 2, i % 2],
color=c,
title="{} - {}".format(titles[i], key),
rot=25,
)
ax.legend([titles[i]])
plt.tight_layout()
show_raw_visualization(df)
このヒートマップは異なる特徴間の相関性を示しています。
def show_heatmap(data):
plt.matshow(data.corr())
plt.xticks(range(data.shape[1]), data.columns, fontsize=14, rotation=90)
plt.gca().xaxis.tick_bottom()
plt.yticks(range(data.shape[1]), data.columns, fontsize=14)
cb = plt.colorbar()
cb.ax.tick_params(labelsize=14)
plt.title("Feature Correlation Heatmap", fontsize=14)
plt.show()
show_heatmap(df)

データ前処理
ここでは訓練のために ~300,000 データポイントを選択しています。観測は 10 分毎に記録されています、つまり 1 時間毎に 6 回です。1 時間毎に 1 ポイントをリサンプリングします、60 分内には劇的な変化は想定されないからです。timeseries_dataset_from_array ユティリティの sampling_rate 引数によってこれを行います。
過去の 720 タイムスタンプ (720/6=12 時間) からのデータを追跡しています。このデータは、72 タイムスタンプ (72/6=12 hours) 後の気温を予測するために使用されます。
総ての特徴は様々な範囲の値を持ちますので、ニューラルネットワークを訓練する前に、特徴値を [0, 1] の範囲に閉じ込めるために正規化を行います。各特徴の平均を減算して標準偏差で除算することでこれを行います。
モデルを訓練するためにデータの 71.5 % i.e. 300,693 行が使用されます。この割合を変更するために split_fraction が変更できます。
モデルには最初の 5 日間 i.e. 720 観測データが示されます。72 (12 時間 * 6 観測 per 時間) 観測後の気温がラベルとして使用されます。
split_fraction = 0.715
train_split = int(split_fraction * int(df.shape[0]))
step = 6
past = 720
future = 72
learning_rate = 0.001
batch_size = 256
epochs = 10
def normalize(data, train_split):
data_mean = data[:train_split].mean(axis=0)
data_std = data[:train_split].std(axis=0)
return (data - data_mean) / data_std
相関ヒートマップから分かるように、Relative Humidity と Specific Humidity のような幾つかのパラメータは冗長です。そのため、総てではなく、選択された特徴を使用していきます。
print(
"The selected parameters are:",
", ".join([titles[i] for i in [0, 1, 5, 7, 8, 10, 11]]),
)
selected_features = [feature_keys[i] for i in [0, 1, 5, 7, 8, 10, 11]]
features = df[selected_features]
features.index = df[date_time_key]
features.head()
features = normalize(features.values, train_split)
features = pd.DataFrame(features)
features.head()
train_data = features.loc[0 : train_split - 1]
val_data = features.loc[train_split:]
The selected parameters are: Pressure, Temperature, Saturation vapor pressure, Vapor pressure deficit, Specific humidity, Airtight, Wind speed
訓練データセット
訓練データセット・ラベルは 792nd 観測値 (720 + 72) から始まります。
start = past + future
end = start + train_split
x_train = train_data[[i for i in range(7)]].values
y_train = features.iloc[start:end][[1]]
sequence_length = int(past / step)
timeseries_dataset_from_array 関数は、等間隔で集められたデータポイントのシークエンスを、シークエンス/ウィンドウの長さ、2 つのシークエンス/ウィンドウ間の間隔のような時系列パラメータと共に取り、主時系列からサンプリングされたサブ時系列の入力とターゲットのバッチを生成します。
dataset_train = keras.preprocessing.timeseries_dataset_from_array(
x_train,
y_train,
sequence_length=sequence_length,
sampling_rate=step,
batch_size=batch_size,
)
検証データセット
検証データセットは最後の 792 行を含んではなりません、それらの記録のためのラベルデータを持たないからです、従ってデータの最後から 792 を差し引かれなければなりません。
検証ラベルデータセットは train_split の後の 792 から始まる必要がありますので、label_start に past + future (792) を加算しなければなりません。
x_end = len(val_data) - past - future
label_start = train_split + past + future
x_val = val_data.iloc[:x_end][[i for i in range(7)]].values
y_val = features.iloc[label_start:][[1]]
dataset_val = keras.preprocessing.timeseries_dataset_from_array(
x_val,
y_val,
sequence_length=sequence_length,
sampling_rate=step,
batch_size=batch_size,
)
for batch in dataset_train.take(1):
inputs, targets = batch
print("Input shape:", inputs.numpy().shape)
print("Target shape:", targets.numpy().shape)
Input shape: (256, 120, 7) Target shape: (256, 1)
訓練
inputs = keras.layers.Input(shape=(inputs.shape[1], inputs.shape[2]))
lstm_out = keras.layers.LSTM(32)(inputs)
outputs = keras.layers.Dense(1)(lstm_out)
model = keras.Model(inputs=inputs, outputs=outputs)
model.compile(optimizer=keras.optimizers.Adam(learning_rate=learning_rate), loss="mse")
model.summary()
Model: "functional_1" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 120, 7)] 0 _________________________________________________________________ lstm (LSTM) (None, 32) 5120 _________________________________________________________________ dense (Dense) (None, 1) 33 ================================================================= Total params: 5,153 Trainable params: 5,153 Non-trainable params: 0 _________________________________________________________________
チェックポイントを定期的にセーブするために ModelCheckpoint コールバックを、そして検証損失がもはや改善しないときに訓練を中断するために EarlyStopping コールバックを使用します。
path_checkpoint = "model_checkpoint.h5"
es_callback = keras.callbacks.EarlyStopping(monitor="val_loss", min_delta=0, patience=5)
modelckpt_callback = keras.callbacks.ModelCheckpoint(
monitor="val_loss",
filepath=path_checkpoint,
verbose=1,
save_weights_only=True,
save_best_only=True,
)
history = model.fit(
dataset_train,
epochs=epochs,
validation_data=dataset_val,
callbacks=[es_callback, modelckpt_callback],
)
Epoch 1/10 1172/1172 [==============================] - ETA: 0s - loss: 0.2059 Epoch 00001: val_loss improved from inf to 0.16357, saving model to model_checkpoint.h5 1172/1172 [==============================] - 101s 86ms/step - loss: 0.2059 - val_loss: 0.1636 Epoch 2/10 1172/1172 [==============================] - ETA: 0s - loss: 0.1271 Epoch 00002: val_loss improved from 0.16357 to 0.13362, saving model to model_checkpoint.h5 1172/1172 [==============================] - 107s 92ms/step - loss: 0.1271 - val_loss: 0.1336 Epoch 3/10 1172/1172 [==============================] - ETA: 0s - loss: 0.1089 Epoch 00005: val_loss did not improve from 0.13362 1172/1172 [==============================] - 110s 94ms/step - loss: 0.1089 - val_loss: 0.1481 Epoch 6/10 271/1172 [=====>........................] - ETA: 1:12 - loss: 0.1117
損失を次の関数で可視化できます。1 つの点の後、損失は減少をやめます。
def visualize_loss(history, title):
loss = history.history["loss"]
val_loss = history.history["val_loss"]
epochs = range(len(loss))
plt.figure()
plt.plot(epochs, loss, "b", label="Training loss")
plt.plot(epochs, val_loss, "r", label="Validation loss")
plt.title(title)
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.legend()
plt.show()
visualize_loss(history, "Training and Validation Loss")

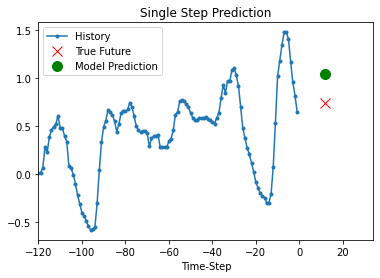
予測
今では上の訓練済みモデルは検証セットからの 5 セットの値に対する予測を行なうことができます。
def show_plot(plot_data, delta, title):
labels = ["History", "True Future", "Model Prediction"]
marker = [".-", "rx", "go"]
time_steps = list(range(-(plot_data[0].shape[0]), 0))
if delta:
future = delta
else:
future = 0
plt.title(title)
for i, val in enumerate(plot_data):
if i:
plt.plot(future, plot_data[i], marker[i], markersize=10, label=labels[i])
else:
plt.plot(time_steps, plot_data[i].flatten(), marker[i], label=labels[i])
plt.legend()
plt.xlim([time_steps[0], (future + 5) * 2])
plt.xlabel("Time-Step")
plt.show()
return
for x, y in dataset_val.take(5):
show_plot(
[x[0][:, 1].numpy(), y[0].numpy(), model.predict(x)[0]],
12,
"Single Step Prediction",
)




以上