Keras 2 : examples : 音声データ – CTC を使用した自動発話認識 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 06/25/2022 (keras 2.9.0)
* 本ページは、Keras の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
- Code examples : Audio Data : Automatic Speech Recognition using CTC (Author: Mohamed Reda Bouadjenek and Ngoc Dung Huynh)
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP
Keras 2 : examples : 音声データ – CTC を使用した自動発話認識
Description : 自動発話認識のための CTC ベース・モデルの訓練。
イントロダクション
発話認識はコンピュータサイエンスと計算言語学の分野にまたがるサブ領域で、コンピュータによる口語の認識とテキストへの翻訳を可能にする方法と技術を開発します。それはまた自動発話認識 (ASR), コンピュータ発話認識や speech to text (STT) としても知られています。それはコンピュータサイエンス、言語学とコンピュータ工学の分野の知識と研究を組込んでいます。
これは ASR を構築するために 2D CNN, RNN と Connectionist Temporal Classification (CTC) 損失を結合する方法を実演します。CTC は発話認識、手書き認識と他のシークエンス問題の深層ニューラルネットワークを訓練するために使用されるアルゴリズムです。CTC は、入力が出力とどのように整列されるか (トランスクリプトの文字が音声にどのように整列されるか) を知らないときに使用されます。作成するモデルは DeepSpeech2 に類似しています。
LibriVox プロジェクトからの LJSpeech データセットを使用します。それは 7 つのノンフィクションの書籍から単一話者が読み上げる節 (= passages) の短い音声クリップから構成されます。
モデルの品質を単語誤り率 (WER, Word Error Rate) を使用して評価します。WER は認識された単語のシークエンスで発生した置換、挿入と削除を合計して得られます。その数をもともと話された単語の総数で除算します。その結果が WER です。WER スコアを得るには jiwer パッケージをインストールする必要があります。以下のコマンド行を使用できます :
pip install jiwer
References:
セットアップ
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
from IPython import display
from jiwer import wer
LJSpeech データセットのロード
LJSpeech データセット をダウンロードしましょう。データセットは 13,100 音声ファイルを /wavs/ フォルダに wav ファイルとして含みます。各音声ファイルに対するラベル (トランスクリプト) は metadata.csv ファイルで与えられる文字列です。フィールドは :
- ID : これは対応する .wav ファイルの名前です。
- Transcription : 朗読者により話された単語 (UTF-8)
- Normalized transcription : 数字、序数と通貨単位が完全な単語 (UTF-8) に展開されたトランスクリプション。
このデモについては “Normalized transcription” フィールドを使用します。
各音声ファイルは 22,050 Hz のサンプリングレートを持つ単一チャネル 16-bit PCM WAV です。
data_url = "https://data.keithito.com/data/speech/LJSpeech-1.1.tar.bz2"
data_path = keras.utils.get_file("LJSpeech-1.1", data_url, untar=True)
wavs_path = data_path + "/wavs/"
metadata_path = data_path + "/metadata.csv"
# Read metadata file and parse it
metadata_df = pd.read_csv(metadata_path, sep="|", header=None, quoting=3)
metadata_df.columns = ["file_name", "transcription", "normalized_transcription"]
metadata_df = metadata_df[["file_name", "normalized_transcription"]]
metadata_df = metadata_df.sample(frac=1).reset_index(drop=True)
metadata_df.head(3)

そしてデータを訓練と検証セットに分割します。
split = int(len(metadata_df) * 0.90)
df_train = metadata_df[:split]
df_val = metadata_df[split:]
print(f"Size of the training set: {len(df_train)}")
print(f"Size of the training set: {len(df_val)}")
Size of the training set: 11790 Size of the training set: 1310
前処理
最初に使用される語彙を準備します。
# The set of characters accepted in the transcription.
characters = [x for x in "abcdefghijklmnopqrstuvwxyz'?! "]
# Mapping characters to integers
char_to_num = keras.layers.StringLookup(vocabulary=characters, oov_token="")
# Mapping integers back to original characters
num_to_char = keras.layers.StringLookup(
vocabulary=char_to_num.get_vocabulary(), oov_token="", invert=True
)
print(
f"The vocabulary is: {char_to_num.get_vocabulary()} "
f"(size ={char_to_num.vocabulary_size()})"
)
The vocabulary is: ['', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', "'", '?', '!', ' '] (size =31) 2021-09-28 21:16:33.150832: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags. 2021-09-28 21:16:33.692813: W tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.cc:39] Overriding allow_growth setting because the TF_FORCE_GPU_ALLOW_GROWTH environment variable is set. Original config value was 0. 2021-09-28 21:16:33.692847: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 9124 MB memory: -> device: 0, name: GeForce RTX 2080 Ti, pci bus id: 0000:65:00.0, compute capability: 7.5
次に、データセットの各要素に適用する変換を記述する関数を作成します。
# An integer scalar Tensor. The window length in samples.
frame_length = 256
# An integer scalar Tensor. The number of samples to step.
frame_step = 160
# An integer scalar Tensor. The size of the FFT to apply.
# If not provided, uses the smallest power of 2 enclosing frame_length.
fft_length = 384
def encode_single_sample(wav_file, label):
###########################################
## Process the Audio
##########################################
# 1. Read wav file
file = tf.io.read_file(wavs_path + wav_file + ".wav")
# 2. Decode the wav file
audio, _ = tf.audio.decode_wav(file)
audio = tf.squeeze(audio, axis=-1)
# 3. Change type to float
audio = tf.cast(audio, tf.float32)
# 4. Get the spectrogram
spectrogram = tf.signal.stft(
audio, frame_length=frame_length, frame_step=frame_step, fft_length=fft_length
)
# 5. We only need the magnitude, which can be derived by applying tf.abs
spectrogram = tf.abs(spectrogram)
spectrogram = tf.math.pow(spectrogram, 0.5)
# 6. normalisation
means = tf.math.reduce_mean(spectrogram, 1, keepdims=True)
stddevs = tf.math.reduce_std(spectrogram, 1, keepdims=True)
spectrogram = (spectrogram - means) / (stddevs + 1e-10)
###########################################
## Process the label
##########################################
# 7. Convert label to Lower case
label = tf.strings.lower(label)
# 8. Split the label
label = tf.strings.unicode_split(label, input_encoding="UTF-8")
# 9. Map the characters in label to numbers
label = char_to_num(label)
# 10. Return a dict as our model is expecting two inputs
return spectrogram, label
データセットオブジェクトの作成
入力に出現したのと同じ順序で変換された要素を生成する tf.data.Dataset オブジェクトを作成します。
batch_size = 32
# Define the trainig dataset
train_dataset = tf.data.Dataset.from_tensor_slices(
(list(df_train["file_name"]), list(df_train["normalized_transcription"]))
)
train_dataset = (
train_dataset.map(encode_single_sample, num_parallel_calls=tf.data.AUTOTUNE)
.padded_batch(batch_size)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
# Define the validation dataset
validation_dataset = tf.data.Dataset.from_tensor_slices(
(list(df_val["file_name"]), list(df_val["normalized_transcription"]))
)
validation_dataset = (
validation_dataset.map(encode_single_sample, num_parallel_calls=tf.data.AUTOTUNE)
.padded_batch(batch_size)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
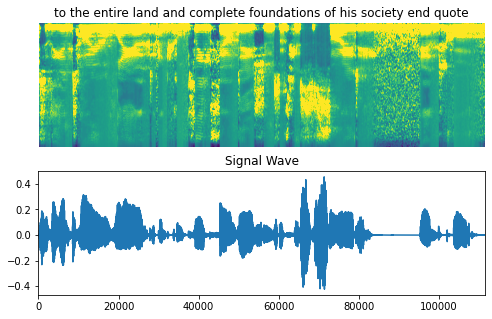
データの可視化
音声クリップ、スペクトログラムと対応するラベルを含む、データセットのサンプルを可視化しましょう。
fig = plt.figure(figsize=(8, 5))
for batch in train_dataset.take(1):
spectrogram = batch[0][0].numpy()
spectrogram = np.array([np.trim_zeros(x) for x in np.transpose(spectrogram)])
label = batch[1][0]
# Spectrogram
label = tf.strings.reduce_join(num_to_char(label)).numpy().decode("utf-8")
ax = plt.subplot(2, 1, 1)
ax.imshow(spectrogram, vmax=1)
ax.set_title(label)
ax.axis("off")
# Wav
file = tf.io.read_file(wavs_path + list(df_train["file_name"])[0] + ".wav")
audio, _ = tf.audio.decode_wav(file)
audio = audio.numpy()
ax = plt.subplot(2, 1, 2)
plt.plot(audio)
ax.set_title("Signal Wave")
ax.set_xlim(0, len(audio))
display.display(display.Audio(np.transpose(audio), rate=16000))
plt.show()
2021-09-28 21:16:34.014170: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:185] None of the MLIR Optimization Passes are enabled (registered 2)
モデル
CTC 損失関数を最初に定義します。
def CTCLoss(y_true, y_pred):
# Compute the training-time loss value
batch_len = tf.cast(tf.shape(y_true)[0], dtype="int64")
input_length = tf.cast(tf.shape(y_pred)[1], dtype="int64")
label_length = tf.cast(tf.shape(y_true)[1], dtype="int64")
input_length = input_length * tf.ones(shape=(batch_len, 1), dtype="int64")
label_length = label_length * tf.ones(shape=(batch_len, 1), dtype="int64")
loss = keras.backend.ctc_batch_cost(y_true, y_pred, input_length, label_length)
return loss
そしてモデルを定義します。DeepSpeech2 に類似したモデルを定義します。
def build_model(input_dim, output_dim, rnn_layers=5, rnn_units=128):
"""Model similar to DeepSpeech2."""
# Model's input
input_spectrogram = layers.Input((None, input_dim), name="input")
# Expand the dimension to use 2D CNN.
x = layers.Reshape((-1, input_dim, 1), name="expand_dim")(input_spectrogram)
# Convolution layer 1
x = layers.Conv2D(
filters=32,
kernel_size=[11, 41],
strides=[2, 2],
padding="same",
use_bias=False,
name="conv_1",
)(x)
x = layers.BatchNormalization(name="conv_1_bn")(x)
x = layers.ReLU(name="conv_1_relu")(x)
# Convolution layer 2
x = layers.Conv2D(
filters=32,
kernel_size=[11, 21],
strides=[1, 2],
padding="same",
use_bias=False,
name="conv_2",
)(x)
x = layers.BatchNormalization(name="conv_2_bn")(x)
x = layers.ReLU(name="conv_2_relu")(x)
# Reshape the resulted volume to feed the RNNs layers
x = layers.Reshape((-1, x.shape[-2] * x.shape[-1]))(x)
# RNN layers
for i in range(1, rnn_layers + 1):
recurrent = layers.GRU(
units=rnn_units,
activation="tanh",
recurrent_activation="sigmoid",
use_bias=True,
return_sequences=True,
reset_after=True,
name=f"gru_{i}",
)
x = layers.Bidirectional(
recurrent, name=f"bidirectional_{i}", merge_mode="concat"
)(x)
if i < rnn_layers:
x = layers.Dropout(rate=0.5)(x)
# Dense layer
x = layers.Dense(units=rnn_units * 2, name="dense_1")(x)
x = layers.ReLU(name="dense_1_relu")(x)
x = layers.Dropout(rate=0.5)(x)
# Classification layer
output = layers.Dense(units=output_dim + 1, activation="softmax")(x)
# Model
model = keras.Model(input_spectrogram, output, name="DeepSpeech_2")
# Optimizer
opt = keras.optimizers.Adam(learning_rate=1e-4)
# Compile the model and return
model.compile(optimizer=opt, loss=CTCLoss)
return model
# Get the model
model = build_model(
input_dim=fft_length // 2 + 1,
output_dim=char_to_num.vocabulary_size(),
rnn_units=512,
)
model.summary(line_length=110)
Model: "DeepSpeech_2" ______________________________________________________________________________________________________________ Layer (type) Output Shape Param # ============================================================================================================== input (InputLayer) [(None, None, 193)] 0 ______________________________________________________________________________________________________________ expand_dim (Reshape) (None, None, 193, 1) 0 ______________________________________________________________________________________________________________ conv_1 (Conv2D) (None, None, 97, 32) 14432 ______________________________________________________________________________________________________________ conv_1_bn (BatchNormalization) (None, None, 97, 32) 128 ______________________________________________________________________________________________________________ conv_1_relu (ReLU) (None, None, 97, 32) 0 ______________________________________________________________________________________________________________ conv_2 (Conv2D) (None, None, 49, 32) 236544 ______________________________________________________________________________________________________________ conv_2_bn (BatchNormalization) (None, None, 49, 32) 128 ______________________________________________________________________________________________________________ conv_2_relu (ReLU) (None, None, 49, 32) 0 ______________________________________________________________________________________________________________ reshape (Reshape) (None, None, 1568) 0 ______________________________________________________________________________________________________________ bidirectional_1 (Bidirectional) (None, None, 1024) 6395904 ______________________________________________________________________________________________________________ dropout (Dropout) (None, None, 1024) 0 ______________________________________________________________________________________________________________ bidirectional_2 (Bidirectional) (None, None, 1024) 4724736 ______________________________________________________________________________________________________________ dropout_1 (Dropout) (None, None, 1024) 0 ______________________________________________________________________________________________________________ bidirectional_3 (Bidirectional) (None, None, 1024) 4724736 ______________________________________________________________________________________________________________ dropout_2 (Dropout) (None, None, 1024) 0 ______________________________________________________________________________________________________________ bidirectional_4 (Bidirectional) (None, None, 1024) 4724736 ______________________________________________________________________________________________________________ dropout_3 (Dropout) (None, None, 1024) 0 ______________________________________________________________________________________________________________ bidirectional_5 (Bidirectional) (None, None, 1024) 4724736 ______________________________________________________________________________________________________________ dense_1 (Dense) (None, None, 1024) 1049600 ______________________________________________________________________________________________________________ dense_1_relu (ReLU) (None, None, 1024) 0 ______________________________________________________________________________________________________________ dropout_4 (Dropout) (None, None, 1024) 0 ______________________________________________________________________________________________________________ dense (Dense) (None, None, 32) 32800 ============================================================================================================== Total params: 26,628,480 Trainable params: 26,628,352 Non-trainable params: 128 _______________________________________________________________________________________
訓練と評価
# A utility function to decode the output of the network
def decode_batch_predictions(pred):
input_len = np.ones(pred.shape[0]) * pred.shape[1]
# Use greedy search. For complex tasks, you can use beam search
results = keras.backend.ctc_decode(pred, input_length=input_len, greedy=True)[0][0]
# Iterate over the results and get back the text
output_text = []
for result in results:
result = tf.strings.reduce_join(num_to_char(result)).numpy().decode("utf-8")
output_text.append(result)
return output_text
# A callback class to output a few transcriptions during training
class CallbackEval(keras.callbacks.Callback):
"""Displays a batch of outputs after every epoch."""
def __init__(self, dataset):
super().__init__()
self.dataset = dataset
def on_epoch_end(self, epoch: int, logs=None):
predictions = []
targets = []
for batch in self.dataset:
X, y = batch
batch_predictions = model.predict(X)
batch_predictions = decode_batch_predictions(batch_predictions)
predictions.extend(batch_predictions)
for label in y:
label = (
tf.strings.reduce_join(num_to_char(label)).numpy().decode("utf-8")
)
targets.append(label)
wer_score = wer(targets, predictions)
print("-" * 100)
print(f"Word Error Rate: {wer_score:.4f}")
print("-" * 100)
for i in np.random.randint(0, len(predictions), 2):
print(f"Target : {targets[i]}")
print(f"Prediction: {predictions[i]}")
print("-" * 100)
訓練プロセスを開始しましょう。
# Define the number of epochs.
epochs = 1
# Callback function to check transcription on the val set.
validation_callback = CallbackEval(validation_dataset)
# Train the model
history = model.fit(
train_dataset,
validation_data=validation_dataset,
epochs=epochs,
callbacks=[validation_callback],
)
2021-09-28 21:16:48.067448: I tensorflow/stream_executor/cuda/cuda_dnn.cc:369] Loaded cuDNN version 8100 369/369 [==============================] - 586s 2s/step - loss: 300.4624 - val_loss: 296.1459 ---------------------------------------------------------------------------------------------------- Word Error Rate: 0.9998 ---------------------------------------------------------------------------------------------------- Target : the procession traversed ratcliffe twice halting for a quarter of an hour in front of the victims' dwelling Prediction: s ---------------------------------------------------------------------------------------------------- Target : some difficulty then arose as to gaining admission to the strong room and it was arranged that a man may another custom house clerk Prediction: s ----------------------------------------------------------------------------------------------------
推論
# Let's check results on more validation samples
predictions = []
targets = []
for batch in validation_dataset:
X, y = batch
batch_predictions = model.predict(X)
batch_predictions = decode_batch_predictions(batch_predictions)
predictions.extend(batch_predictions)
for label in y:
label = tf.strings.reduce_join(num_to_char(label)).numpy().decode("utf-8")
targets.append(label)
wer_score = wer(targets, predictions)
print("-" * 100)
print(f"Word Error Rate: {wer_score:.4f}")
print("-" * 100)
for i in np.random.randint(0, len(predictions), 5):
print(f"Target : {targets[i]}")
print(f"Prediction: {predictions[i]}")
print("-" * 100)
---------------------------------------------------------------------------------------------------- Word Error Rate: 0.9998 ---------------------------------------------------------------------------------------------------- Target : two of the nine agents returned to their rooms the seven others proceeded to an establishment called the cellar coffee house Prediction: ---------------------------------------------------------------------------------------------------- Target : a scaffold was erected in front of that prison for the execution of several convicts named by the recorder Prediction: sss ---------------------------------------------------------------------------------------------------- Target : it was perpetrated upon a respectable country solicitor Prediction: ss ---------------------------------------------------------------------------------------------------- Target : oswald like all marine recruits received training on the rifle range at distances up to five hundred yards Prediction: ---------------------------------------------------------------------------------------------------- Target : chief rowley testified that agents on duty in such a situation usually stay within the building during their relief Prediction: s ----------------------------------------------------------------------------------------------------
終わりに
実際には約 50 エポックかそれ以上訓練するべきです。GeForce RTX 2080 Ti GPU を使用して各エポックはおよそ 5-6 分かかります。50 エポックで訓練したモデルは単語誤り率 (WER) ≈ 16% から 17% になります。
Audio file: LJ017-0009.wavv
- Target : sir thomas overbury was undoubtedly poisoned by lord rochester in the reign of james the first - Prediction: cer thomas overbery was undoubtedly poisoned by lordrochester in the reign of james the first
Audio file: LJ003-0340.wav
- Target : the committee does not seem to have yet understood that newgate could be only and properly replaced - Prediction: the committee does not seem to have yet understood that newgate could be only and proberly replace
Audio file: LJ011-0136.wav
- Target : still no sentence of death was carried out for the offense and in eighteen thirtytwo - Prediction: still no sentence of death was carried out for the offense and in eighteen thirtytwo
以上