🦙 LlamaIndex 0.8 : Getting Started : 上位コンセプト (翻訳/解説)
翻訳 : クラスキャット セールスインフォメーション
作成日時 : 11/10/2023 (v0.8.59)
* 本ページは、LlamaIndex の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
- Getting Started : High-Level Concepts
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
![]()
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Website: www.classcat.com ; ClassCatJP
🦙 LlamaIndex 0.8 : Getting Started : 上位コンセプト
これは、LLM アプリケーションを構築するときに頻繁に遭遇する上位コンセプトへの簡単なガイドです。
検索拡張生成 (RAG, Retrieval Augmented Generation)
LLM は膨大なデータの集合で訓練されますが、それらは 貴方の データでは訓練されません。検索拡張生成 (RAG) は、貴方のデータを LLM が既にアクセスできるデータに追加することによりこの問題を解決します。このドキュメントでは RAG への参照を頻繁に見るはずです。
RAG では、貴方のデータはロードされてクエリーのために準備、あるいは「インデックス作成」されます。ユーザクエリーはインデックス上で作用し、これはデータを最も関連性の高いコンテキストへとフィルタリングします。次にこのコンテキストとクエリーはプロンプトと一緒に LLM に送られ、そして LLM はレスポンスを返します。
貴方が構築しているものがチャットボットであれエージェントであれ、データをアプリケーションに組み込むために RAG テクニックを知ることを望むでしょう。
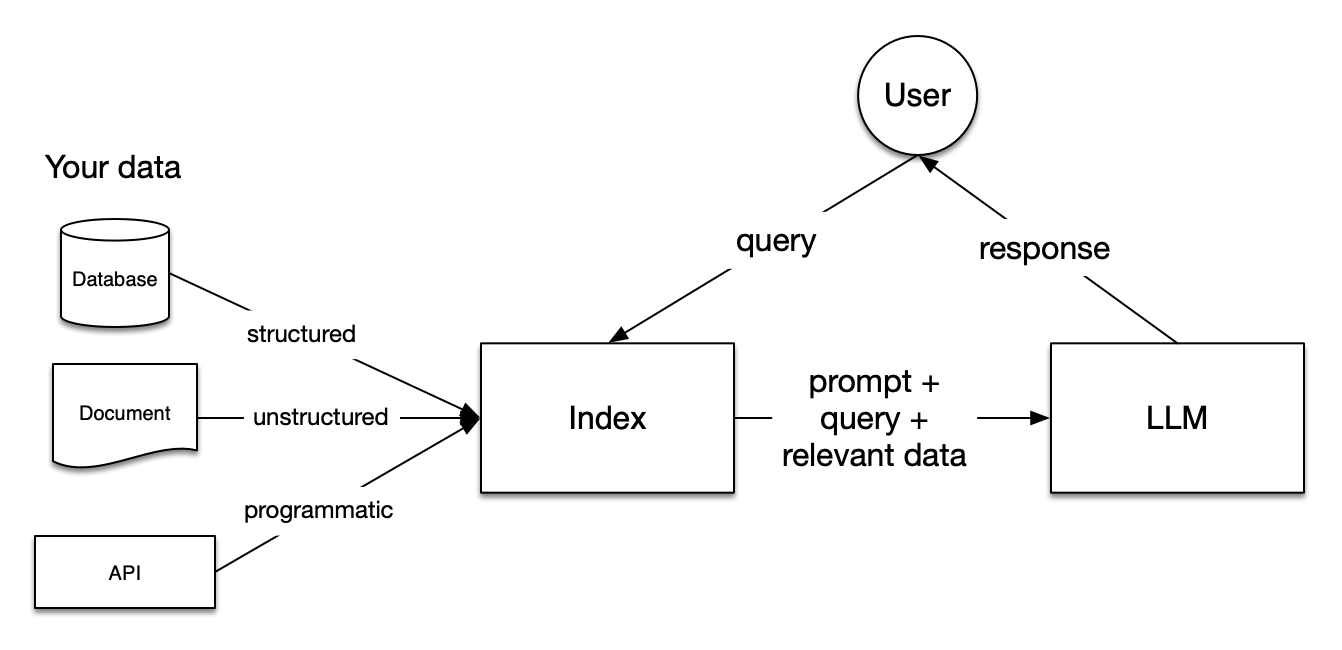
RAG 内部のステージ
RAG 内には 5 つの主要なステージがあります、これらは順番に構築している大きなアプリケーションの一部となります。これらは :
- ロード (Loading) : これは、貴方のデータをそれが存在する場所から (それがテキストファイル, PDF, 別の Web サイト, データベース, あるいは API であれ) 貴方のパイプラインに組み込みことを指します。LlamaHub はそこから選択できる数百のコネクタを提供しています。
- インデックス作成 (Indexing) : これは、データをクエリーすることを可能にするデータ構造を作成することを意味します。LLM については、これは殆ど常にベクトル埋め込み – データの意味の数値表現 – そして文脈的に関連するデータを正確に見つけることを簡単にする、多数の他のメタデータストラテジーを作成することを意味します。
- 保存 (Storing) : 貴方のデータのインデックスが作成されると、それを再インデックス化することを避けるためにインデックスと他のメタデータを保存することを殆ど常に望むはずです。
- クエリー (Querying) : 与えられたインデックス付けストラテジーに対して、サブクエリー、マルチステップ・クエリーそしてハイブリッドストラテジーを含む、クエリーをするために LLM と LlamaIndex データ構造を利用できる多くの方法があります。
- 評価 : 任意のパイプラインで重要なステップは、他のストラテジーと比較して、あるいは変更を加えたときどれほど効果的か確認することです。評価は、クエリーに対するレスポンスがどれほど正確で、忠実で高速かの客観的な尺度を提供します。

各ステップ内の重要なコンセプト
これらの各ステージ内のステップを指す、貴方が遭遇する幾つかの用語もあります。
ローディング・ステージ
ノードと Document : Document は任意のデータソース – 例えば、PDF, API 出力, あるいはデータベースからの検索データ – 周りのコンテナです。ノードは LlamaIndex のデータのアトミックなユニットでソースドキュメントの Document の「チャンク」を表します。ノードはそれらが含まれる document や他のノードに関連づけるメタデータを持ちます。
コネクタ : データコネクタ (Reader と呼ばれる場合も多いです) は様々なデータソースやデータ形式からデータを Document とノードに取り込みます。
インデックス作成ステージ
インデックス : データをひとたび取り込めば、LlamaIndex はデータを検索取得しやすい構造にインデックス作成するのに役立ちます。これは通常はベクトル埋め込みを生成することを含みます、これはベクトルストアと呼ばれる特殊なデータベースにストアされます。インデックスはまたデータについての様々なメタデータもストアできます。
埋め込み : LLM は埋め込みと呼ばれるデータの数値表現を生成します。関連性についてデータをフィルタリングするとき、LlamaIndex はクエリーを埋め込みに変換し、ベクトルストアはクエリーの埋め込みに数値的に類似したデータを見つけます。
クエリーステージ
Retrievers : retriever は、クエリーが与えられたとき関連するコンテキストをインデックスから効率的に検索取得する方法を定義します。検索取得ストラテジーは検索されるデータの関連性とそれにより行われる効率性へのキーとなります。
ノード・ポストプロセッサ : ノード・ポストプロセッサは検索取得されたノードのセットを受け取り、それらに変換、フィルタリングや再ランク付けロジックを適用します。
レスポンス・シンセサイザー : レスポンス・シンセサイザーは、ユーザクエリーと検索取得されたテキストチャンクの与えられたセットを使用して、LLM からレスポンスを生成します。
すべてをまとめる
データに支援された LLM アプリケーションのユースケースは無限にありますが、それらはおおよそ 3 つのカテゴリーにグループ分けできます :
クエリーエンジン : クエリーエンジンは貴方のデータに対して質問を尋ねることを可能にする end-to-end なパイプラインです。それは自然言語のクエリーを受け取り、検索取得されて LLM に渡される参照コンテキストとともに、レスポンスを返します。
チャットエンジン : チャットエンジンは貴方のデータとの会話をするための end-to-end なパイプラインです (単一の質問 & 応答の代わりに複数のやり取りを持ちます)。
エージェント : エージェントは LLM により強化された自動化された意思決定者 (decision maker) で、ツール のセットを通して世界と相互作用します。エージェントは与えられたタスクを完了するために任意の数のステップを取り、事前決定されたステップに従うのではなく、最善策なアクションを動的に決定できます。これはより複雑なタスクに取り組むための更なる柔軟性をそれに与えます。
以上