🦙 LlamaIndex.TS : 上位コンセプト (翻訳/解説)
翻訳 : クラスキャット セールスインフォメーション
作成日時 : 11/24/2023
* 本ページは、LlamaIndex.TS の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
![]()
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Website: www.classcat.com ; ClassCatJP
🦙 LlamaIndex.TS : 上位コンセプト
LlamaIndex.TS はカスタムデータに対して LLM で強化されたアプリケーション (e.g. Q&A, チャットボット) を構築するのに役立ちます。
この上位コンセプト・ガイドでは、以下を学習します :
- 貴方自身のデータを使用して LLM がどのように質問に回答するか。
- 貴方自身のクエリーパイプラインを構成するための LlamaIndex.TS の主要コンセプトとモジュール。
貴方のデータに対して質問に答える
LlamaIndex は LLM を貴方のデータとともに使用する場合、2 段階のメソッドを使用します :
- インデックス作成・ステージ : 知識ベースの準備、そして
- クエリー・ステージ : 質問への応答で LLM を支援するため、知識 (ベース) から関連性の高いコンテキストを取得します。
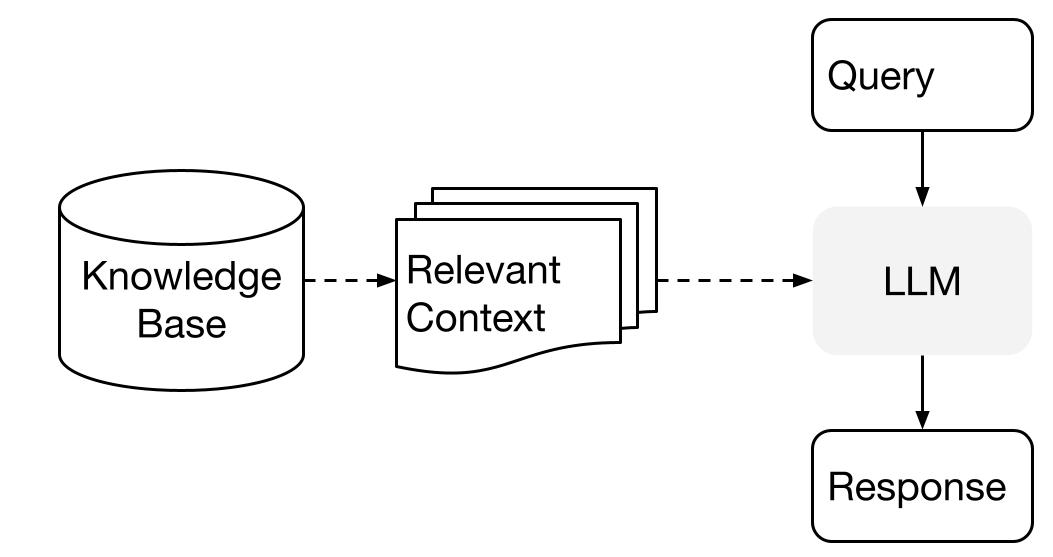
このプロセスはまた RAG (検索拡張生成) とも呼ばれます。
LlamaIndex.TS は両方のステップを非常に簡単に行なうための必須のツールキットを提供します。
各ステージを詳細に探求しましょう。
インデックス作成ステージ
LlamaIndex.TS はデータコネクタとインデックスのパッケージを使用して知識ベースを準備するのに役立ちます。

データローダ : データコネクタ (i.e. リーダー) は様々なデータソースとデータ形式からデータを単純な Document 表現 (テキストと単純なメタデータ) に取り込みます。
ドキュメント / ノード : Document はデータソース – 例えば、PDF, API 出力やデータベースから取得されたデータ – 周りの汎用コンテナです。ノードは LlamaIndex のデータの原始的 (atomic) ユニットでソース Document の「チャンク」を表します。それは、正確で表現力のある検索操作を可能にするメタデータと (他のノードへの) 関係性を含むリッチな表現です。
データインデックス : データを取り込んだら、LlamaIndex はデータを検索取得しやすい形式にインデックス作成することを支援します。
内部的には、LlamaIndex は raw ドキュメントを中間表現にパースして、ベクトル埋め込みを計算し、そしてデータをインメモリかディスクにストアします。
クエリー・ステージ
クエリーステージでは、クエリーパイプラインはユーザクエリーが与えられたとき最も関連性の高いコンテキストを検索取得し、そしてそれを応答を合成するために (クエリーと一緒に) LLM に渡します。
これは元の訓練データにはない最新の知識を LLM に与えます (そしてハルシネーションも軽減します)。
クエリーステージの主要な課題は、(多くの可能性がある) 知識ベースに対する検索取得、orchestration, そして推論 (reasoning) です。
LlamaIndex は、Q&A (クエリーエンジン), チャットボット (チャットエンジン), あるいはエージェントの一部として RAG パイプラインを構築して統合するのを支援する組み合わせ可能なモジュールを提供します。
これらのビルディングブロックはランク付け設定を反映するようにカスタマイズしたり、構造化された方法で複数の知識ベースに対して推論するように構成したりできます。
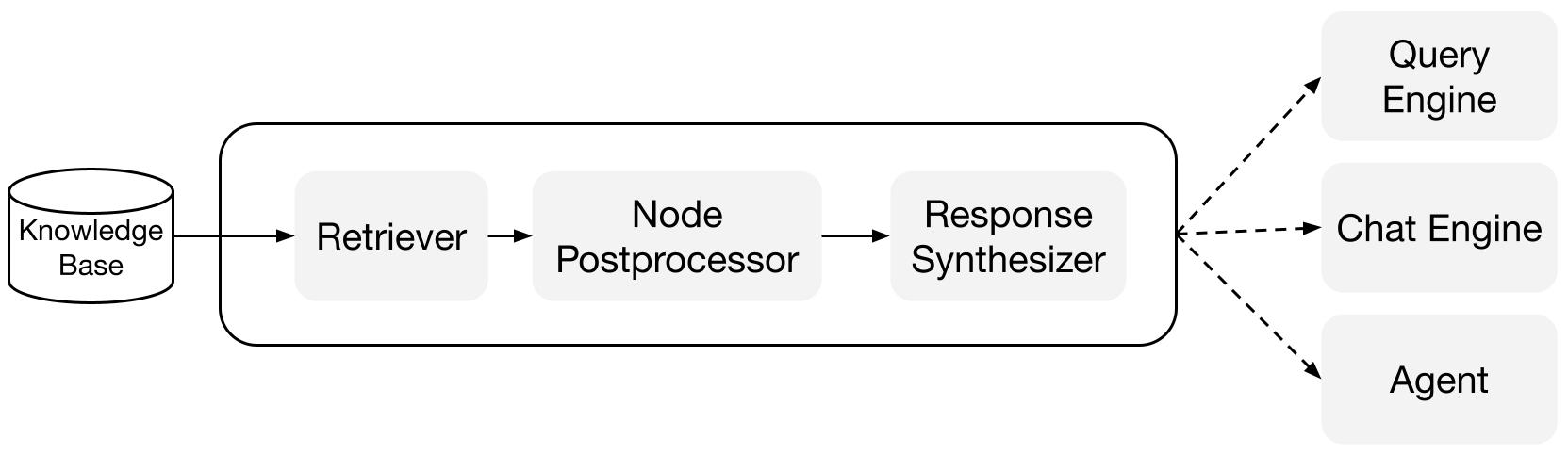
ビルディングブロック
Retrievers : retriever は、クエリーが与えられたとき、関連するコンテキストを知識ベース (i.e. インデックス) から効率的に検索取得する方法を定義します。具体的な検索ロジックは差分インデックス (difference indices) について異なり、最も一般的なものはベクトルインデックスに対する密検索 (dense retrieval) です。
応答シンセサイザー : 応答シンセサイザーは、ユーザクエリーと検索取得されたテキストチャンクの特定のセットを使用して、LLM から応答を生成します。
パイプライン
クエリーエンジン : クエリーエンジンは end-to-end なパイプラインで、データに対して質問をすることを可能にします。それは自然言語のクエリーを受け取り、 検索されて LLM に渡された参照コンテキストとともに、レスポンスを返します。
チャットエンジン : チャットエンジンはデータと会話するための end-to-end なパイプラインです (単一の質問 & 応答ではなく複数のやり取り)。
以上