Amazon Bedrock : 最初の一歩 – 基礎知識と実験
作成 : Masashi Okumura (@ClassCat)
作成日時 : 06/29/2024
* 本ページは、Amazon Bedrock : User Guide の以下のページを参考にして、最小限の実験をするために必要な手順を説明しています :
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

Amazon Bedrock : 最初の一歩 – 基礎知識と実験
1. 基礎知識
Amazon Bedrock とは何か
Amazon Bedrock は、AI スタートアップ企業や Amazon の高性能な基礎モデル (FM) を統一 API を通して利用可能にする、完全マネージド型サービスです。幅広い基礎モデルからユースケースに最適なモデルを見つけることができます。
Amazon Bedrock はまた、堅牢な生成 AI アプリケーションを構築するための幅広い機能セットも提供します。Amazon Bedrock により、ユースケースに最適な基礎モデルを簡単に実験して評価することができ、微調整や検索拡張生成 (RAG) のような技術を使用して貴方のデータで非公開にカスタマイズし、更にタスクを実行するエージェントを構築することができます。
Amazon Bedrock の機能
- プロンプトと configuration を使用した実験 – API やテキスト、画像、チャットプレイグラウンドを使用してグラフィカルに実験できます。準備ができたら InvokeModel API へのリクエストを行うようにアプリケーションをセットアップします。
- 貴方のデータソースからの情報を使用して応答生成を拡張する – 知識ベースを作成して基盤モデルの応答生成を拡張します。
- 顧客を支援する方法を推論するアプリケーションの作成 – 基盤モデルを使用し、API コールを行い、知識ベースに問い合わせるエージェントを構築します。
- 訓練データで特定のタスクやドメインにモデルを適応させる – 微調整や継続的な事前訓練 (continued-pretraining) のために訓練データを提供することで基盤モデルをカスタマイズします。
- FB-ベースのアプリケーションの効率と出力を向上させる
- 貴方のユースケースのためのベストモデルを決定する – 様々なモデルの出力を組み込み、またはカスタムプロンプトデータセットを使用して評価します。
- 不適切、望ましくないコンテンツの回避 – ガードレールを使用してセーフガードを実装します。
2. 実践
Amazon Bedrock はプレイグラウンドで簡単に実験できますが、その前に利用したい基盤モデルへのアクセス権を得る必要があります。
この際に以下の注意点があります :
- Amazon Bedrock を使用可能とするため、ユーザの許可ポリシーとして AmazonBedrockFullAccess を追加しておきます。
- 更に、モデルへのアクセスをリクエストするユーザは AWSMarketplaceFullAccess のようなポリシーが必要となります。
- リージョンごとに利用可能なベースモデルが異なります。Anthropic の Claude 3.5 Sonnet を使用するためには、例えば us-east-1 – 米国東部 (バージニア北部) を使用する必要があります。(参考: Model support by AWS Region)
モデルアクセス
基盤モデルへのアクセスを得るには、(上記のポリシーを持つような) 権限を持つ IAM ユーザが Amazon Bedrock 管理コンソールからアクセスをリクエストする必要があります。
モデルアクセスを管理するには、管理コンソールの左側のナビゲーションペインの下部にある モデルアクセス メニューを選択します。すると下図のように、利用可能なモデルのリスト、アクセス権の有無などを示すアクセスのステータス、モデルの出力モダリティ、そしてエンドユーザ使用許諾契約 (EULA) が表示されます :
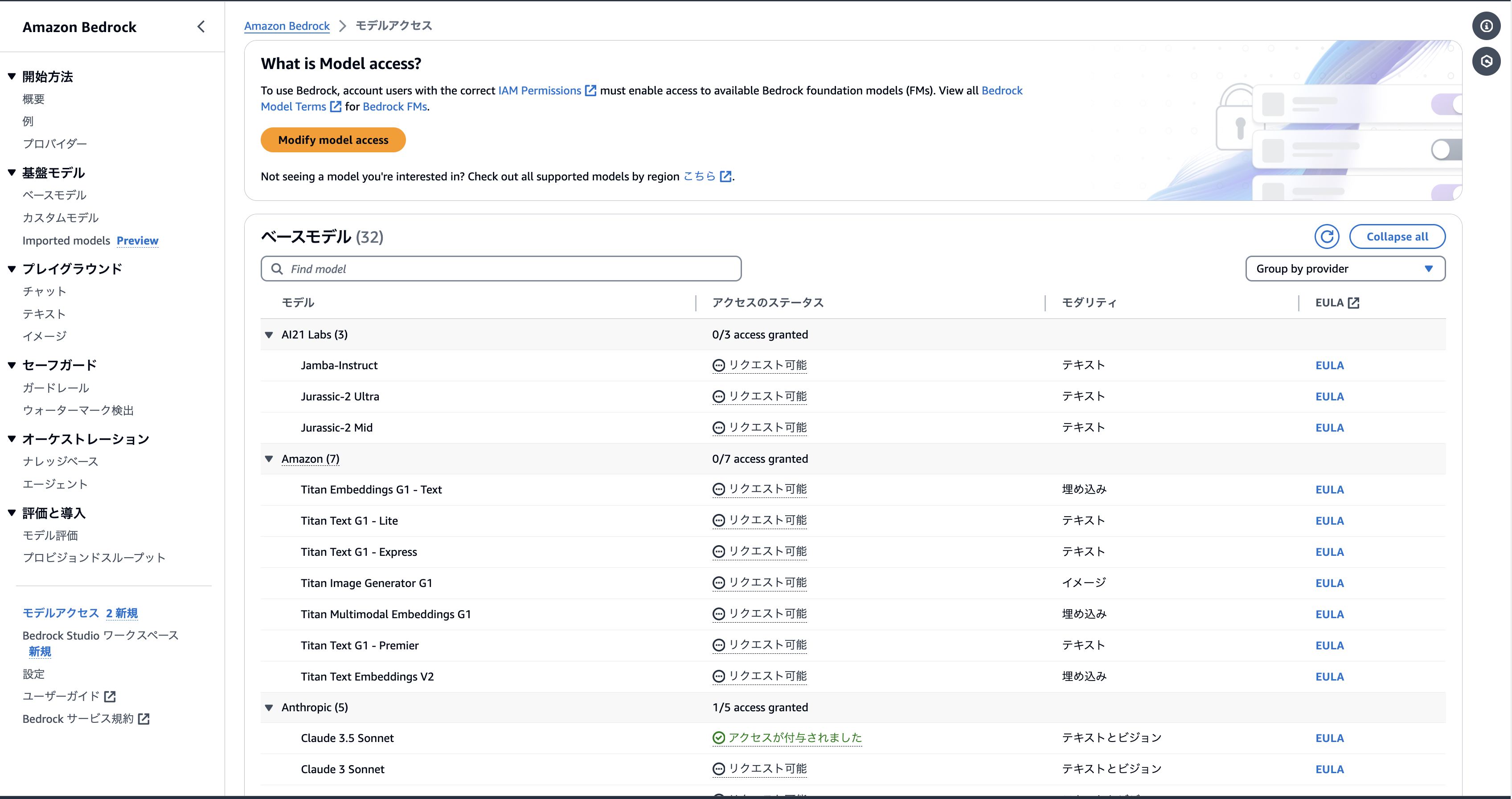
この モデルアクセス ページから、実際にモデルへのアクセスをリクエストするには以下の手順で行います :
- 上部の What is Model access? セクションの Modify model access をクリックします。(注意 : 管理コンソールのステータスにより、Enable all models or Enable specific models と表示される場合もありますが、以下の基本的な操作は同じです。)

- すると、次のような Edit model access ページに移行します :

- ここで、利用したい基盤モデルにチェックを入れます。プロバイダーをチェックすれば、そのプロバイダーから提供される基盤モデルすべてにチェックが入ります。以下の例は Anthropic にチェックを入れています :

- アクセスをリクエストするモデルを選択したら、右下の Next をクリックします。以降、プロバイダーによっては最初のリクエストで幾つかの確認事項の入力を求められますが、最終的に Submit をクリックしてリクエストを送信します。
- (筆者が試した範囲内では) さほど時間がかからずにアクセスが許可され、以下のようにステータスが変わりました :

プレイグラウンド
準備ができたのでプレイグラウンドで実験してみましょう。
テキストのプレイグラウンド
テキストのプレイグラウンド では Amazon Bedrock が提供するテキストモデルを試すことができます。モデルにテキストを送信すれば、そのプロンプトからモデルが生成したテキストを表示します。
使い方は簡単です :
- [プレイグラウンド] > [テキスト] メニューを選択すると、以下のような画面に移行します :

- 左上の モデルを選択 ボタンをクリックすると次のようなダイアログボックスからモデルが選択できます。選択したら右下の 適用 ボタンをクリックします :

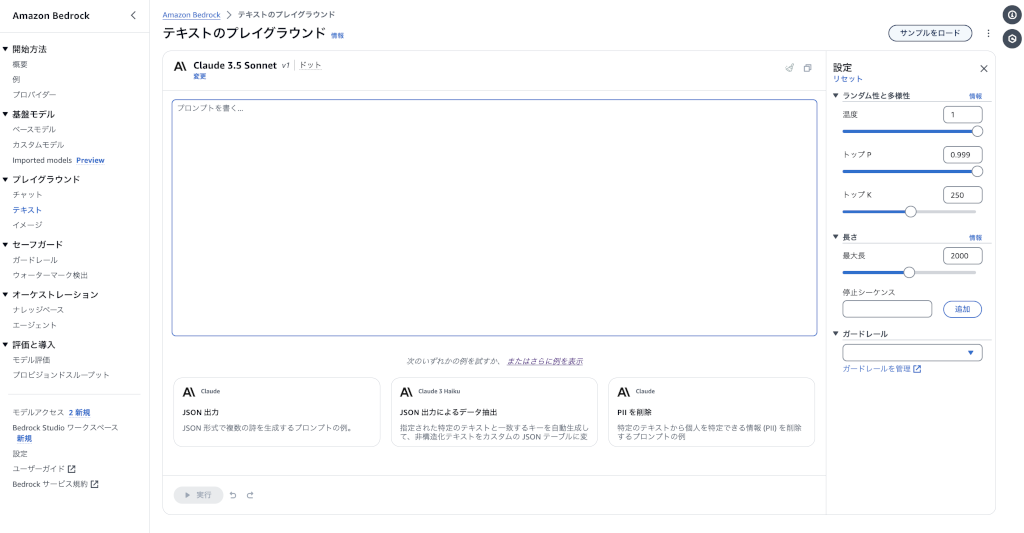
- モデルを選択すると、下図のように右側のペインに設定項目が表示され、中央のペインでプロンプトを入力して実行できるようになります (ここでは Anthropic の) :
以上