チャットボットが「記憶から」回答できない質問を処理するには、web 検索ツールを統合します。チャットボットはこのツールを使用して関連情報を検索してより良い応答を提供します。
※ LangGraph 0.5 でドキュメント構成が大幅に変更されましたので、再翻訳しながら Google Colab ベースで動作するようにまとめ直しています。モデルは可能な限り最新版を利用し、プロンプトは日本語を使用します。
LangGraph 0.5 on Colab : Get started : Tavily Web 検索ツールの追加
作成 : クラスキャット・セールスインフォメーション
作成日時 : 06/29/2025
* 本記事は langchain-ai.github.io の以下のページを独自に翻訳した上で、補足説明を加えてまとめ直しています :
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

◆ お問合せ : 下記までお願いします。
- クラスキャット セールス・インフォメーション
- sales-info@classcat.com
- ClassCatJP
![]()
LangGraph 0.5 on Colab : Get started : Tavily Web 検索ツールの追加
チャットボットが「記憶から」回答できない質問を処理するには、web 検索ツールを統合します。チャットボットはこのツールを使用して関連情報を検索してより良い応答を提供します。
前提条件
このチュートリアルを始める前に、次を所持していることを確認してください :
- Tavily 検索エンジン 用の API キー
0. 準備
%%capture --no-stderr
%pip install -U --quiet langgraph
1.検索エンジンのインストール
Tavily 検索エンジンを使用するために要件をインストールします :
%pip install -U langchain-tavily
2. 環境の設定
検索エンジン API キーで環境を設定します :
import getpass
import os
def _set_env(key: str):
if key not in os.environ:
os.environ[key] = getpass.getpass(f"{key}:")
_set_env("TAVILY_API_KEY")
3. ツールの定義
web 検索ツールの定義 :
API リファレンス: TavilySearch
Tavily 検索 API にクエリーを発行して json を取得するツールです。Tavily の検索 API は AI エージェント (LLM) 向けに特に構築された検索エンジンで、リアルタイムに正確で事実に基づいた結果を高速に提供します。
from langchain_tavily import TavilySearch
tool = TavilySearch(max_results=2)
tools = [tool]
tool.invoke("LangGraph の「ノード」とは何でしょう?")
結果は、チャットボットが質問に答えるために使用できるページの概要です :
{'query': 'LangGraph の「ノード」とは何でしょう?',
'follow_up_questions': None,
'answer': None,
'images': [],
'results': [{'url': 'https://qiita.com/ikedachin/items/2e7197ea87861247425f',
'title': 'LangChain v0.3 その6 ~LangGraphの基礎~ #LLM - Qiita',
'content': 'Go to list of users who liked Delete article Deleted articles cannot be recovered. Draft of this article would be also deleted. Are you sure you want to delete this article? LangChain v0.3\u3000その6 ~LangGraphの基礎~ ここまで 前回まで、ChatPromptTemplateやLCEL、LangGraphに繋げるためのPydanticについてやってきました。 今回はいよいよLangGraphです。 ぜひ、classとPydanticをしっかり理解しておけば難しくなさそうです。 今日やること LangGraphを使って、日本語と英語で大喜利させて、その結果から日本語文化と英語文化を比較することをやってみます。 LangGraphはnodeとedgeとstateの理解が必要です。 なので、日本語で大喜利するnodeと、英語で大喜利するnode、これらを合わせて文化を比較するノードが必要になりますね。 バージョン関連 Python 3.10.8 langchain==0.3.7 python-dotenv langchain-openai==0.2.5 langgraph>0.2.27 langchain-core ※LLMのAPIはAzureOpenAIのgpt-4o-miniを使いました 復習 その5において、Pydanticの使い方をやりましたが、TypedDictを使う方法と、BaseModelを使う方法がありました。 TypedDict: なんやら辞書形式でstateを受け渡す方法 from langchain_core.pydantic_v1 import BaseModelはfrom pydantic import BaseModelに置き換えろって警告が出ます。僕の場合、Windowsだけ。Macは出なかった。 oogiri_japaneseとoogiri_english oogiri_englishの場合は英語に翻訳するLCELが増えてるだけです。 今回はチェーンの最初と最後をset_entry_pointとset_entry_pointを使う書き方でやってみましょう。 set_entry_pointとset_entry_pointを使う書き方とちょっとだけ違う。 Go to list of users who liked Go to list of comments Register as a new user and use Qiita more conveniently Go to list of users who liked Delete article Deleted articles cannot be recovered. Draft of this article would be also deleted. Are you sure you want to delete this article?',
'score': 0.608897,
'raw_content': None},
{'url': 'https://note.com/npaka/n/n01954b4c649e',
'title': 'LangGraph の概要|npaka - note',
'content': '`from langgraph.graph import StateGraph from typing import TypedDict, List, Annotated import Operator all_actions: Annotated[List[str], operator.add] graph = StateGraph(State)` `graph.add_node("model", model) graph.add_node("tools", tool_executor)` `from langgraph.graph import END` `graph.set_entry_point("model")` `graph.add_edge("tools", "model")` ・Conditional Edge最初にどのNodeに移動するかを決定するために関数 (多くの場合 LLM) が使用される場所です。 `graph.add_conditional_edge( `app = graph.compile()` Agent Executor Agent Executor `from typing import TypedDict, Annotated, List, Union from langchain_core.agents import AgentAction, AgentFinish from langchain_core.messages import BaseMessage import operator agent_outcome: Union[AgentAction, AgentFinish, None] intermediate_steps: Annotated[list[tuple[AgentAction, str]], operator.add]` Chat Agent Executor `from typing import TypedDict, Annotated, Sequence import operator from langchain_core.messages import BaseMessage messages: Annotated[Sequence[BaseMessage], operator.add]` (Agent Executor および Chat Agent Executor) (Agent Executor および Chat Agent Executor) (Agent Executor および Chat Agent Executor) (Chat Agent Executor のみ) 場合によっては、ツールの出力を直接返したい場合があります。LangChain の return\\_direct パラメータを使用する簡単な方法を提供します。ただし、これにより、ツールの出力が常に直接返されるようになります。場合によっては、応答を直接返すかどうかを LLM に選択させたい場合があります。 (Chat Agent Executor のみ) ・より高度なエージェントランタイム (LLM Compiler、plan-and-solveなど) ',
'score': 0.57666177,
'raw_content': None}],
'response_time': 0.95}
4. グラフの定義
最初のチュートリアルで作成した StateGraph に対して、LLM に bind_tools を追加します。これは、LLM が検索エンジンを使用したい場合に正しい JSON 形式を認識させます。
最初に LLM を選択しましょう :
OpenAI
%pip install -U "langchain[openai]"
import os
from langchain.chat_models import init_chat_model
_set_env("OPENAI_API_KEY")
llm = init_chat_model("openai:gpt-4.1")
👉 Read the OpenAI integration docs
Anthropic
%pip install -U "langchain[anthropic]"
import os
from langchain.chat_models import init_chat_model
_set_env("ANTHROPIC_API_KEY")
llm = init_chat_model("anthropic:claude-4-sonnet-20250514")
👉 Read the Anthropic integration docs
これでそれを StateGraph に組み込むことができます :
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
# Modification: tell the LLM which tools it can call
# highlight-next-line
llm_with_tools = llm.bind_tools(tools)
def chatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
graph_builder.add_node("chatbot", chatbot)
5. ツールを実行する関数の作成
次に、ツールが呼び出された場合に実行する関数を作成します。BasicToolNode のいう名前の新しいノードにツールを追加することでこれを行います、これは状態の最新のメッセージを確認して、メッセージが tool_calls を含む場合にツールを呼び出します。それは LLM の tool_calling サポートに依存しており、これは Anthropic, OpenAI, Google Gemini そしてその他多くの LLM プロバイダーで利用可能です。
API リファレンス: ToolMessage
ツールの実行結果をモデルに返すためのメッセージ。ToolMessage はツール呼び出しの結果を含みます。通常、結果は content フィールド内にエンコードされます。
import json
from langchain_core.messages import ToolMessage
class BasicToolNode:
"""A node that runs the tools requested in the last AIMessage."""
def __init__(self, tools: list) -> None:
self.tools_by_name = {tool.name: tool for tool in tools}
def __call__(self, inputs: dict):
if messages := inputs.get("messages", []):
message = messages[-1]
else:
raise ValueError("No message found in input")
outputs = []
for tool_call in message.tool_calls:
tool_result = self.tools_by_name[tool_call["name"]].invoke(
tool_call["args"]
)
outputs.append(
ToolMessage(
content=json.dumps(tool_result),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}
tool_node = BasicToolNode(tools=[tool])
graph_builder.add_node("tools", tool_node)
Note : If you do not want to build this yourself in the future, you can use LangGraph’s prebuilt ToolNode.
6. conditional_edges の定義
ツールノードを追加したら、conditional_edges を定義できます。
エッジ は制御フローを一つのノードから次のノードへと導きます。条件付きエッジ は単一のノードから始まり、通常は “if” ステートメントを含み、現在のグラフ状態により異なるノードへルーティングします。これらの関数は現在のグラフ状態を受け取り、どのノードを次に呼び出すかを示す文字列または文字列のリストを返します。
次に、route_tools と呼ばれるルーター関数を定義します、これはチャットボットの出力内の tool_calls をチェックします。add_conditional_edges を呼び出すことでこの関数をグラフに提供します、これはグラフに、チャットボット・ノードが完了したら、この関数を確認して次にどこへ進むか確認するように指示します。
この条件は、ツール呼び出しが存在する場合には tools に、そうでないなら END にルーティングされます。条件は END を返すことができるので、今回は明示的に finish_point を設定する必要はありません。
def route_tools(
state: State,
):
"""
Use in the conditional_edge to route to the ToolNode if the last message
has tool calls. Otherwise, route to the end.
"""
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"No messages found in input state to tool_edge: {state}")
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tools"
return END
# The `tools_condition` function returns "tools" if the chatbot asks to use a tool, and "END" if
# it is fine directly responding. This conditional routing defines the main agent loop.
graph_builder.add_conditional_edges(
"chatbot",
route_tools,
# The following dictionary lets you tell the graph to interpret the condition's outputs as a specific node
# It defaults to the identity function, but if you
# want to use a node named something else apart from "tools",
# You can update the value of the dictionary to something else
# e.g., "tools": "my_tools"
{"tools": "tools", END: END},
)
# Any time a tool is called, we return to the chatbot to decide the next step
graph_builder.add_edge("tools", "chatbot")
graph_builder.add_edge(START, "chatbot")
graph = graph_builder.compile()
Note : You can replace this with the prebuilt tools_condition to be more concise.
7. グラフの可視化 (オプション)
get_graph メソッドと draw_ascii や draw_png のような “draw” メソッドの一つを使用してグラフを可視化できます。それぞれの draw メソッドは追加の依存関係が必要です。
from IPython.display import Image, display
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass
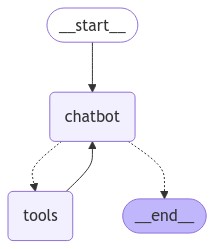
8. ボットに質問する
これで、チャットボットにトレーニングデータ以外の質問をすることができます :
def stream_graph_updates(user_input: str):
for event in graph.stream({"messages": [{"role": "user", "content": user_input}]}):
for value in event.values():
print("Assistant:", value["messages"][-1].content)
while True:
try:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
stream_graph_updates(user_input)
except:
# fallback if input() is not available
user_input = "What do you know about LangGraph?"
print("User: " + user_input)
stream_graph_updates(user_input)
break
User: LangGraph のユースケースは2025年現在、増えてる?
Assistant:
Assistant: {"query": "LangGraph \u30e6\u30fc\u30b9\u30b1\u30fc\u30b9 2025\u5e74 \u73fe\u72b6 \u5897\u52a0\u50be\u5411", "follow_up_questions": null, "answer": null, "images": [], "results": [{"url": "https://qiita.com/sponge841841/items/7b8e64a5a34ef2795e82", "title": "IT\u6280\u8853\u30cb\u30e5\u30fc\u30b9\u8981\u7d04 - 2025-06-26 #\u30d7\u30ed\u30b0\u30e9\u30df\u30f3\u30b0 - Qiita", "content": "\u8a18\u4e8b\u3067\u306f\u3001ES2020\u4ee5\u964d\u306b\u8ffd\u52a0\u3055\u308c\u305fPromise\u306e\u65b0\u6a5f\u80fd\u306b\u7126\u70b9\u3092\u5f53\u3066\u3001\u30e6\u30fc\u30b9\u30b1\u30fc\u30b9\u3092\u4ea4\u3048\u3066\u7d39\u4ecb\u3057\u3066\u3044\u307e\u3059\u3002 ... \u5897\u52a0\u50be\u5411\u306b\u3042\u308b\u3002\u7279\u306b\u6ce8\u76ee\u3055\u308c\u308b\u306e\u306f5G", "score": 0.34475276, "raw_content": null}, {"url": "https://zenn.dev/chips0711/articles/2876f478164f28", "title": "\u3010\u6700\u65b0\u3011OpenAI\u306eResponses API/Agents SDK\u3067\u5b9f\u73fe\u3059\u308b\u6b21\u4e16\u4ee3AI ...", "content": "\u30e6\u30fc\u30b9\u30b1\u30fc\u30b9\u3068\u3057\u3066\u306f\u3001\u30ab\u30b9\u30bf\u30de\u30fc\u30b5\u30dd\u30fc\u30c8\u3001\u81ea\u52d5\u691c\u7d22\u30fb\u8abf\u67fb\u30a8\u30fc\u30b8\u30a7\u30f3\u30c8\u3001\u6587\u66f8\u8981\u7d04\u30fb\u5206\u6790\u30c4\u30fc\u30eb\u3001\u793e\u5185\u30ca\u30ec\u30c3\u30b8\u30d9\u30fc\u30b9\u691c\u7d22\u306a\u3069\u3001\u3053\u308c\u307e\u3067LangChain\u3084", "score": 0.22926803, "raw_content": null}], "response_time": 0.8}
Assistant: 現時点(2025年)で「LangGraph」のユースケースが増加しているかについての明確な統計データや公式レポートは見つかりませんでしたが、関連技術であるLangChainやOpenAIのAgents SDKと同様に、ユースケースの拡大傾向は見られる、と考えられます。
近年、生成AIを活用したカスタマーサポート、自動調査・情報収集、文書要約・分析、社内ナレッジベース検索などの分野でLangGraph(あるいは同種技術)の応用例が増えているという情報は複数の技術ニュース記事や事例記事から確認できます。
要点
- LangGraph自体のユースケース増加について明確な数値情報はまだ普及していない
- 生成AIやワークフロー自動化、文書処理関連の用途でLangChainや類似基盤技術の導入事例が拡大しており、LangGraphもこの流れの中に位置すると考えられる
- 企業や開発者コミュニティでの注目度は高まっている
まとめ:LangGraphのユースケースは2025年にかけて増加傾向にあると推測されますが、今後さらに普及データや具体的な導入事例が出てくることが期待されます。
9. prebuilts の使用
使いやすさのために、以下を LangGraph の prebuilts (事前構築済み) コンポーネントに置き換えるようにコードを調整してください。これらは並列 API 実行のような機能が組み込まれています。
- BasicToolNode は prebuilt ToolNode で置き換えられます
最後の AIMessage 内で呼び出されたツールを実行するノード。
- route_tools は prebuilt tools_condition で置き換えられます
conditional_edge 内で使用して、最後のメッセージが tool 呼び出しを含む場合に ToolNode にルーティングします。そうでないなら、end にルーティングします。
%%capture --no-stderr
%pip install -U --quiet langgraph
%pip install -U --quiet langchain-tavily
import getpass
import os
def _set_env(key: str):
if key not in os.environ:
os.environ[key] = getpass.getpass(f"{key}:")
_set_env("TAVILY_API_KEY")
OpenAI
%pip install -U "langchain[openai]"
import os
from langchain.chat_models import init_chat_model
_set_env("OPENAI_API_KEY")
llm = init_chat_model("openai:gpt-4.1")
Anthropic
%pip install -U "langchain[anthropic]"
import os
from langchain.chat_models import init_chat_model
_set_env("ANTHROPIC_API_KEY")
llm = init_chat_model("anthropic:claude-4-sonnet-20250514")
from typing import Annotated
from langchain_tavily import TavilySearch
from langchain_core.messages import BaseMessage
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
tool = TavilySearch(max_results=2)
tools = [tool]
llm_with_tools = llm.bind_tools(tools)
def chatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
graph_builder.add_node("chatbot", chatbot)
tool_node = ToolNode(tools=[tool])
graph_builder.add_node("tools", tool_node)
graph_builder.add_conditional_edges(
"chatbot",
tools_condition,
)
# Any time a tool is called, we return to the chatbot to decide the next step
graph_builder.add_edge("tools", "chatbot")
graph_builder.add_edge(START, "chatbot")
graph = graph_builder.compile()
from IPython.display import Image, display
try:
display(Image(graph.get_graph().draw_mermaid_png()))
except Exception:
# This requires some extra dependencies and is optional
pass
def stream_graph_updates(user_input: str):
for event in graph.stream({"messages": [{"role": "user", "content": user_input}]}):
for value in event.values():
print("Assistant:", value["messages"][-1].content)
while True:
try:
user_input = input("User: ")
if user_input.lower() in ["quit", "exit", "q"]:
print("Goodbye!")
break
stream_graph_updates(user_input)
except:
# fallback if input() is not available
user_input = "What do you know about LangGraph?"
print("User: " + user_input)
stream_graph_updates(user_input)
break
User: LangGraph は日本で流行ってる?
Assistant:
Assistant: {"query": "LangGraph 日本 人気", "follow_up_questions": null, "answer": null, "images": [], "results": [{"url": "https://weel.co.jp/media/tech/langgraph/", "title": "LangGraphとは?エージェントの使い方とワークフロー構築法を ...", "content": "classDef default fill:#f2f0ff,line-height:1.2\n\n classDef first fill-opacity:0\n\n classDef last fill:#bfb6fc\n\n=== 対話開始 ===\n\n3回の対話後に終了します。Ctrl+Cでいつでも終了できます。\n\n現在の状態: {'count': 0, '最新メッセージ': 'あなたは親切なアシスタントです。日本語で簡潔に回答してください。'}\n\n質問を入力してください: LangGraphって何?\n\n現在の状態: {'count': 0, '最新メッセージ': 'LangGraphって何?'}\n\n対話 1\n\nAIの回答: LangGraphは、言語処理や自然言語生成のタスクに特化したグラフベースのモデルやフレームワークを指します。具体的には、テキストデータの関係や構造を可視化し、より効果的に言語理解をサポートするための技術です。このようなツールは、コンテンツの解析や生成、対話システムなどで利用されます。 [...] Image 43: suno 音楽生成AI【Suno AI】初心者でも簡単に楽曲作成!使い方や商用利用、V4について分かりやすく解説 165.2k件のビュー\n Image 44: DALL·E3 chatgpt openaiDALL-E 3とは?使い方・日本語対応・プロンプトのコツまでやさしく解説 86.8k件のビュー\n Image 45: StableLM 解説 使い方【Stable LM】エロにも使える最先端のLLMとは?各モデルの説明から使い方まで徹底解説! 47.5k件のビュー\n\nランキングページへ\n\nImage 46: Recruit\n\n 急上昇\n 月間\n 殿堂入り\n\n集計期間:1週間 [...] Image 58: Napkin AI ビジネスプレゼン視覚化ナプキン、AIでビジネスプレゼンを視覚化\n Image 59: 低コスト・小型マルチモーダルAI「Llama 3-V」が話題! 低コスト・小型マルチモーダルAI「Llama 3-V」が話題!\n Image 60: Microsoft Florence-2 COCOデータセット Azure AIチームMicrosoft、統一ビジョンモデルFlorence-2発表\n\nランキングページへ\n\n検索\n\n検索\n\n[]( [](\n\nWEELのノウハウ\n\n[]( [](\n\n[]( 情シス・AI担当者向け\n\n 導入フェーズ\n 活用フェーズ\n 開発フェーズ\n\n[]( 生成AI×業界\n\n エンタメ業界\n 不動産業界\n 製造業\n 医療業界\n 広告業界\n 建設業界\n 教育業界\n 物流業界\n 自動車業界\n 観光業界\n 金融業界\n\n[]( 生成AI×職業\n\n[]( [](\n\n[]( [](\n\nImage 61\n\nImage 62\n\n[](\n\nImage 63\n\n[](", "score": 0.5065188, "raw_content": null}, {"url": "https://note.com/hashtag/langgraph", "title": "「#langgraph」の人気タグ記事一覧 - note", "content": "人気の記事一覧 · 初めてのLangGraph · うさぎでもわかる Googleが本格参戦! · Agent Frameworkはどれを使うべきか [タスク性能編] · AI Agent フレームワーク大戦:次世代", "score": 0.486015, "raw_content": null}], "response_time": 1.5}
Assistant: 現時点で「LangGraph」は日本でも注目が集まりつつある技術ですが、「爆発的に流行している」とまでは言えません。
日本語の情報サイト(WEELやnoteなど)でも「LangGraph」に関する解説記事や初歩的な使い方の記事が増えており、AIやエージェント分野に関心のある技術者・開発者の間では徐々に話題になっています。ただし、一般層やビジネス界で広く知れ渡っている状況ではなく、今後さらに普及が進むかは今後の動向次第といえるでしょう。
要約:
- 技術者やAI開発コミュニティで話題になり始めている
- 一般的な流行にはまだ至っていない
- 日本語での解説記事や使い方ガイドは徐々に増えてきている
もし具体的な活用事例や日本での導入事例などが知りたい場合は、さらに詳細をお調べしますのでお知らせください。
Congratulations! 検索エンジンを使用して必要に応じて更新情報を取得できる、LangGraph の会話エージェントを作成しました。より幅広いユーザの質問を処理できるようになりました。To inspect all the steps your agent just took, check out this LangSmith trace.
以上