AI エージェントは、LLM の出力がワークフローを制御するようなプログラムです。
AI を使用した効率的なシステムは LLM に何らかの種類の現実世界へのアクセスを提供する必要があります : 例えば、外部情報を取得するために検索ツールを呼び出したり、タスクを解決するために特定のプログラムに作用する可能性です。言い換えれば、LLM は自律性を持つ必要があります。エージェント型プログラムは LLM にとって外界へのゲートウェイです。
smolagents : コンセプト・ガイド : エージェントとは何か?🤔
作成 : クラスキャット・セールスインフォメーション
作成日時 : 08/24/2025
バージョン : v1.21.1
* 本記事は github.com/huggingface/smolagents の以下のページを独自に翻訳した上で、補足説明を加えてまとめ直しています :
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

◆ お問合せ : 下記までお願いします。
- クラスキャット セールス・インフォメーション
- sales-info@classcat.com
- ClassCatJP
smolagents : コンセプト・ガイド : エージェントとは何か?🤔
エージェント型システムへのイントロダクション
AI を使用した効率的なシステムは LLM に何らかの種類の現実世界へのアクセスを提供する必要があります : 例えば、外部情報を取得するために検索ツールを呼び出したり、タスクを解決するために特定のプログラムに作用する可能性です。言い換えれば、LLM は自律性 (agency, 主体性) を持つ必要があります。エージェント型プログラムは LLM にとって外界へのゲートウェイです。
AI エージェントは、LLM の出力がワークフローを制御するようなプログラムです。
LLM を活用する任意のシステムは LLM 出力をコードに統合します。LLM の入力がコード・ワークフローに与える影響はシステムの LLM の agency のレベルです。
この定義によれば、「エージェント」は 0 か 1 かの離散ではないことに注意してください : 代わりに、”agency” は、ワークフローへの LLM へのパワーの強弱に応じた、連続的なスペクトルで進化します。
agency がシステムに渡り変化できる様子を下記の表でご覧ください :
| Agency レベル | 説明 | 短縮名 | コード例 |
|---|---|---|---|
| ☆☆☆ | LLM 出力はプログラムフローに影響を与えない | 単純なプロセッサ | process_llm_output(llm_response) |
| ★☆☆ | LLM 出力は if/else 分岐を制御 | ルーター | if llm_decision(): path_a() else: path_b() |
| ★★☆ | LLM 出力は関数実行を制御 | ツール呼び出し | run_function(llm_chosen_tool, llm_chosen_args) |
| ★★☆ | LLM 出力は反復とプログラム継続を制御 | 多段階エージェント | while llm_should_continue(): execute_next_step() |
| ★★★ | 一つのエージェント型ワークフローは別のエージェント型ワークフローを開始できる | マルチエージェント | if llm_trigger(): execute_agent() |
| ★★★ | LLM はコード内で動作し、独自のツールを定義したり他のエージェントを開始できます。 | コード・エージェント | def custom_tool(args): … |
他段階エージェントはこのようなコード構造を持ちます :
memory = [user_defined_task]
while llm_should_continue(memory): # this loop is the multi-step part
action = llm_get_next_action(memory) # this is the tool-calling part
observations = execute_action(action)
memory += [action, observations]
このエージェント型システムはループ内で動作し、各ステップで新しいアクションを実行します (アクションは単なる関数である事前定義済みツールの呼び出しも含めることができます)、これは観察によって、与えられたタスクを解決する満足できる状態に到達したことが明白になるまで続きます。他段階エージェントが単純な数学の問題を解ける方法の例が以下です :

✅ いつエージェントを使用するか / ⛔ いつそれらを避けるべきか
エージェントは、LLM にアプリケーションのワークフローを決定させる必要があるときに役立ちます。しかし、それらはやり過ぎ (overkill) である場合が多いです。問題は : 手元のタスクを効率的に解決するためにワークフローで柔軟性が本当に必要か? ということです。事前定義済みのワークフローが不十分である場合が多いなら、より柔軟性が必要であることを意味します。例を見てみましょう : サーフィン旅行の web サイトでカスタマーのリクエストを処理するアプリケーションを作成しているとします。
リクエストは (ユーザの選択に基づいて) 2 つのバケットのいずれかに属することを前もって知っていて、各々について事前定義済みのワークフローがあります。
- 旅行の知識を望みますか? ⇒ 知識ベースを検索するための検索バーへのアクセスを与える
- 営業と話しをしたいですか? ⇒ お問い合わせフォームに入力してもらう。
その決定論的なワークフローがすべてのクエリにフィットするならば、是非ともすべてをコーディングしてください!これは、予測不可能な LLM をワークフローに干渉させることで発生するエラーのリスクなしに、100 % 信頼性のあるシステムを提供します。単純さと堅牢性のために、エージェント型動作を使用しない方向で標準化することを勧めます。
しかしワークフローを前もってうまく決定できない場合はどうでしょう?
例えば、ユーザが次のように質問したい場合: 「月曜日にはいけますが、パスポートを忘れたので水曜日まで遅延する危険性があります、キャンセル保証をつけて、火曜日の朝に私と荷物をサーフィンに連れて行くことは可能ですか?」この質問は多くの要因に左右され、おそらく上記で事前定義された基準はどれもこの要求を満たしません。
事前定義済みのワークフローが不十分である場合が多いなら、より柔軟性が必要であることを意味します。
そこではエージェント型セットアップが役立ちます。
上記の例では、天気予報用の weather API、旅行距離を計算するための Google Maps API、従業員の稼働状況ダッシュボード、そして知識ベース上の RAG システムにアクセスできる他段階エージェントを作成できます。
最近まで、コンピュータプログラムは事前決定済みワークフローに制限され、if/else 分岐を積み上げることで複雑さに対処しようとしていました。「これらの数値の合計を計算する」あるいは「このグラフの最短経路を見つける」といった、極めて狭いタスクに焦点を当てていました。しかし実際には、上記の旅行の例のように、殆どの現実生活のタスクは事前に決定されたワークフローにはフィットしません。エージェント型システムは現実世界のタスクの広大な世界をプログラムに開放します!
Why smolagents ?
チェインやルーターのような低レベルのエージェント型ユースケースについては、すべてのコードを自分で記述できます。その方がシステムをより良く制御して理解できるため、遥かにうまくいくでしょう。
しかし、LLM に関数を呼び出させたり (「ツール呼び出し」)、LLM に while ループを実行させる (「多段階エージェント」) ような複雑な動作に進み始めると、幾つかの抽象化が必要になります :
- ツール呼び出しについては、エージェントの出力を解析する必要があるので、この出力は “Thought: I should call tool ‘get_weather’. Action: get_weather(Paris).” のような事前定義済み形式が必要です。これは事前定義済みの関数で解析し、LLM に与えられるシステムプロンプトはこの形式について知らせる必要があります。
- LLM 出力がループを決定するような多段階エージェントについては、最後のループ反復で起こったことに基づいて、LLM に異なるプロンプトを与える必要があります : そのためある種のメモリが必要です。
わかりましか?これら 2 つの例から、役立つ幾つかの項目の必要性を見出しました :
- もちろん、システムを強化するエンジンとして動作する LLM
- エージェントがアクセスできるツールのリスト
- LLM にエージェント型ロジックについてガイドするシステムプロンプト : ReAct のリフレクション -> アクション -> 観察のループ、利用可能なツール、使用するツール呼び出し形式 …
- 上記のシステムプロンプトにより示された形式で、LLM 出力からツール呼び出しを抽出するパーサー。
- メモリ
しかし待ってください、LLM に判断の余地を与えるので、間違いなく LLM は間違い犯すでしょう : そのためエラーロギングとリトライ機構が必要になります。
これらの要素はすべて、うまく機能するシステムを作成するために密接な連携が必要です。それが、これらすべてを連携させるために基本的なビルディングブロックを作成する必要があると、私たちが決定した理由です。
コード・エージェント
多段階エージェントでは、各ステップで、LLM は外部ツールの呼び出しの形でアクションを記述できます。これらのアクションを記述するための (Anthropic, OpenAI により使用される) 一般的な形式は、「どのツールをどの引数で実行するかを知るためにパースする、ツール名と使用する引数の JSON としてアクションを記述する」の様々なバリエーションです。
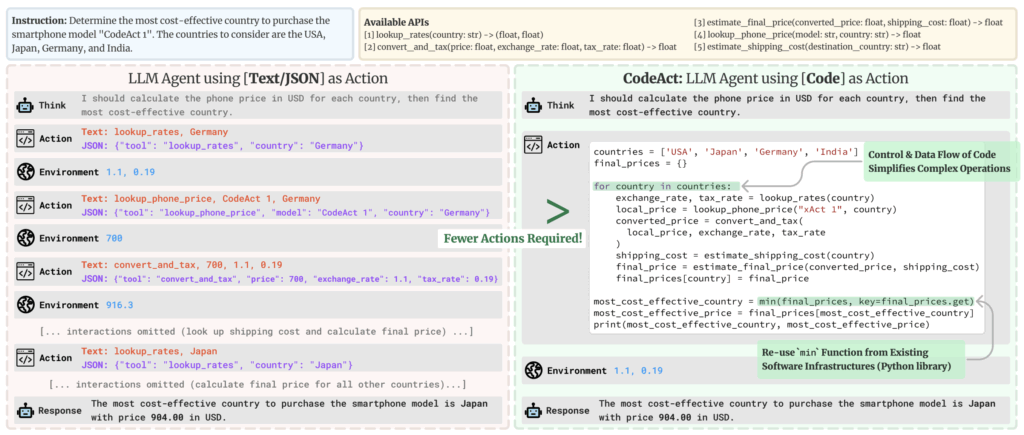
複数の研究論文 は、LLM のアクションをコードスニペットとして記述することは、より自然で柔軟な記述方法であることを示しています。
このため理由は、単純に、コンピュータにより実行されるアクションを表現するために私たちがコード言語を特別に作成したからです。言い換えれば、エージェントはユーザの問題を解決するためにプログラムを書いていきます : Python や JSON のブロックでのプログラミングのほうが簡単だと思いますか?
以下の図は、Executable Code Actions Elicit Better LLM Agents からの引用で、アクションをコードで記述する幾つかの利点を示しています :
JSON のようなスニペットでなくコードでアクションを記述することは以下の利点を提供します :
- 構成可能性 (Composability) : Python 関数を定義するのと同じように、JSON アクションを互いにネストしたり、後で再利用するために JSON アクションのセットを定義できますか?
- オブジェクト管理 : JSON の generate_image のようなアクションの出力をどのように保存しますか?
- 汎用性 (Generality) : コードは、コンピュータにさせることができるあらゆることをを単純に表現するために構築されています。
- LLM トレーニングデータでの表現 : LLM のトレーニングデータには既に多くの高品質なコードが含まれており、つまりこのためにトレーニング済みです!
以上