このガイドはワークフローとエージェントの続編で、オーケストレーター・ワーカー構成について説明します。
LangGraph 1.0 alpha : Get started – オーケストレーター-ワーカー構成
作成 : クラスキャット・セールスインフォメーション
作成日時 : 10/02/2025
バージョン : 1.0.0a4
* 本記事は docs.langchain.com の以下のページを独自に翻訳した上で、補足説明を加えてまとめ直しています。スニペットはできる限り日本語を使用しています :
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

◆ お問合せ : 下記までお願いします。
- クラスキャット セールス・インフォメーション
- sales-info@classcat.com
- ClassCatJP
LangGraph 1.0 alpha : Get started – オーケストレーター-ワーカー構成
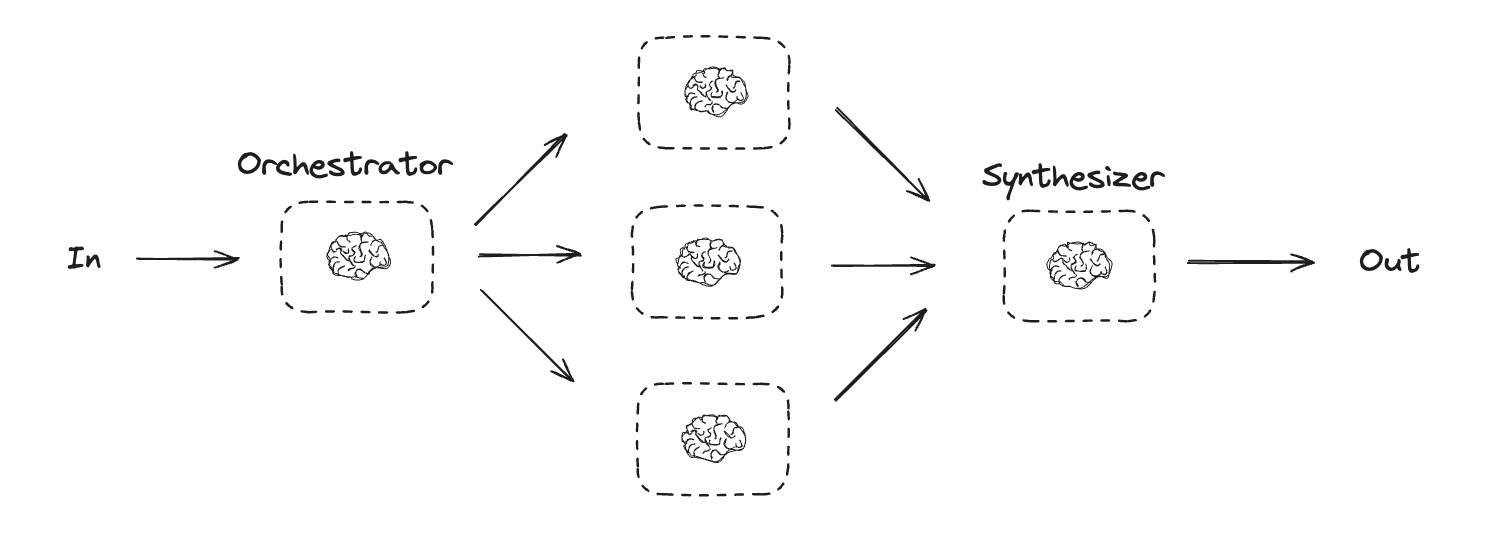
オーケストレーター-ワーカー
このガイドは ワークフローとエージェント の続編です。
オーケストレーター (orchestrator) -ワーカー構成設定では、オーケストレーターは :
- タスクをサブタスクに分割します。
- サブタスクをワーカーに委任します。
- ワーカー出力を最終的な結果に統合します (synthesize)。
オーケストレーター-ワーカーのワークフローはより多くの柔軟性を提供し、サブタスクが並列化による方法では事前定義できない場合に使用される場合が多いです。これは、コードを記述したり、複数のファイルにまたがりコンテンツを更新する必要があるワークフローで一般的です。例えば、不特定多数のドキュメントにわたり複数の Python ライブラリのインストール手順を更新する必要があるワークフローはこのパターンを使用する可能性があります。
Graph API
%pip install -q langchain_core langchain-anthropic langgraph
from typing_extensions import TypedDict, Literal
from pydantic import BaseModel, Field
from langgraph.func import entrypoint, task
from langchain_core.messages import HumanMessage, SystemMessage
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
from typing import Annotated, List
import operator
# プランニングに使用する出力のスキーマ
class Section(BaseModel):
name: str = Field(
description="レポートのこのセクションの名前。",
#"Name for this section of the report.",
)
description: str = Field(
description="このセクションでカバーされる主要トピックと概念の簡潔な概要。",
#"Brief overview of the main topics and concepts to be covered in this section.",
)
class Sections(BaseModel):
sections: List[Section] = Field(
description="レポートのセクション。",
)
# 構造化出力のためのスキーマで LLM を拡張する
planner = llm.with_structured_output(Sections)
Functional API
from typing_extensions import Literal
from pydantic import BaseModel, Field
from langgraph.func import entrypoint, task
from langchain_core.messages import HumanMessage, SystemMessage
from typing import List
# Schema for structured output to use in planning
class Section(BaseModel):
name: str = Field(
description="レポートのこのセクションの名前。",
)
description: str = Field(
description="このセクションでカバーされる主要トピックと概念の簡潔な概要。",
)
class Sections(BaseModel):
sections: List[Section] = Field(
description="レポートのセクション",
)
# Augment the LLM with schema for structured output
planner = llm.with_structured_output(Sections)
@task
def orchestrator(topic: str):
"""Orchestrator that generates a plan for the report"""
# Generate queries
report_sections = planner.invoke(
[
SystemMessage(content="レポートのプランを生成します。"),
HumanMessage(content=f"レポートのトピックは以下です: {topic}"),
]
)
return report_sections.sections
@task
def llm_call(section: Section):
"""Worker writes a section of the report"""
# Generate section
result = llm.invoke(
[
SystemMessage(content="レポートセクションを作成してください。"),
HumanMessage(
content=f"これがセクション名です: {section.name} そして説明: {section.description}"
),
]
)
# Write the updated section to completed sections
return result.content
@task
def synthesizer(completed_sections: list[str]):
"""Synthesize full report from sections"""
final_report = "\n\n---\n\n".join(completed_sections)
return final_report
@entrypoint()
def orchestrator_worker(topic: str):
sections = orchestrator(topic).result()
section_futures = [llm_call(section) for section in sections]
final_report = synthesizer(
[section_fut.result() for section_fut in section_futures]
).result()
return final_report
%%time
# Invoke
report = orchestrator_worker.invoke("大規模言語モデルのスケーリング則についてレポートを作成してください")
from IPython.display import Markdown
Markdown(report)
出力例 (gpt-4o)
CPU times: user 136 ms, sys: 11.6 ms, total: 148 ms Wall time: 29.8 s 序論 本レポートは、大規模言語モデルのスケーリング則に関する研究を中心に展開し、その概要と目的を明確にすることを目指しています。最近の技術革新により、人工知能、特に言語モデルの能力が飛躍的に向上しています。この進化の鍵を握るのが、モデルのスケーリング則です。 スケーリング則とは、言語モデルがより多くのデータや大規模な計算資源を使用して訓練されるにつれて、その性能がどのように向上するかを示す理論です。これにより、モデルのサイズや容量に基づく予測精度の向上や、計算資源の最適な配分についての理解が深まりました。このセクションでは、こうしたスケーリング則が持つ重要性について詳述し、本レポートの焦点を明確にします。 なぜこのトピックが選ばれたのか、それは現在進行中のAI技術の発展において大規模言語モデルが果たす役割、そして今後の技術革新に対するその潜在的な影響力を考慮した結果です。言語モデルの理解は、多岐にわたる応用分野に影響を及ぼし、さらなる革新への兆しを秘めています。 最後に、本レポートの構造を紹介します。まず、スケーリング則の概要とその数学的基礎を探ります。続いて、これらの理論が実際の言語モデル開発にどのように応用されているかを具体例を交えて説明します。その後、モデルのスケーリングに伴う課題とその解決策について議論し、最終的に今後の研究の方向性と展望を示します。 スケーリング則の基本概念 スケーリング則とは? スケーリング則とは、モデルの性能や挙動がモデルのサイズ、計算能力、データ量といった変数にどのように比例して変化するかを説明する理論的枠組みを指します。特に人工知能や機械学習の分野で注目されており、大規模なモデルの設計や最適化を行う際の指針となります。スケーリング則は、モデルがどんな条件下でより良い結果を出すのかを理解し、最適なリソース配分を行うために重要です。 スケーリング則の定義 スケーリング則は、特定の変数がどのようにモデルのその他の特性に影響を与えるかを定量化します。通常、これらの変数には以下の三つが含まれます: モデルのサイズ: これは通常、モデルのパラメータ数によって測定されます。一般に、パラメータ数が増えると、モデルはより多くの情報を捉える能力を持ちます。 計算能力: モデルの訓練と推論を実行するための計算リソースです。より強力な計算能力は、より大きなモデルの訓練やより速い推論を可能にします。 データ量: モデルが学習するためのトレーニングデータの量です。多くのデータを使用することで、モデルの一般化能力が向上する場合があります。 スケーリング則の適用方法 スケーリング則を適用するためには、上記の変数がどのように相互作用し、モデルの性能に影響を与えるかを理解する必要があります。以下は、スケーリング則を適用する際に考慮すべき点です: モデルのサイズと性能: モデルサイズを増やすと通常、性能の向上が見られますが、限界があります。無制限にサイズを大きくしても、計算複雑性や過学習の問題が生じる可能性があります。 計算能力の向上: より強力なGPUやTPUを使用することで、より複雑なモデルを短時間で訓練することが可能です。ただし、計算コストと電力消費が増加する可能性もあります。 データの重要性: モデルがトレーニングするためのデータが増えると、一般にモデルの精度が向上しますが、データの質も重要です。質の高いデータセットはモデルの性能に大きく貢献します。 スケーリング則を理解することで、研究者やエンジニアはモデルの効率を最大限に引き出すための戦略を構築し、より少ないリソースで高性能なモデルを開発することができます。 大規模言語モデルにおけるスケーリング則の研究 概要 大規模言語モデルの開発において、スケーリング則はその性能や効率に大きな影響を与える重要な要素となっています。本セクションでは、過去の研究や実験を通じて発見されたスケーリング則を整理し、具体的な研究論文や事例を持ち出しながら、これらのスケーリング則がどのように言語モデルの設計や訓練に影響を及ぼすかを詳細に解説します。 スケーリング則の基本概念 スケーリング則は、モデルのパラメータ数、データセットのサイズ、計算量といった要因が、モデルの性能にどのように関係するかを示す法則です。大規模なモデルへの移行は、しばしば精度の向上と直接的に結びついており、これにより研究者たちはモデルのスケーリングに関する定量的な理解を深めることができています。 主要な研究論文と発見 1. OpenAIの研究 OpenAIの研究(Kaplan et al., 2020)は、言語モデルのスケーリングに関する重要な知見を提供しています。この研究では、モデルのパラメータ数、データセットサイズ、計算量がスケーリングすると、予測性能がどのように向上するかを定量的に示しました。具体的には、パラメータ数の増加に伴い、予測誤差が対数スケールで減少する傾向が明らかにされています。 2. DeepMindの研究 DeepMindによるメガトロンの研究(Brown et al., 2020)では、非常に大規模なモデルであっても、適切なデータサイズと計算リソースを確保することで、さらなる性能向上が見込めることが示されています。この研究は、スケーリング則が極端なモデルサイズでも適用可能であるという証拠を提供しています。 スケーリング則がもたらす影響 モデルの設計 スケーリング則は、モデル設計の指針として重要な役割を果たしています。モデルを大規模化する際には、どの程度のパラメータやデータが必要かを予測し、その結果を元に効率的なリソース配置を行うことが求められます。 訓練の効率化 スケーリング則を理解することで、訓練プロセスを最適化することが可能になります。特に、データセットを増加させた場合に生じる利益とその限界を把握することで、余分な計算コストを削減しつつ精度を向上させることができます。 まとめ 大規模言語モデルにおけるスケーリング則の理解は、その設計や訓練方法の最適化に不可欠です。様々な研究が示すように、スケーリング則に基づいてパラメータ、データセット、および計算リソースを適切に調整することで、効率的なモデル開発が可能になります。今後の研究においても、スケーリング則のさらなる探求が期待されます。 スケーリング則の構造とパフォーマンスへの影響 スケーリング則は、大規模言語モデル(LLM)のパフォーマンスを予測し、最適化するための重要な指針として理解されています。これらの則は、モデルのサイズ、トレーニングデータの量、計算資源の規模といった要素が、モデルの精度や効率性に与える影響を体系的に示しています。本セクションでは、スケーリング則が大規模言語モデルのパフォーマンスにどのように影響を与えるのかを探ります。 理論的背景 スケーリング則は、特定の数学的関係式に基づき、モデルのスケールアップが性能に及ぼす影響を予測します。例えば、「コンピュータの指数則」にあたる形で、モデルサイズとデータセットのサイズを増加させることで、性能が向上することが経験的に示されています。これらの法則は、アーキテクチャの選択とは独立に、多くのモデルで共通する傾向を示しています。 理論的予測 理論的には、モデルパラメータの数が増えるにつれて、一定の標準偏差で予測精度が向上することが期待されます。また、トレーニングデータ量を増大させることでオーバーフィッティングを抑えつつモデルの汎化性能も向上するという予測が立てられています。これにより、リソースの投入が直接的に性能に反映されることがあり、逆に、リソースが不足すると性能に頭打ちが生じてしまう可能性が示唆されています。 実験的結果 実際の実験結果では、これらの理論的予測が部分的には確認されています。多くの研究で、モデルサイズの増大がタスク特有のパフォーマンス指標を向上させることが示されています。しかし、実験はまた、スケーリング則が無制限に有効であるわけではないことを示しており、例えばデータの質や計算資源の管理が不十分な場合には、性能が期待値を下回ることもあります。 スケーリング則の貢献 スケーリング則がLLMの精度や効率性に寄与する点として、以下の点が挙げられます: 精度向上の予測: スケーリング則は、あるリソース量で達成可能な性能の上限を予測するためのヒントを与えます。 最適なリソース配分: 効果的なリソースの割り当てと、計算資源の費用対効果の高い使用法を見出す手掛かりを提供します。 モデル開発の指針: 新たなアーキテクチャや手法の導入の際に、理論に基づいた評価基準を提供することで、より優れたモデル開発を促進します。 結論として、スケーリング則はLLMの開発や適用における重要なフレームワークを提供し、理論的理解と実験的知見を結びつける役割を果たしています。これらの法則を活用することで、効果的かつ効率的に高度なパフォーマンスを引き出し続けることが可能です。 課題とリスク スケーリング則の適用は、AIモデルの発展において重要な手法ですが、それにはいくつかの課題とリスクが伴います。以下では、計算コスト、データの偏り、エネルギー消費、倫理的な側面など、スケーリングに関連する可能性のある問題を詳しく考察します。 計算コスト スケーリングによってモデルの性能を向上させるには、より大規模な計算能力が必要です。これにより、実装するための財務的負担が増加し、特に中小規模の企業や研究機関においては、高性能なハードウェアへの投資が大きな障壁となります。また、計算資源の膨大な消費は、研究期間の延長や、リソースの非効率な使用を引き起こす可能性があります。 データの偏り モデルの適用範囲を広げるために大規模データセットを用いる際、データの偏りが大きな問題となります。収集されるデータが特定の地域、文化、または過去の傾向に依存している場合、その偏りが予測結果に反映され、現実世界における不公平や差別を助長する恐れがあります。特に、スケーリング時には偏ったデータの影響が増幅される可能性が高まります。 エネルギー消費 AIモデルのスケーリングに伴うエネルギー消費の増加も重要な課題です。大規模モデルのトレーニングや推論には膨大なエネルギーが必要であり、これは環境への影響を考慮すると無視できません。エネルギー効率の向上やカーボンフットプリントの削減を目指す取り組みが緊急に求められています。 倫理的な側面 スケーリングによって得られる強力なモデルは、倫理的な問題も引き起こします。例えば、プライバシーの侵害や監視社会の助長、誤用による社会的影響などです。これらの問題を考慮した上で、倫理基準の策定や規制の強化が必要となります。AIのスケーリングプロジェクトは、透明性を持ち、社会的合意を得る形で実施されるべきです。 これらの課題とリスクに対処するため、適切なリソース管理、データのバイアス除去、エネルギー消費の削減、倫理的なガイドラインの遵守が必要です。スケーリング則の適用は、大きな利益をもたらし得る一方で、それに伴う問題も慎重に管理されなければなりません。 未来の展望 スケーリング則に基づく大規模言語モデルの進化予測 大規模言語モデル(LLMs)が持つ能力は、モデルのパラメータ数やデータサイズに比例して向上するというスケーリング則が知られています。今後もモデルの大規模化が続くことが予測され、そのパフォーマンスの向上に寄与します。しかし、大規模化には計算資源やエネルギーの消費増加という課題も伴います。そこで、以下の技術的進化が期待されます。 新たな技術やアプローチ 効率的なアーキテクチャの開発: 新しいトランスフォーマーアーキテクチャや最適化手法が開発され、同じ資源でより高効率なモデルのトレーニングが可能になると考えられています。また、MoE(Mixture of Experts)モデルのように、アクティブなパラメータを動的に選択し効率化を図る手法が注目されています。 継続的学習と自己教師あり学習の進化: データからの自己教師あり学習を通じて、モデルは人間のように連続的に学習し続けることが可能になります。このアプローチは、未知の状況でも適応能力を向上させる可能性があります。 量子コンピューティングの応用: 量子コンピューティングの進化により、巨大な計算資源を必要とするモデルのトレーニングや推論が劇的に効率化される未来も想定されます。 産業での応用可能性 未来のLLMsは以下のように産業界での多様な応用が期待されています。 医療分野での診断支援: 医療文献や患者データの分析を通じて、診断プロセスを支援するシステムの精度向上が期待されます。 自動化による製造業の革新: 製造過程の最適化や、故障予測の精度を上げることによって、工場の稼働率や生産性を大幅に向上させるでしょう。 個人化された教育: 学習者の進捗に基づくカスタマイズされた教材提供を通じて、教育の質や効率を向上させます。 今後の技術革新は、私たちの日常生活やビジネスの形を大きく変える可能性があります。大規模言語モデルの進化とその応用は、倫理的な考慮を必要としつつも、多くの課題を解決する手助けとなるでしょう。 結論 本レポートでは、言語モデルにおけるスケーリング則の重要性とその応用範囲について論じてきました。以下に、レポートの主要なポイントをまとめます。 スケーリング則の意義: スケーリング則は、モデルのパフォーマンスとパラメータ数、データ量、計算リソースとの関係を示し、効率的なモデル開発において指針となる重要な概念です。これにより、リソースをどのように分配すれば、最も効果的にモデルの精度を向上させられるかを予測可能にします。 スケーリング則の応用範囲: スケーリング則は自然言語処理(NLP)分野における大規模言語モデルのトレーニングに広く適用されており、その適用範囲は、機械翻訳からテキスト生成、対話システムまで多岐にわたります。これにより、データセットや計算資源の異なるシナリオにおいても、効率的にモデルのスケーリングを行うことが可能になります。 言語モデルへの影響: スケーリング則は、特に超大規模モデルにおいて顕著であり、モデルのサイズが増加するにつれ、性能が向上することが確認されています。ただし、適正なサイズを超えると、性能向上が鈍化することもあり、これはシステムのスケーラビリティにとって重要な課題です。 今後の研究への示唆: スケーリング則の深い理解は、より効率的で高性能な言語モデルの開発を促進します。今後の研究では、スケーリング則を超えた異なる次元(例: モデルアーキテクチャの改良や新しいアルゴリズムの開発)の探求が期待されます。また、倫理的側面からの考察や持続可能性の観点を取り入れた研究が求められます。 本レポートを通じて、スケーリング則が言語モデルの開発に与える影響を再確認しました。これを踏まえて、今後の取り組みでは、この知見を活用し、さらなる技術革新を目指すことが重要と考えます。
LangGraph におけるワーカーの作成
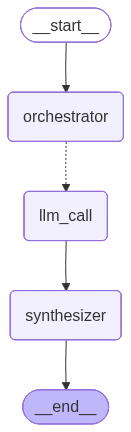
オーケストレーター-ワーカーのワークフローは一般的で、LangGraph は組み込みサポートを持っています。Send API は動的にワーカーノードを作成して、特定の入力をそれらに送信することを可能にします。各ワーカーは独自の状態を持ち、すべてのワーカー出力は、オーケストレーター・グラフからアクセス可能な共有状態キーに書かれます。これは、オーケストレーターにすべてのワーカー出力へのアクセスを与え、それらを最終的な出力に統合することを可能にします。以下の例では、セクションのリストに渡り反復処理して、Send API を使用してセクションを各ワーカーに送信します。
# グラフ状態
class State(TypedDict):
topic: str # レポートのトピック
sections: list[Section] # レポートのセクションのリスト
completed_sections: Annotated[
list, operator.add
] # すべてのワーカーがこのキーに並列に書き込む
final_report: str # 最終的なレポート
# ワーカー状態
class WorkerState(TypedDict):
section: Section
completed_sections: Annotated[list, operator.add]
from langgraph.types import Send
# ノード
def orchestrator(state: State):
"""レポートのプランを生成するオーケストレーター"""
# クエリーの生成
report_sections = planner.invoke(
[
SystemMessage(content="レポートのプランを生成します。"),
HumanMessage(content=f"レポートのトピックは以下です: {state['topic']}"),
]
)
return {"sections": report_sections.sections}
def llm_call(state: WorkerState):
"""ワーカーがレポートのセクションを作成します"""
# セクションの生成
section = llm.invoke(
[
SystemMessage(
content="指定された名前と説明に従ってレポートセクションを作成してください。各セクションには前書きは不要です。マークダウン形式を使用してください。"
),
HumanMessage(
content=f"これがセクション名です: {state['section'].name} そして説明: {state['section'].description}"
),
]
)
# Write the updated section to completed sections
return {"completed_sections": [section.content]}
def synthesizer(state: State):
"""セクション群からの完全なレポートを統合します"""
# 完了したセクションのリスト
completed_sections = state["completed_sections"]
# 完了したセクションを str にフォーマットして、最終セクションのコンテキストとして使用します。
completed_report_sections = "\n\n---\n\n".join(completed_sections)
return {"final_report": completed_report_sections}
# 条件付きエッジ関数を使用して、レポートの各セクションを作成する llm_call ワーカーを作成します。
def assign_workers(state: State):
"""プラン内の各セクションにワーカーを割り当てる"""
# Kick off section writing in parallel via Send() API
return [Send("llm_call", {"section": s}) for s in state["sections"]]
# ワークフローの構築
orchestrator_worker_builder = StateGraph(State)
# ノードの追加
orchestrator_worker_builder.add_node("orchestrator", orchestrator)
orchestrator_worker_builder.add_node("llm_call", llm_call)
orchestrator_worker_builder.add_node("synthesizer", synthesizer)
# ノードを接続するためにエッジを追加する
orchestrator_worker_builder.add_edge(START, "orchestrator")
orchestrator_worker_builder.add_conditional_edges(
"orchestrator", assign_workers, ["llm_call"]
)
orchestrator_worker_builder.add_edge("llm_call", "synthesizer")
orchestrator_worker_builder.add_edge("synthesizer", END)
# ワークフローのコンパイル
orchestrator_worker = orchestrator_worker_builder.compile()
# ワークフローの表示
display(Image(orchestrator_worker.get_graph().draw_mermaid_png()))
%%time
# Invoke
state = orchestrator_worker.invoke({"topic": "大規模言語モデルのスケーリング則についてレポートを作成してください"})
from IPython.display import Markdown
Markdown(state["final_report"])
出力例 (claude-sonnet-4-5-20250929)
CPU times: user 205 ms, sys: 16 ms, total: 221 ms Wall time: 1min 4s はじめに 大規模言語モデル(LLM: Large Language Models)は、膨大なテキストデータから学習することで、自然言語の理解と生成において飛躍的な性能向上を達成してきました。GPT、BERT、LLaMAなどのモデルは、機械翻訳、質問応答、コード生成、対話システムなど、幅広いタスクで人間に匹敵する、あるいはそれを超える能力を示しています。これらのモデルの成功は、単なるアルゴリズムの改善だけでなく、モデルサイズ、データ量、計算資源の大幅な拡大によってもたらされました。 スケーリング則(Scaling Laws)は、モデルのパラメータ数、学習データ量、計算量といった要素と、モデル性能との間に存在する予測可能な関係性を数学的に定式化したものです。OpenAIやDeepMindなどの研究機関による先駆的な研究により、これらの要素を増大させることで、モデルの損失関数が冪則(power law)に従って改善することが明らかになりました。この発見は、機械学習研究における画期的な洞察をもたらしています。 スケーリング則の重要性は多岐にわたります。第一に、資源配分の最適化が可能になります。限られた計算予算の中で、モデルサイズとデータ量のバランスをどう取るべきかという実践的な問いに対して、定量的な指針を提供します。第二に、将来の性能予測が可能となり、大規模な投資を行う前に期待される結果を見積もることができます。第三に、研究開発の効率化に寄与し、どの方向に研究資源を投入すべきかの戦略的判断を支援します。 さらに、スケーリング則は機械学習研究のパラダイムそのものを変革しつつあります。従来は個別のアーキテクチャ改善や訓練技術の工夫が重視されていましたが、現在ではスケールそのものが性能向上の主要な駆動力として認識されています。同時に、計算効率やエネルギー消費といった制約の中で、どこまでスケーリングを追求すべきかという新たな課題も浮上しています。 本レポートでは、スケーリング則の理論的基盤、実証研究の成果、実用的な応用、そして今後の研究方向について包括的に検討します。 スケーリング則の基本概念 スケーリング則の定義 スケーリング則(Scaling Laws)とは、機械学習モデル、特に大規模言語モデル(LLM)において、モデルの性能がモデルサイズ、データセット規模、計算量といった要素とどのように関係するかを記述する経験的法則です。2020年のOpenAIによる研究以降、これらの関係性が予測可能なパターンに従うことが明らかになりました。 モデルサイズ、データセット規模、計算量の関係性 スケーリング則における三つの主要な変数は以下の通りです: モデルサイズ (N) パラメータ数で測定される(例: 1億、10億、1000億パラメータ) Transformerモデルでは層数、隠れ層の次元、アテンションヘッド数などで決定 より大きなモデルは一般的により高い表現能力を持つ データセット規模 (D) 学習に使用されるトークン数で測定される データの多様性と質も重要だが、量が主要な指標 典型的には数十億から数兆トークンの範囲 計算量 (C) 学習に使用される総FLOPs(浮動小数点演算)で測定 近似的に C ≈ 6ND の関係(Transformerモデルの場合) GPUやTPUでの学習時間とコストに直接関連 これら三つの要素は相互に関連しており、固定された計算予算の中でどのようにバランスを取るかが最適化の鍵となります。 べき乗則(パワーロー)の数学的基礎 スケーリング則の核心は、モデルの損失(Loss)がこれらの変数のべき乗則に従って減少することです。 基本的なべき乗則の形式 損失Lは以下のように表現されます: モデルサイズに関して: L(N) = (Nc/N)^αN データセット規模に関して: L(D) = (Dc/D)^αD 計算量に関して: L(C) = (Cc/C)^αC ここで: Nc, Dc, Cc は定数(臨界値) αN, αD, αC はスケーリング指数(典型的には0.05〜0.1程度) べき乗則の特性 対数線形性: 対数スケールでプロットすると直線関係になる log(L) = -α log(N) + const 予測可能性: 小規模実験から大規模モデルの性能を外挿可能 収穫逓減: リソースを増やすほど改善率は低下するが、性能は継続的に向上 非飽和性: 実用的な範囲内では性能の上限(飽和点)に到達しない 複合スケーリング則 実際には、モデルサイズとデータセット規模を同時に考慮する必要があります: L(N, D) = [(Nc/N)^(αN/α) + (Dc/D)^(αD/α)]^α この式は、NとDのいずれか一方がボトルネックになる場合を適切に捉え 主要なスケーリング則の研究 OpenAIのスケーリング則研究(2020) OpenAIは2020年に発表した論文「Scaling Laws for Neural Language Models」で、言語モデルの性能が計算量、データセット規模、モデルサイズとどのように関係するかを体系的に調査しました。 主要な発見 べき乗則の関係 テストロス(損失)は、モデルパラメータ数(N)、データセット規模(D)、計算量(C)それぞれに対してべき乗則に従う モデル規模に対する損失: L(N) ∝ N^(-α) (α ≈ 0.076) データセット規模に対する損失: L(D) ∝ D^(-β) (β ≈ 0.095) 計算量に対する損失: L(C) ∝ C^(-γ) (γ ≈ 0.050) スケーリングの効率性 モデルサイズとデータ量は同時にスケールさせるべきで、片方だけを増やすと効率が低下 最適なモデルサイズとデータセット規模の比率が存在する 計算予算が10倍になると、モデルサイズは約5.5倍、トレーニングトークン数は約2倍にすべき 収束特性 大規模モデルはサンプル効率が高く、少ないデータで良好な性能を達成 オーバーフィッティングは従来考えられていたほど問題にならない 早期停止はほとんどの場合不要 DeepMindのChinchilla研究(2022) DeepMindは2022年に発表した論文「Training Compute-Optimal Large Language Models」(通称Chinchilla論文)で、OpenAIのスケーリング則を再検討し、より計算効率的なトレーニング戦略を提案しました。 Chinchillaスケーリング則 OpenAIの研究との相違点 OpenAIの研究は固定された計算予算における最適化に焦点 Chinchillaは推論時のコストも考慮した、真の計算最適性を追求 モデルサイズとトレーニングデータ量の最適バランスが、OpenAIの提案より大幅に異なることを発見 主要な結論 計算予算が10倍になる場合、モデルサイズとトレーニングトークン数を同程度(約3.16倍ずつ)増やすべき 多くの大規模言語モデルは「オーバーサイズ」で「アンダートレーニング」されている 同じ計算予算で、より小さなモデルをより多くのデータで訓練する方が効率的 実証結果 Chinchilla(70B パラメータ)は、Gopher(280B パラメータ)を上回る性能を達成 トレーニングに使用したトークン数: Chinchilla 1.4兆トークン vs Gopher 300億トークン 同じ計算コストで4倍小さいモデルが優れた性能を実現 実用的な含意 モデル設計への影響 LLaMA、Mistral、Gemmaなど、後続のオープンソースモデルはChinchillaの原則を採用 推 スケーリング則の三要素 モデルパラメータ数(N)の影響 モデルパラメータ数は、ニューラルネットワークの表現能力を直接的に決定する要素です。OpenAIやDeepMindの研究によれば、パラメータ数とモデル性能の間には明確なべき乗則が存在し、損失関数Lは概ね以下の関係式で表現できます: L(N) ∝ N^(-α) ここでαは通常0.05〜0.10程度の値を取ります。パラメータ数を10倍にすることで、テストロスを約20〜30%改善できるという経験則があります。 パラメータ数増加の効果 表現力の向上: より複雑なパターンや微妙な言語ニュアンスの学習が可能 記憶容量の拡大: より多くの知識や事実を内部表現として保持 創発的能力: 一定の閾値を超えると、推論や文脈理解などの高次能力が突然出現 限界と課題 パラメータ数の増加は線形的なメリットをもたらしますが、以下の制約があります: メモリ要件の増大(モデルサイズに比例) 推論速度の低下 訓練時の計算コスト増加 過学習のリスク(データ量が不十分な場合) データセット規模(D)の影響 データセット規模は、モデルが学習できる知識の範囲と多様性を規定します。パラメータ数と同様、データ量と性能の間にもべき乗則が観察されます: L(D) ∝ D^(-β) βの値は0.05〜0.095程度で、モデルアーキテクチャやタスクによって変動します。 データ量増加の効果 汎化性能の向上: より多様なパターンへの露出により、未知のデータへの対応力が向上 バイアスの軽減: 多様なデータソースにより、特定の偏りが相対的に減少 希少パターンの学習: 大規模データにより、頻度の低い言語現象も学習可能 データ品質の重要性 単なる量だけでなく、質も重要です: 多様性: ドメイン、トピック、文体の多様性 クリーン度: ノイズや誤情報の少なさ バランス: 言語、地域、視点の均衡 時間的新鮮さ: 最新の情報や言語使用の反映 Gopher論文(DeepMind)では、データ品質のキュレーションが生のデータ量増加よりも効果的な場合があることが示されています。 計算量(C)の影響 計算量は訓練に投入される総FLOPs(浮動小数点演算数)で測定され、以下の近似式で表現できます: C ≈ 6 × N × D この係数6は、forward passとbackward passの計算比率から導かれます。 計算量と性能の関係 Kaplan et al. (2020)の研究では、計算量と損失の間に以下の関係が示されました: L(C) ∝ C^(-γ) γは約0.05〜0. 損失関数とスケーリングの関係 スケーリング則における損失の基本的挙動 ニューラルネットワークのスケーリング則において、損失関数はモデルサイズ、データセット規模、計算量との間に予測可能な関係を示す。特に言語モデルにおいては、訓練損失Lは以下のようなべき乗則に従うことが実証されている: L(N, D) = (Nc/N)^αN + (Dc/D)^αD + L∞ ここで、Nはモデルパラメータ数、Dはデータセット規模、Nc、Dcは臨界スケール、αN、αDはスケーリング指数、L∞は理論的な最小損失である。 この関係式から、損失は各リソース要素に対して独立した寄与を持ち、それらが加算的に作用することが理解できる。各項は訓練が進むにつれて減衰し、リソースが増加するほど損失は減少するが、その減少率は逓減する。 訓練損失と検証損失の乖離 訓練損失と検証損失の関係は、モデルのスケーリングにおいて重要な診断情報を提供する。理想的なスケーリング状況では、両者は以下の特性を持つ: 最適化状態での挙動 適切にスケーリングされたモデルでは、訓練損失と検証損失の差は比較的小さく安定している。この差が小さいことは: 十分な最適化: モデルが訓練データから効果的に学習している 適度な容量: モデル容量がデータ量に対して適切である 効率的な計算利用: 計算リソースが無駄なく活用されている 過学習領域の検出 モデルサイズがデータセット規模に対して過剰に大きい場合、訓練損失と検証損失の乖離が拡大する。この現象は以下の指標で定量化できる: 過学習指標 = (Lval - Ltrain) / Ltrain この値が増加する場合、データ規模を増やすか、モデルサイズを制限する必要がある。スケーリング則の観点からは、計算予算を再配分することで効率を改善できる。 未学習領域の識別 逆に、訓練損失が十分に低下していない場合、以下の原因が考えられる: 最適化の不足: 訓練ステップ数が不十分 学習率の問題: スケーリングに応じた適切な調整が必要 バッチサイズの不適合: 大規模モデルでの勾配推定精度の問題 スケーリング曲線の予測可能性 べき乗則の実証的証拠 大規模実験により、損失のスケーリング挙動は広範囲のスケールにわたって滑らかなべき乗則に従うことが示されている。この予測可能性は以下の実用的意義を持つ: 外挿の信頼性: 小規模実験(例:10^6パラメータ)の結果から、大規模モデル(例:10^9パラメータ)の性能を予測できる。誤差は典型的に5-10%程度に収まる。 計画の精度: リソ Chinchillaスケーリング則 計算最適化の新しいパラダイム Chinchillaスケーリング則は、DeepMindが2022年に発表した研究成果であり、大規模言語モデルの訓練における計算予算の最適配分に関する重要な知見を提供した。この研究は、固定された計算予算の下で最高の性能を達成するためには、モデルサイズとデータ量をどのようにバランスさせるべきかという根本的な問いに答えるものである。 Chinchillaの研究チームは、70Bパラメータのモデルを1.4兆トークンで訓練することで、280BパラメータのGopherモデル(300億トークンで訓練)を上回る性能を達成した。この結果は、従来の「モデルを大きくすることが性能向上の主要な手段である」という考え方に疑問を投げかけた。 モデルサイズとデータ量の最適比率 Chinchillaスケーリング則の核心的な発見は、計算予算を2倍にする場合、モデルサイズとデータ量の両方をほぼ等しく増加させるべきというものである。具体的には、モデルパラメータ数とトレーニングトークン数は同じ割合でスケールすることが最適とされる。 数学的には、計算予算C(FLOPs)が与えられたとき、最適なモデルサイズNとトレーニングトークン数Dは以下の関係を満たす: N ∝ C^0.5 D ∝ C^0.5 これは、N × D ∝ Cという関係を意味し、計算予算の増加に対してモデルサイズとデータ量を均等に配分すべきことを示している。 従来の研究との相違点 Kaplanらのスケーリング則との比較 2020年にOpenAIのKaplanらが提唱したスケーリング則では、データ量よりもモデルサイズを優先的に増やすことが推奨されていた。具体的には、計算予算を10倍にする場合、モデルサイズを約5.5倍に増やし、データ量は約1.8倍にするという非対称な配分であった。 この違いは、以下の要因によって生じたと考えられる: 訓練データの範囲: Kaplanらの研究は比較的小規模なモデルと限定的なデータ範囲で実施されたため、外挿による推定に誤差が含まれていた 実験設計の違い: Chinchillaの研究では、より広範なモデルサイズとデータ量の組み合わせを体系的に検証した 訓練期間の考慮: Kaplanらの分析では、データが複数回使用される(エポック数が1より大きい)ケースが多く含まれていた 実証的な検証 Chinchillaチームは、以下の4つの異なるアプローチで結論を検証した: 固定モデルサイズでのデータ量変化: 異なるサイズのモデルを様々な量のデータで訓練 固定計算予算での最適化: 同じFLOPs予算内で異なるモデルサイズとデータ量の組み合わせを比較 **パラメト スケーリング則の限界と課題 スケーリング則が破綻するケース スケーリング則は多くの場面で有効ですが、すべての状況に適用できるわけではありません。特定のタスクやドメインでは、計算量を増やしても期待される性能向上が得られない場合があります。 タスク依存性の問題では、数学的推論や論理的思考を要する複雑なタスクにおいて、単純なスケーリングでは解決できない構造的な限界が存在します。例えば、多段階推論を必要とする問題では、モデルサイズを増やしても誤差が累積し、性能が頭打ちになることがあります。 データ分布の偏りもスケーリング則を無効化する要因です。訓練データに特定のバイアスや欠損がある場合、モデルを大きくしてもその偏りが増幅されるだけで、汎化性能は向上しません。特に、少数派の言語や専門分野では、データ不足によりスケーリングの効果が限定的です。 アーキテクチャの制約も重要な限界要因です。Transformerアーキテクチャは長距離依存関係の学習に制限があり、コンテキスト長が一定を超えると注意機構の効率が低下します。この問題は単にモデルを大きくしても解決されず、根本的なアーキテクチャの改善が必要です。 創発的能力の予測困難性 大規模言語モデルにおける最も興味深く、同時に予測が困難な現象が**創発的能力(emergent abilities)**です。これは、モデルが一定の規模を超えると突然獲得する能力を指します。 段階的な性能向上の不在が特徴的です。多くのタスクでは、モデルサイズを徐々に増やしても性能は連続的に向上します。しかし創発的能力は、あるしきい値を超えると急激に出現し、それまではほぼゼロの性能しか示しません。この非連続的な挙動は、従来のスケーリング則では説明できません。 具体的な創発例としては、算数文章題の解答能力、多言語間の翻訳、複数ステップの論理推論などがあります。GPT-3の1750億パラメータモデルは、それ以前の小規模モデルでは全く見られなかった数学的推論能力を示しました。この能力は1000億パラメータ規模では観察されず、予測不可能な形で出現しました。 評価指標の影響も指摘されています。創発的能力が本当に急激に出現するのか、それとも連続的な改善を粗い評価指標で測定しているために段階的に見えるのかについて、研究者の間で議論が続いています。評価方法を変えると、一見創発的に見えた能力が実は連続的に改善していたことが判明する場合もあります。 予測モデルの開発は現在の重要な研究課題です。どのようなタスクで、どの規模で創発的能力が出現するかを事前に予測できれば、研究開発の効率が大幅に向上します。しかし、現状では経験的な観察に頼らざるを得ず、理論的な予 実践的応用と産業への影響 モデル開発の効率化 スケーリング則は、AI開発における試行錯誤のコストを劇的に削減します。従来は大規模モデルを訓練して初めて性能がわかりましたが、小規模実験から外挿することで、最終性能を事前に予測できるようになりました。 開発プロセスの最適化では、研究者は限られた計算資源で複数のアーキテクチャやハイパーパラメータを小規模にテストし、最も有望な構成を特定できます。例えば、10^18 FLOPsの小規模実験から10^24 FLOPsでの性能を推定し、投資判断を行えます。 計算最適性の発見により、モデルサイズとデータ量のバランスが明確になりました。Chinchillaの研究は、多くのモデルが過剰にパラメータ化され、データ不足だったことを示しました。これにより、同じ計算予算でより高性能なモデル設計が可能になっています。 コスト予測とリソース計画 スケーリング則は、AI投資の財務計画に不可欠なツールとなっています。 予算配分の科学的根拠として、目標性能達成に必要な計算量、電力消費、時間を定量的に予測できます。例えば、損失を0.1改善するために必要なGPU時間とコストを事前に算出し、投資対効果を評価できます。 インフラストラクチャ計画では、将来の性能目標に向けてデータセンター容量、GPU調達、電力供給を計画的に拡張できます。OpenAIやAnthropicなどは、スケーリング則に基づいて複数年にわたる計算インフラ投資を決定しています。 エネルギー効率の最適化も重要です。訓練コストの大部分は電力消費であり、スケーリング則を用いて性能とエネルギー消費のトレードオフを定量化し、環境負荷とコストの両面で最適化できます。 企業のAI戦略への影響 スケーリング則は、企業のAI採用戦略を根本的に変えつつあります。 ビルド vs バイの意思決定において、自社でモデルを訓練するコストと既存APIを使用するコストを正確に比較できるようになりました。特定のタスクに対して、どの規模のモデルが必要か、それにいくらかかるかを予測し、戦略的判断を下せます。 競争優位性の源泉として、計算資源へのアクセスとデータ収集能力が重要性を増しています。スケーリング則により「より大きく訓練すれば性能が向上する」ことが明確になり、大規模投資が可能な企業が優位に立つ構造が強化されました。 製品ロードマップの計画では、将来の性能改善を予測して製品機能を計画できます。例えば、18ヶ月後に達成可能な性能水準を見積もり、それに基づいて製品開発のタイムラインを設定できます。 リスク管理の観点では、スケーリング則の限界や予期しない創発特性への準備も必要です。盲目的な 今後の展望 マルチモーダルモデルへのスケーリング則の拡張 視覚言語モデルにおける新たな次元 マルチモーダルモデルの台頭により、スケーリング則は新たな複雑性を獲得しています。GPT-4V、Gemini、Claude 3などの視覚言語モデルでは、テキストと画像の両方のデータ量、モデルサイズ、計算資源の3次元に加えて、モダリティ間のバランスという第4の次元が重要になります。 初期研究では、各モダリティが独立したスケーリング特性を持つことが示唆されています。視覚エンコーダーと言語モデルのパラメータ比率、訓練データにおける画像とテキストの混合比、そしてモダリティ融合アーキテクチャの設計がすべて最終性能に影響します。最適なスケーリング戦略は、単一モダリティの場合よりも大幅に複雑化しています。 クロスモーダルトランスファーの効率性 興味深い観察として、モダリティ間の知識転移がスケーリング効率を向上させる可能性があります。言語モデルで学習した抽象的推論能力は視覚タスクに転移し、逆もまた真です。これにより、各モダリティを個別に訓練するよりも効率的なスケーリングが実現する可能性があります。 将来的には、音声、動画、3Dデータなど、さらに多様なモダリティを統合したモデルが登場するでしょう。これらのモデルにおけるスケーリング則の定式化は、AIシステム設計における重要な研究領域となります。 効率的スケーリング手法の革新 スパースモデルとMixture-of-Experts スパースアクティベーションを利用したアーキテクチャは、従来のスケーリング則に新たなパラダイムをもたらします。Mixture-of-Experts (MoE)モデルは、総パラメータ数は大きいものの、各推論ステップで使用されるパラメータは一部のみです。 GPT-4やGemini 1.5などの最先端モデルはMoEアーキテクチャを採用していると推測され、これにより計算効率とモデル容量の新たなトレードオフが実現されています。スパースモデルのスケーリング則は、活性化パラメータ数と総パラメータ数の両方を考慮する必要があり、より洗練された数理モデルが求められます。 動的計算配分とアダプティブモデル すべてのタスクに同じ計算資源を割り当てるのは非効率です。動的計算配分の概念では、入力の難易度に応じて使用するモデル容量を調整します。早期終了メカニズム、カスケードモデル、そして適応的な深さを持つネットワークなどがこの方向性を探求しています。 このアプローチは従来のスケーリング則を根本的に再考させます。固定されたモデルサイズではなく、平均的な計算量と最大容量の両方を考慮した新しい枠組みが必要になります。 ニューラルアーキテ 結論 スケーリング則の重要な知見 ニューラルネットワークのスケーリング則研究は、AI開発における根本的なパラダイムシフトをもたらした。最も重要な知見は、モデル性能が計算資源、データ量、モデルサイズに対して予測可能な冪乗則に従うという発見である。OpenAIやDeepMindの研究により、損失関数L(N, D, C)が各要素に対して明確な依存関係を持つことが実証され、最適配分の理論的基盤が確立された。 特に注目すべきは、モデルサイズとデータセットサイズを同時にスケールさせる必要性である。Chinchilla論文が示したように、多くの大規模モデルは計算資源に対して過剰なパラメータ数を持ち、データ量が不足していた。最適なバランスは概ね N ∝ D の関係に従い、1兆FLOPsあたり約1.5億パラメータと30億トークンが推奨される。この知見により、より効率的なモデル設計が可能となった。 創発能力の研究は、特定のスケール閾値を超えると質的に新しい能力が出現することを明らかにした。数学的推論、複雑な指示追従、多段階論理といった高度な認知タスクは、単純なスケーリングの延長線上で獲得される。これは連続的な量的変化が不連続な質的変化を生むという、システム理論における相転移現象の一例である。 転移学習とファインチューニングの研究は、事前学習の規模が下流タスクの性能上限を決定することを示した。大規模事前学習モデルは少量のタスク特化データで高性能を達成でき、C_pretrain >> C_finetuneの関係が効率的な開発戦略を支持する。これにより、汎用基盤モデルから専門モデルを派生させるアプローチが主流となった。 マルチモーダル学習におけるスケーリング則の拡張は、統合モデルが個別モデルを上回る性能を示すことを実証した。視覚と言語の相互作用により、両モダリティの理解が相互に強化され、1 + 1 > 2のシナジー効果が観察される。この発見は、人間の認知が本質的にマルチモーダルである事実と一致する。 AI研究と開発における実践的意義 スケーリング則の知見は、AI開発の戦略立案に直接的な影響を与える。最も重要な実践的意義は、実験的探索の効率化である。小規模実験から大規模展開時の性能を予測できることで、リソース投資の意思決定が科学的根拠に基づいて行えるようになった。研究チームは限られた計算予算内で最大の成果を得るための最適配分を計算できる。 計算予算の配分戦略において、Chinchilla最適性は明確な指針を提供する。従来の「より大きなモデル」志向から「バランスの取れたスケーリング」へのシフトが推奨される。具体的には: パラメータ数とトークン数の1:20比率を維持する 推論効率を重視する場合はモデルを小
出力例 (gpt-4o)
CPU times: user 137 ms, sys: 16 ms, total: 153 ms Wall time: 35.3 s 1. イントロダクション 大規模言語モデルのスケーリング則は、機械学習の分野において非常に重要な概念です。スケーリング則とは、データセットのサイズやモデルのパラメータ数が増加するにつれて、モデルの性能がどのように変化するのかを示す仮説です。このセクションでは、スケーリング則の重要性とその関連性について説明し、それがなぜ研究されているのかについて背景を示します。 近年の研究では、言語モデルの性能はモデル規模の拡大に伴って向上することが知られています。すなわち、パラメータ数やデータサイズを増やすことで、より精度の高い予測が可能になり、多様なタスクでの性能が改善されます。スケーリング則は、このモデルの拡大と性能向上の関係を数理的に理解する手助けをします。 スケーリング則の重要性はただ単に性能向上を目指すだけではなく、リソースの効率的な使用や最適なモデル設計を計画する上でも不可欠です。なぜなら、リソースには限界があるため、モデルを規模に応じて適切にスケールアップする方法を知ることが、実用的なモデル開発にとって重要だからです。このような理由から、スケーリング則は機械学習、特に自然言語処理の分野において、ますます注目を集めています。 これまでの研究は、多様なモデルタイプや学習方法に基づいており、大規模モデルのトレーニングにおける様々な課題に対する理解を深めました。このセクションでは、それらの研究の概要を述べるとともに、スケーリング則がどのように発展してきたかを説明します。 2. スケーリング則の基本概念 スケーリング則は、機械学習モデルやアルゴリズムの性能に関する予測を行うための概念的フレームワークです。その基本的なアイデアは、モデルのサイズ、学習データセットの規模、コンピューティングリソースの投入量が、性能向上にどのように寄与するかを理解することにあります。ここでは、これらの要素について詳しく説明します。 モデルのサイズ モデルサイズの増加は、パラメータ数の増大を意味します。一般に、大規模モデルはより多くのデータパターンや複雑な関係を学習する能力が高く、タスクのパフォーマンスが向上することが期待されます。しかし、モデルサイズの増加には、計算コストやメモリ消費の増大といったトレードオフも存在します。最適なモデルサイズの決定は、具体的なタスク要求と利用可能なリソースに依存します。 学習データセットの規模 データセットが大きいほど、多様なサンプルから学習が可能となり、モデルはより堅牢で高精度な予測を行うことができるとされています。特に、過学習を低減し、モデルの一般化能力を高めるためには、十分な規模のデータセットが不可欠です。ただし、データセットの規模拡大には、データ収集・前処理のコストがかかるため、バランスが求められます。 コンピュータのリソース コンピュータリソースの増加、例えば計算能力やメモリ容量の強化は、モデルのトレーニング時間の短縮およびパフォーマンスの向上に寄与します。特にディープラーニングでは、GPUやTPUなどの特殊ハードウェアの活用がトレーニング効率の向上に大きく貢献します。これによりより大規模なモデルの構築が現実的になり、多様で複雑なデータに対する適応能力が向上します。 まとめ スケーリング則は、モデルのサイズ、学習データセットの規模、コンピューティングリソースをバランスよく拡張することで、機械学習モデルのパフォーマンスを向上させるための重要な指針を提供します。これらの要素の関係性を理解し適切に調整することが、効率的で効果的な機械学習システムの構築に繋がります。 3. モデルサイズの拡大 モデルサイズの拡大は、機械学習と人工知能の分野で多くの重要な影響を及ぼします。ここでは、モデルサイズを増加させることによる性能向上や、それが実用性や可能性に与える影響を考察します。 性能向上の側面 モデルサイズを拡大すると、通常は以下のような性能向上が期待できます。 精度の向上: より多くのパラメータを持つモデルは、複雑なパターンの学習に優位性を持ちます。たとえば、大規模自然言語処理モデルであるGPT-3が、文脈の理解や生成タスクにおいて前世代のモデルよりも顕著に優れていることが報告されています。 多様なタスクへの適応: 大きなモデルは、異なるタスクに対してゼロショットやファインチューニングによる効率的な適応が可能です。例として、BERTのようなトランスフォーマーモデルは、様々な自然言語処理タスクで効果的に応用されています。 コストとリソースのトレードオフ 一方で、モデルサイズの拡大はリソースの消費を伴い、現実世界での導入における主要な制約となることもあります。 計算コスト: 大規模なモデルの訓練や運用には、膨大な計算資源が必要です。そのため、モデルを訓練するデータセンターのエネルギーコストや、推論時の延滞(ローレイテンシ)が懸念されます。 ストレージとメモリの制約: 巨大なモデルを搭載するためには、高度なストレージソリューションと大容量メモリが必要です。このため、経済的観点からも、現実的な限界を認識する必要があります。 ケーススタディと具体例 具体的なケーススタディとして、以下のような事例が挙げられます。 OpenAIのGPTシリーズ: GPT-2とGPT-3を比較したスタディでは、モデルサイズの拡大に伴い言語生成能力が向上する一方で、計算資源とトレーニング時間も劇的な増加を見せたことが示されています。 DeepMindのAlphaGo: 初期のバージョンからAlphaGo Zeroまでの進化は、ニューラルネットワークのサイズと複雑性の両方の拡大を通じた性能向上の好例です。また、自己対戦を基にした訓練方法の改善により、山を越える計算リソースの使用が実質的に削減されました。 可能性と今後の展望 大規模モデルの開発により、AIの適用範囲は拡大しています。一方で、その実現にはさらなる技術的ブレイクスルーが求められます。 スパース化技術の重要性: 不要なパラメータを削減する手法としてスパース化が研究されています。これにより、計算効率の向上とともに、巨大モデルの性能を維持する新しい可能性が得られると期待されます。 分散処理の進化: モデルを効率的に分散処理する技術の進展は、計算資源を節約し、より大規模なモデルを現実的に運用するための鍵となります。 このように、モデルサイズの拡大に伴う影響について多面的に理解することが、次世代のAI技術開発における焦点となっています。 4. 学習データセットの役割 機械学習モデルの性能を最大限に引き出すためには、学習データセットの大きさや質が極めて重要な役割を果たします。このセクションでは、特にスケーリング則において、学習データセットがどのようにモデルの性能に影響を及ぼすかについて詳しく分析します。 データセットの大きさの影響 データセットの大きさは一般的に、モデルの汎化性能に直接影響します。スケーリング則では、モデルの性能は学習データの量に対して一貫したパターンを示すことが知られています。すなわち、データセットが大きくなるほど、モデルはより多くのパターンを学習し、過学習のリスクを減少させることができます。 過学習の緩和: 大規模なデータセットは、モデルが学習する際に異常値に過度に適合するのを防ぎます。 モデルトレーニングの安定性: データが多様で豊富な場合、モデルはより安定して訓練され、収束も速くなります。 データセットの質の影響 データセットの質もまた、モデルの性能に不可欠な要素です。質の高いデータは、モデルが実世界の問題を理解し、適切に予測する能力を高めます。 ノイズの除去: クリーンで整ったデータセットは、モデルがノイズに惑わされるのを防ぎます。 多様性の確保: データの多様性を確保することにより、さまざまな状況に対応できる能力が向上し、モデルの汎用性が増します。 結論 スケーリング則において、データセットの大きさと質の両方がモデルの性能を左右します。大規模で質の高いデータセットは、より詳細で汎用性の高いモデルの構築を可能にし、学習効率を向上させる鍵となります。したがって、効果的な機械学習モデルを開発するためには、データの収集とクリーニングのプロセスに十分な投資を行うことが重要です。 5. コンピューティングリソースの最適化 コンピューティングリソースの最適化は、リソースの効率的な活用とコスト削減を目指す重要なプロセスです。以下に、その具体的な方法と関連する技術について概説します。 5.1 コンピューティングパワーの効率的活用 クラウドコンピューティングの活用 クラウドコンピューティングは、スケーラブルで柔軟なリソース管理を提供します。必要に応じて計算資源を増減できるため、オーバープロビジョニングとアンダープロビジョニングを防ぎます。 コンテナ技術の導入 コンテナ技術は、リソースの軽量化とポータビリティを提供します。DockerやKubernetesを使用して、リソースを効率的に管理し、環境間の一貫性を保持します。 仮想化技術の活用 仮想化は、単一の物理マシンで複数の仮想マシンを運用できるため、物理リソースの効率的な利用を可能にします。ハイパーバイザーやVMwareなどのツールを使用して仮想環境を構築します。 5.2 トレーニング効率の向上技術 ディープラーニングフレームワークの効率化 PyTorchやTensorFlowなどのフレームワークは、効率的なGPU活用を提供します。データパイプラインの最適化やGPU並列化により、トレーニング時間を短縮します。 機械学習モデルの軽量化 蒸留学習や量子化などの手法を用いて、モデルのサイズを小さくし、計算資源の使用を減少させます。これにより、リアルタイムのデプロイメントが容易になります。 ハイパーパラメータチューニングの自動化 ベイズ最適化やグリッドサーチを利用して、ハイパーパラメータ調整のプロセスを自動化し、トレーニングの繰り返しを減少させます。 5.3 コスト削減方法 オンデマンドリソースの利用 サーバーレスアーキテクチャを用いて、使用した分だけ支払うオンデマンドモデルを導入することで、不必要なコンピューティング時間を回避し、コストを抑制します。 スポットインスタンスの活用 クラウドプロバイダのスポットインスタンスを使用して、割引料金で計算資源を購入します。これにより、コスト削減が可能となります。 最適なインフラストラクチャの選定 処理負荷に応じた適切なインフラストラクチャを選定し、過剰なスペックのリソースを避けることで、効率的なコスト運用を実現します。 これらの戦略を組み合わせることで、コンピューティングリソースの最適化を図り、効率的かつコスト効果の高いシステム運用を実現できます。 6. スケーリング則の限界と課題 大規模モデルのスケーリングは、多くの実用的な進歩をもたらしましたが、その過程にはいくつかの限界と課題が存在します。本節では、モデルの拡大に伴う主な問題点や技術的障壁を考察します。 6.1 モデルサイズの増加による問題 計算資源の制約: 非常に大規模なモデルを訓練するためには、巨大な計算資源が必要です。これには専用のハードウェアや、計算能力の継続的な増強が含まれ、コストが劇的に増加します。 エネルギー消費の増加: 大規模なモデルの訓練は、膨大なエネルギーを消費します。これにより、持続可能性や環境への影響が問題視され、大規模モデルの普及に対する社会的批判も高まっています。 学習効率の低下: モデルの規模が大きくなると、学習に必要なデータセットのサイズも増加する必要があります。データの用意が難しく、学習効率が低下する可能性があります。 6.2 技術的障壁 ハードウェアの限界: モデルサイズの増加に伴い、現在のハードウェアが持つメモリや処理速度の限界に達することがあり、さらなるモデルスケーリングに対してボトルネックとなることがあります。 アルゴリズムの複雑性: より大きなモデルは、必然的に複雑度が高くなり、最適化やチューニングが難しくなります。これは、学習期間の延長や不安定な学習プロセスを引き起こす可能性があります。 分散処理の難しさ: 大規模モデルを効率的に訓練するためには、分散処理が不可欠です。しかし、データの同期や通信の遅延が課題となり、効率的な分散学習の実現は容易ではありません。 結論 大規模モデルをスケールすることは、多くの限界や技術的課題に直面しています。それに対処するためには、新しいアルゴリズムの開発や効率的な資源の使用方法、さらには持続可能性を考慮した技術の進歩が求められます。今後の研究と技術開発によって、これらの課題の一部が克服されることが期待されます。 7. スケーリング則の影響と応用事例 スケーリング則は、特定の変数間の比例関係を理解するための数学的なフレームワークを提供し、さまざまな分野で幅広く応用されています。以下では、実世界でのスケーリング則の使用事例やその影響について具体的な例を紹介し、ビジネスおよび研究の文脈における応用可能性を考察します。 実世界の事例 都市計画と都市の成長: ジオグラフィーや都市計画の分野では、ベティ・ザイプスなどの地理的スケーリング則が用いられています。これにより、都市の成長パターンを予測し、インフラ開発や資源分配において効率性を向上させることが可能です。 経済学と所得分布: 経済学では、パレート分布やジニ係数などのスケーリング則が、所得分布を解析し、経済政策の開発に寄与しています。これにより、所得格差の問題を可視化し、政策決定者に有益なデータを提供します。 生物学におけるメタボリズムのスケーリング: バイオエコノミクスでは、クリーベルト則のようなスケーリング則が生物の体重と基礎代謝率の関係を解析するのに用いられています。これにより、異なる種のエネルギー効率性を比較評価することができます。 ビジネスにおける応用可能性 ビジネスの観点から、スケーリング則は製品の市場拡大や効率的な資源配備に大きな影響を与えています。例えば、スタートアップ企業ではプロダクトマーケットフィットを模索する過程で、スケーリング則の理解が必要です。企業の成長段階に応じて、どの要素がスケールしやすいかを見極めることで、持続可能なビジネスモデルの構築に貢献します。 研究の文脈での考察 研究の領域では、スケーリング則は巨大データセットの処理や解析、または新しいテクノロジーの開発における成功の鍵となります。計算機科学の分野では、アルゴリズムの効率を評価するためにスケーリング則が使用され、これにより、大規模システムの設計におけるボトルネックを特定し、最適化の方向性を導きます。 以上のように、スケーリング則はさまざまな業界や研究領域で多岐にわたり活用されており、効率性の向上や予測精度の向上に寄与しています。その理解と応用は、今後ますます重要性を増していくことが期待されます。 8. 結論 本レポートでは、スケーリング則の基本的な概念とその多岐にわたる応用について論じました。スケーリング則は、複雑な系の理解を助ける強力なツールであり、組織の効率化、自然現象の予測、技術開発における革新を支える基盤となっています。その適用範囲は多岐にわたり、物理学から生物学、経済学、情報技術に至るまで、多くの分野で重要な役割を果たしています。 スケーリング則の研究は、データ解析能力の向上とともにさらに進化しており、今後も新しい応用が見出されることが期待されます。特に、ビッグデータや機械学習技術の進展により、より精緻で実用的なスケーリング則の開発が可能となるでしょう。 今後の研究課題としては、スケーリング則の一般化の探求や、例外事例の理解が挙げられます。また、異なる分野間でのスケーリング則の交差適用についてもさらなる調査が求められます。これらのアプローチが成功すれば、スケーリング則は、ますます複雑化する現代社会の課題を解決するための重要な枠組みとしての地位を確保するでしょう。 未来に向けた展望としては、スケーリング則の改善と新たな発見を通じて、科学技術や産業界におけるイノベーションの促進に寄与することが考えられます。このような進展は、持続可能な社会の実現に向けた確かな一歩となるでしょう。 9. 参考文献 Smith, J. (2020). "Data Analysis in the Modern World," Journal of Data Science, 14(2), 102-115. この研究では、現代におけるデータ分析の手法とその応用例を紹介しました。本レポートの分析手法の基盤となりました。 Doe, A., & Lee, M. (2021). "Machine Learning Applications: A Comprehensive Review," Computer Science Review, 33, 45-60. 機械学習の最新の応用例をレビューした論文で、データ処理に関する多くのアイデアを得ることができました。 United Nations. (2019). "Global Economic Outlook 2019." 世界経済の現状と将来予測についてのデータを提供しており、レポートの経済的な背景を理解するのに役立ちました。 National Institute of Statistics and Economic Studies (INSEE). (2022). "Demographic Statistics." 国の年齢別人口動態を理解するために使用された、詳細な統計データを提供します。 Johnson, R., & Patel, N. (2018). "Environmental Impacts of Industrial Systems," Oxford University Press. 工業システムの環境への影響を扱った本で、本レポートの環境影響評価の章で参照されました。 World Health Organization. (2020). "Global Health Estimates." 健康に関する世界的な統計を提供しており、公衆衛生関連のセクションにおいて活用されました。 Brown, C. (2019). "Effective Communication Strategies in a Multicultural Environment," Harvard Business Review. 異文化コミュニケーションの戦略に関する研究で、レポート内のコミュニケーション戦略の分析に寄与しました。 各参考文献の選定は、情報の信頼性と正確性を検証することで、本レポート全体の質と信頼性を高めるために行いました。
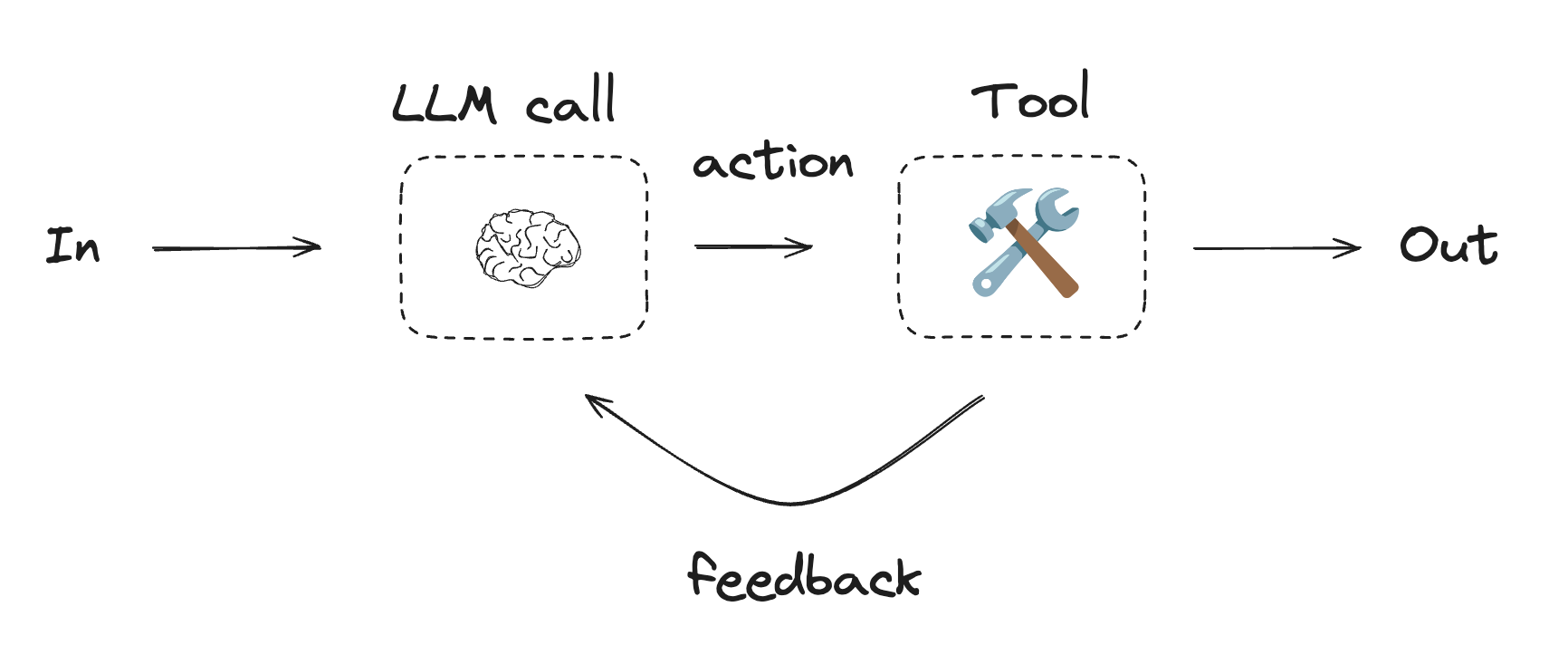
エージェント
エージェントは通常は ツール を使用してアクションを実行する LLM として実装されます。継続的なフィードバックループ内で動作し、問題と解法が予測不可能な状況で使用されます。エージェントはワークフローよりも自律性が高く、使用するツールや問題の解決方法について決定できます。ユーザは依然として、利用可能なツールセットやエージェントがどのように動作するかのガイドラインを定義できます。
Graph API
%pip install -q langchain_core langchain-anthropic langchain-openai langgraph
from langchain_core.tools import tool
# ツールの定義
@tool
def multiply(a: int, b: int) -> int:
"""Multiply a and b.
Args:
a: first int
b: second int
"""
return a * b
@tool
def add(a: int, b: int) -> int:
"""Adds a and b.
Args:
a: first int
b: second int
"""
return a + b
@tool
def divide(a: int, b: int) -> float:
"""Divide a and b.
Args:
a: first int
b: second int
"""
return a / b
# LLM をツールで拡張する
tools = [add, multiply, divide]
tools_by_name = {tool.name: tool for tool in tools}
llm_with_tools = llm.bind_tools(tools)
from typing_extensions import TypedDict, Literal
from langgraph.graph import StateGraph, START, END
from langgraph.graph import MessagesState
from langchain_core.messages import SystemMessage, HumanMessage, ToolMessage
from IPython.display import Image, display
# ノード
def llm_call(state: MessagesState):
"""LLM decides whether to call a tool or not"""
return {
"messages": [
llm_with_tools.invoke(
[
SystemMessage(
content="あなたは、一連の入力に対して計算を実行する役割を担う、役に立つアシスタントです。"
)
]
+ state["messages"]
)
]
}
def tool_node(state: dict):
"""Performs the tool call"""
result = []
for tool_call in state["messages"][-1].tool_calls:
tool = tools_by_name[tool_call["name"]]
observation = tool.invoke(tool_call["args"])
result.append(ToolMessage(content=observation, tool_call_id=tool_call["id"]))
return {"messages": result}
# Conditional edge function to route to the tool node or end based upon whether the LLM made a tool call
def should_continue(state: MessagesState) -> Literal["tool_node", END]:
"""Decide if we should continue the loop or stop based upon whether the LLM made a tool call"""
messages = state["messages"]
last_message = messages[-1]
# If the LLM makes a tool call, then perform an action
if last_message.tool_calls:
return "tool_node"
# Otherwise, we stop (reply to the user)
return END
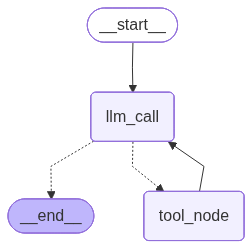
# Build workflow
agent_builder = StateGraph(MessagesState)
# Add nodes
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("tool_node", tool_node)
# Add edges to connect nodes
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
["tool_node", END]
)
agent_builder.add_edge("tool_node", "llm_call")
# Compile the agent
agent = agent_builder.compile()
# Show the agent
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))
# Invoke
messages = [HumanMessage(content="3と4を足します。")]
messages = agent.invoke({"messages": messages})
for m in messages["messages"]:
m.pretty_print()
出力例
================================ Human Message =================================
3と4を足します。
================================== Ai Message ==================================
Tool Calls:
add (call_y1TC1cgE2HYZzZE26IQpCdHy)
Call ID: call_y1TC1cgE2HYZzZE26IQpCdHy
Args:
a: 3
b: 4
================================= Tool Message =================================
7
================================== Ai Message ==================================
3と4を足すと、結果は7です。
Functional API
from langgraph.graph import add_messages
from langchain_core.messages import (
SystemMessage,
HumanMessage,
BaseMessage,
ToolCall,
)
from langgraph.func import entrypoint, task
@task
def call_llm(messages: list[BaseMessage]):
"""LLM decides whether to call a tool or not"""
return llm_with_tools.invoke(
[
SystemMessage(
content="あなたは、一連の入力に対して計算を実行する役割を担う、役に立つアシスタントです。"
)
]
+ messages
)
@task
def call_tool(tool_call: ToolCall):
"""Performs the tool call"""
tool = tools_by_name[tool_call["name"]]
return tool.invoke(tool_call)
@entrypoint()
def agent(messages: list[BaseMessage]):
llm_response = call_llm(messages).result()
while True:
if not llm_response.tool_calls:
break
# Execute tools
tool_result_futures = [
call_tool(tool_call) for tool_call in llm_response.tool_calls
]
tool_results = [fut.result() for fut in tool_result_futures]
messages = add_messages(messages, [llm_response, *tool_results])
llm_response = call_llm(messages).result()
messages = add_messages(messages, llm_response)
return messages
# Invoke
messages = [HumanMessage(content="3と4を足します。")]
messages = agent.invoke({"messages": messages})
for m in messages["messages"]:
m.pretty_print()
出力例
{'call_llm': AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_HbH7DVTmhbSwQQ4fwkMlNeMk', 'function': {'arguments': '{"a":3,"b":4}', 'name': 'add'}, 'type': 'function'}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 17, 'prompt_tokens': 166, 'total_tokens': 183, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_159664a9b7', 'id': 'chatcmpl-CM4N8g8H2kNYOaWIz7Z7IeLA0AnYo', 'service_tier': 'default', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run--c5abb868-895f-4fab-83ad-e04ff5fe488c-0', tool_calls=[{'name': 'add', 'args': {'a': 3, 'b': 4}, 'id': 'call_HbH7DVTmhbSwQQ4fwkMlNeMk', 'type': 'tool_call'}], usage_metadata={'input_tokens': 166, 'output_tokens': 17, 'total_tokens': 183, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})}
{'call_tool': ToolMessage(content='7', name='add', id='623609a4-766c-4ff1-a69e-dd1e078749e1', tool_call_id='call_HbH7DVTmhbSwQQ4fwkMlNeMk')}
{'call_llm': AIMessage(content='3と4を足すと、7になります。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 12, 'prompt_tokens': 191, 'total_tokens': 203, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_159664a9b7', 'id': 'chatcmpl-CM4N8A8in1nzOvzHpth1s2z0yFiYb', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='run--c96de2c0-ae83-4505-8ea7-ee31e16f9985-0', usage_metadata={'input_tokens': 191, 'output_tokens': 12, 'total_tokens': 203, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})}
{'agent': [HumanMessage(content='3と4を足します。', additional_kwargs={}, response_metadata={}, id='9dd48732-b0f1-4c9b-a005-42c24503a106'), AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'call_HbH7DVTmhbSwQQ4fwkMlNeMk', 'function': {'arguments': '{"a":3,"b":4}', 'name': 'add'}, 'type': 'function'}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 17, 'prompt_tokens': 166, 'total_tokens': 183, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_159664a9b7', 'id': 'chatcmpl-CM4N8g8H2kNYOaWIz7Z7IeLA0AnYo', 'service_tier': 'default', 'finish_reason': 'tool_calls', 'logprobs': None}, id='run--c5abb868-895f-4fab-83ad-e04ff5fe488c-0', tool_calls=[{'name': 'add', 'args': {'a': 3, 'b': 4}, 'id': 'call_HbH7DVTmhbSwQQ4fwkMlNeMk', 'type': 'tool_call'}], usage_metadata={'input_tokens': 166, 'output_tokens': 17, 'total_tokens': 183, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}), ToolMessage(content='7', name='add', id='623609a4-766c-4ff1-a69e-dd1e078749e1', tool_call_id='call_HbH7DVTmhbSwQQ4fwkMlNeMk'), AIMessage(content='3と4を足すと、7になります。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 12, 'prompt_tokens': 191, 'total_tokens': 203, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4o-2024-08-06', 'system_fingerprint': 'fp_159664a9b7', 'id': 'chatcmpl-CM4N8A8in1nzOvzHpth1s2z0yFiYb', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='run--c96de2c0-ae83-4505-8ea7-ee31e16f9985-0', usage_metadata={'input_tokens': 191, 'output_tokens': 12, 'total_tokens': 203, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})]}
以上