Gemini : 機能 : モデル調整 – モデル調整へのイントロ
作成 : クラスキャット セールスインフォメーション
作成日時 : 05/05/2024
* 本ページは、ai.google.dev の以下のページを独自に翻訳して、適宜、補足説明したものです :
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
![]()
- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Website: www.classcat.com ; ClassCatJP
Gemini : 機能 : モデル調整 – モデル調整へのイントロ
few ショット・プロンプティングのようなプロンプト設計ストラテジーは必要な結果を常に生成するとは限りません。モデル調整を使用して、特定のタスクに対するモデル性能を向上させたり、指示が十分でなく、望む出力を示すサンプルのセットを持つ場合にモデルが特定の出力要件に従うのを手助けします。
このページは Gemini API テキストサービスの背後でテキストモデルを調整する上でのガイダンスを提供します。
⭐️ Note : Tuning is available for the gemini-1.0-pro-001 and text-bison-001 models.
モデル調整がどのように動作するか
モデル調整のゴールは、特定のタスクに対してモデル性能をさらに向上させることです。モデル調整は、モデルにタスクの多くのサンプルを含む訓練データセットを提供することで機能します。ニッチなタスクについては、モデルを少量のサンプルで調整することによりモデル性能の大幅な改良を得られます。
訓練データはプロンプト入力と期待される応答出力を含むサンプルとして構造化される必要があります。Google AI Studio でサンプルデータを直接使用してモデルを調整することもできます。ゴールは、動作やタスクを示す多くのサンプルをモデルに与えることで、モデルが望ましい動作やタスクを模倣するように教えることです。
調整ジョブを実行する場合、モデルは、望ましいタスクを実行したり望ましい動作を学習するのに必要な情報をエンコードするのに役立つ追加パラメータを学習します。そしてこれらのパラメータは推論時に使用できます。調整ジョブの出力は新しいモデルです、これは新たに学習されたパラメータと元のモデルの効果的な組み合わせです。
サポートされるモデル
以下の基礎モデルがモデル調整をサポートします。単一ターンのテキスト補完のみがサポートされます。
- Gemini 1.0 Pro
- text-bison-001
モデル調整のワークフロー
モデル調整のワークフローは以下のようなものです :
- データセットの準備。
- Google AI Studio を使用している場合、データセットをインポートします。
- 調整ジョブを開始します。
モデル調整が完了したら、調整済みモデルの名前が表示されます。新しいプロンプトを作成するときそれを使用するモデルとして Google AI Studio で選択することもできます。
データセットの準備
訓練を始める前に、それでモデルを調整するデータセットが必要です。最高のパフォーマンスのためには、データセットのサンプルは高品質で、多様で、実際の入力と出力の見本である必要があります。
形式
データセットに含まれるサンプルは想定される実運用のトラフィックに一致する必要があります。データセットが特定の形式、キーワード、指示や情報を含む場合、実運用データも同じ方法で形式化されて同じ指示を含む必要があります。
例えば、データセットのサンプルが “question:” と “context:” を含む場合、実運用のトラフィックもまた、データセットサンプルで現れるように、”question:” と”context:” を同じ順序で含むように形式化される必要があります。コンテキストを除外すると、正確な質問がデータセットのサンプルにある場合でさえ、モデルはパターンを認識できません。
データセットの各サンプルにプロンプトか前文 (preamble) を追加することは調整済みモデルの性能を改良するのに役立てることもできます。注意してください、プロンプトや前文がデータセットに含まれる場合、それはまた推論時に調整済みモデルへのプロンプトに含まれている必要があります。
訓練データサイズ
モデルは 20 サンプルほど少なくても調整できて、一般に追加のデータは応答の品質を向上させます。アプリケーションに応じて 100 から 500 サンプルを目標にする必要があります。次の表は様々な一般的なタスクについてテキストモデルを調整するために推奨されるデータセットサイズを示します :
| タスク | データセットのサンプル数 |
|---|---|
| 分類 | 100+ |
| 要約 | 100-500+ |
| ドキュメント検索 | 100+ |
調整用データセットのアップロード
データは API を使用してインラインで渡されるか、Google AI Studio でアップロードされたファイル経由で渡されます。
Imoport ボタンを使用してファイルからデータをインポートするか、インポートする、サンプルを含む構造化プロンプトを調整用データセットとして選択します。
クライアント・ライブラリ
クライアントライブラリを使用するには、createTunedModel 呼び出しでデータファイルを供給します。ファイルサイズの上限は 4MB です。始めるには tuning quickstart with Python をご覧ください。
Curl
Curl を使用して REST API を呼び出すには、JSON 形式の訓練サンプルを training_data 引数に供給します。始めるには tuning quickstart with Curl をご覧ください。
高度な調整設定
調整ジョブを作成するとき、以下の高度な設定を指定することができます :
- Epochs (エポック) – 各サンプルが一度は処理されるように、訓練セット全体に渡る完全な訓練パス。
- バッチサイズ – 一回の訓練反復で使用されるサンプルのセット。バッチサイズはバッチのサンプル数を決定します。
- 学習率 – 各反復でモデルパラメータをどの程度強く調整するかをアルゴリズムに伝える浮動小数点数。例えば、0.3 の学習率は 0.1 の学習率よりも 3 倍強力に重みとバイアスを調整するでしょう。高い学習率と低い学習率は独自のトレードオフがあり、ユースケースに応じて調整する必要があります。
- 学習率の乗数 (multiplier) – 学習率の乗数はモデルの元の学習率を変更します。1 の値はモデルの元の学習率を使用します。1 より大きい値は学習率を増加させ、1 と 0 の間の値は学習率を低下させます。
推奨構成設定
次の表は基礎モデルを調整するために推奨される configuration を示します :
| ハイパーパラメータ | デフォルト値 | 推奨される調整 |
|---|---|---|
| エポック | 5 | 5 エポックの前に損失が平坦化 (plateau) し始める場合は、より小さい値を使用します。 |
| バッチサイズ | 4 | |
| 学習率 | 0.001 | 小さいデータセットには小さい値を使用します。 |
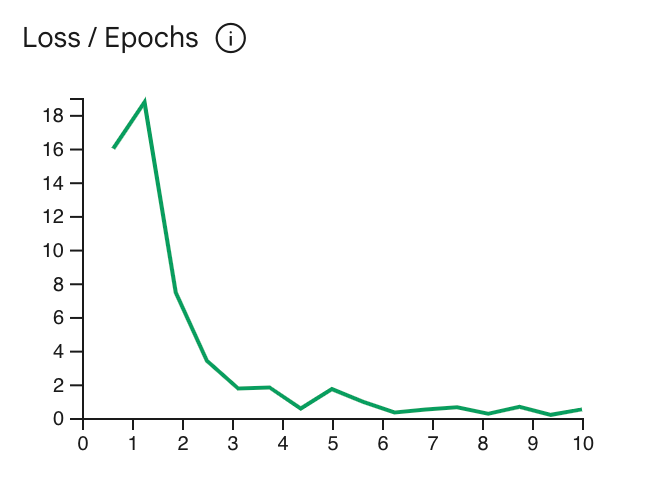
損失曲線は、各エポック後に訓練サンプルにおいて、モデルの予測が理想的な予測からどの程度外れているかを示します。理想的には、それが平坦化するすぐ前に、曲線の最も低い点で訓練を停止するのが望ましいです。例えば、下のグラフはおよそエポック 4-6 で損失曲線が平坦化することを示しています、これはエポックパラメータを 4 に設定しても同じ性能が得られることを意味します。
調整ジョブスタータスの確認
調整中のジョブのステータスは Google AI Studio UI の My Library タブか、Gemini API の調整モデルのメタデータプロパティを使用して確認できます。
以上