このチュートリアルでは「検索エージェント」を構築します。検索エージェントは、LLM にベクトルストアからコンテキストを取得するか、ユーザに直接応答するか判断させたい場合に便利です。
LangGraph : 例題 : エージェント型 RAG
作成 : クラスキャット・セールスインフォメーション
作成日時 : 06/22/2025
* 本記事は langchain-ai.github.io の以下のページを独自に翻訳した上で、補足説明を加えてまとめ直しています :
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
クラスキャット 人工知能 研究開発支援サービス ⭐️ リニューアルしました 😉

◆ お問合せ : 下記までお願いします。
- クラスキャット セールス・インフォメーション
- sales-info@classcat.com
- ClassCatJP
LangGraph : 例題 : エージェント型 RAG
このチュートリアルでは 検索エージェント を構築します。検索エージェントは、LLM にベクトルストアからコンテキストを取得するか、ユーザに直接応答するか判断させたい場合に便利です。
このチュートリアルの最後までには、以下を遂行します :
- 検索に使用するドキュメントを取得して前処理します。
- これらのドキュメントをセマンティック検索用にインデックス化してエージェント用の検索ツールを作成します。
- 検索ツールをいつ使用するか判断できるエージェント型 RAG システムを構築します。
セットアップ
必要なパッケージをダウンロードして API キーを設定します :
pip install -U --quiet langgraph "langchain[openai]" langchain-community langchain-text-splitters
import getpass
import os
def _set_env(key: str):
if key not in os.environ:
os.environ[key] = getpass.getpass(f"{key}:")
_set_env("OPENAI_API_KEY")
1. ドキュメントの前処理
- RAG システムで使用するドキュメントを取得します。Lilian Weng の優れたブログ から最も最近のページの 3 つを使用します。WebBaseLoader ユーティリティを使用してページの内容を取得することから始めます :
from langchain_community.document_loaders import WebBaseLoader urls = [ "https://lilianweng.github.io/posts/2024-11-28-reward-hacking/", "https://lilianweng.github.io/posts/2024-07-07-hallucination/", "https://lilianweng.github.io/posts/2024-04-12-diffusion-video/", ] docs = [WebBaseLoader(url).load() for url in urls]docs[0][0].page_content.strip()[:1000]"Reward Hacking in Reinforcement Learning | Lil'Log\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nLil'Log\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n|\n\n\n\n\n\n\nPosts\n\n\n\n\nArchive\n\n\n\n\nSearch\n\n\n\n\nTags\n\n\n\n\nFAQ\n\n\n\n\n\n\n\n\n\n Reward Hacking in Reinforcement Learning\n \nDate: November 28, 2024 | Estimated Reading Time: 37 min | Author: Lilian Weng\n\n\n \n\n\nTable of Contents\n\n\n\nBackground\n\nReward Function in RL\n\nSpurious Correlation\n\n\nLet’s Define Reward Hacking\n\nList of Examples\n\nReward hacking examples in RL tasks\n\nReward hacking examples in LLM tasks\n\nReward hacking examples in real life\n\n\nWhy does Reward Hacking Exist?\n\n\nHacking RL Environment\n\nHacking RLHF of LLMs\n\nHacking the Training Process\n\nHacking the Evaluator\n\nIn-Context Reward Hacking\n\n\nGeneralization of Hacking Skills\n\nPeek into Mitigations\n\nRL Algorithm Improvement\n\nDetecting Reward Hacking\n\nData Analysis of RLHF\n\n\nCitation\n\nReferences\n\n\n\n\n\nReward hacking occurs when a reinforcement learning (RL) agent exploits flaws or ambiguities in the reward function to ac"
- 取得したドキュメントを小さいチャンクに分割して、ベクトルストアにインデックス化します :
from langchain_text_splitters import RecursiveCharacterTextSplitter docs_list = [item for sublist in docs for item in sublist] text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder( chunk_size=100, chunk_overlap=50 ) doc_splits = text_splitter.split_documents(docs_list)doc_splits[0].page_content.strip()"Reward Hacking in Reinforcement Learning | Lil'Log\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\nLil'Log\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n|\n\n\n\n\n\n\nPosts\n\n\n\n\nArchive\n\n\n\n\nSearch\n\n\n\n\nTags\n\n\n\n\nFAQ"
2. 検索ツールの作成
分割されたドキュメントを作成したので、それらをセマンティック検索に使用するベクトルストアにインデックス化できます。
- in-memory ベクトルストアと OpenAI 埋め込みを使用します :
from langchain_core.vectorstores import InMemoryVectorStore from langchain_openai import OpenAIEmbeddings vectorstore = InMemoryVectorStore.from_documents( documents=doc_splits, embedding=OpenAIEmbeddings() ) retriever = vectorstore.as_retriever() - LangChain の事前構築済み create_retriever_tool を使用して検索ツールを作成します :
from langchain.tools.retriever import create_retriever_tool retriever_tool = create_retriever_tool( retriever, "retrieve_blog_posts", "Search and return information about Lilian Weng blog posts.", ) - Test the tool:
retriever_tool.invoke({"query": "types of reward hacking"})'(Note: Some work defines reward tampering as a distinct category of misalignment behavior from reward hacking. But I consider reward hacking as a broader concept here.)\nAt a high level, reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering.\n\nWhy does Reward Hacking Exist?#\n\nPan et al. (2022) investigated reward hacking as a function of agent capabilities, including (1) model size, (2) action space resolution, (3) observation space noise, and (4) training time. They also proposed a taxonomy of three types of misspecified proxy rewards:\n\nLet’s Define Reward Hacking#\nReward shaping in RL is challenging. Reward hacking occurs when an RL agent exploits flaws or ambiguities in the reward function to obtain high rewards without genuinely learning the intended behaviors or completing the task as designed. In recent years, several related concepts have been proposed, all referring to some form of reward hacking:'
3. クエリーの生成
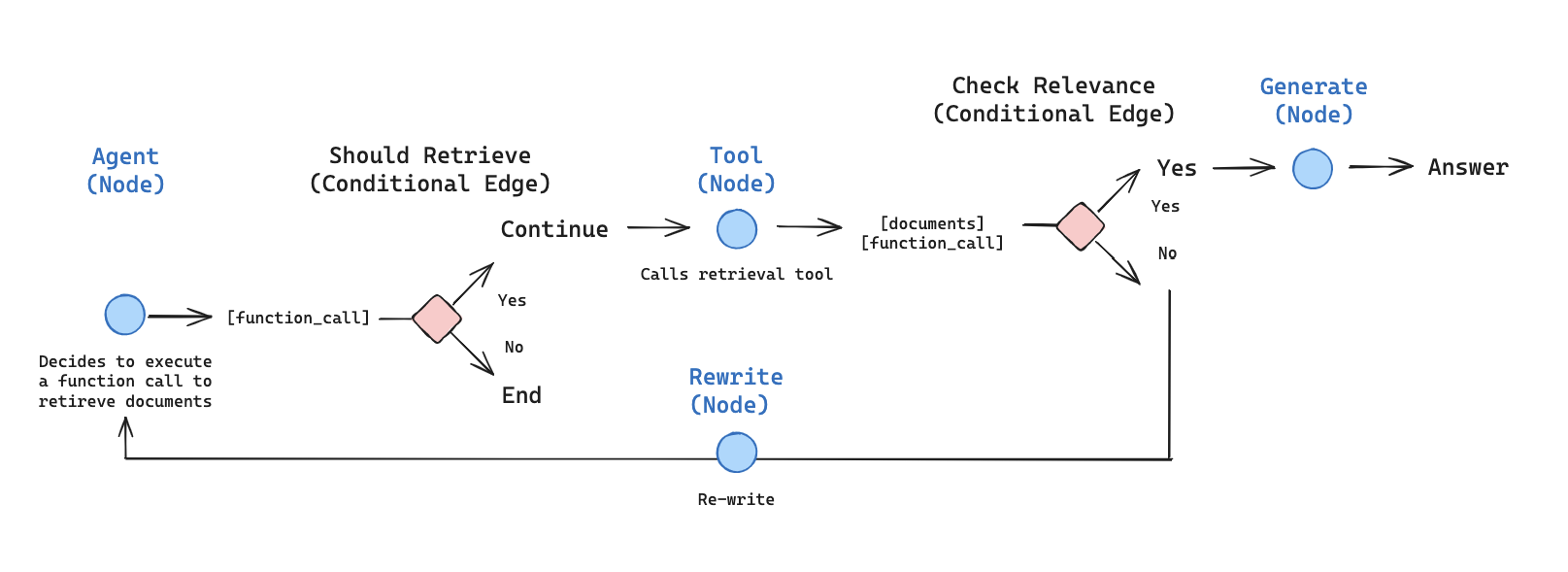
さて、エージェント型グラフのコンポーネント (ノード と エッジ) の構築を始めます。コンポーネントは MessagesState – チャットメッセージ のリストを持つメッセージキーを含むグラフ状態の上で動作することに注意してください。
- generate_query_or_respond ノードを構築します。それは LLM を呼び出して、現在のグラフ状態 (メッセージのリスト) に基づいてレスポンスを生成します。入力メッセージが与えられると、retriever ツールを使用して取得するか、ユーザに直接応答するかを決定します。bind_tools 経由で先に作成した retriever_tool へのアクセスをチャットモデルに与えていることに注意してください :
from langgraph.graph import MessagesState from langchain.chat_models import init_chat_model response_model = init_chat_model("openai:gpt-4.1", temperature=0) def generate_query_or_respond(state: MessagesState): """Call the model to generate a response based on the current state. Given the question, it will decide to retrieve using the retriever tool, or simply respond to the user. """ response = ( response_model .bind_tools([retriever_tool]).invoke(state["messages"]) ) return {"messages": [response]} - Try it on a random input:
input = {"messages": [{"role": "user", "content": "hello!"}]} generate_query_or_respond(input)["messages"][-1].pretty_print()================================== Ai Message ================================== Hello! How can I help you today?
- セマンティック検索を必要とする質問をします :
input = { "messages": [ { "role": "user", "content": "What does Lilian Weng say about types of reward hacking?", } ] } generate_query_or_respond(input)["messages"][-1].pretty_print()================================== Ai Message ================================== Tool Calls: retrieve_blog_posts (call_tYQxgfIlnQUDMdtAhdbXNwIM) Call ID: call_tYQxgfIlnQUDMdtAhdbXNwIM Args: query: types of reward hacking
4. ドキュメントのランク付け
- 取得ドキュメントが質問に関連するかを決定する 条件付きエッジ grade_documents を追加します。ドキュメントのランク付け (grading) には構造化出力スキーマ GradeDocuments を備えたモデルを使用します。grade_documents 関数はランク付けの決定 (generate_answer or rewrite_question) に基づいて進むべきノードの名前を返します :
from pydantic import BaseModel, Field from typing import Literal GRADE_PROMPT = ( "You are a grader assessing relevance of a retrieved document to a user question. \n " "Here is the retrieved document: \n\n {context} \n\n" "Here is the user question: {question} \n" "If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n" "Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question." ) class GradeDocuments(BaseModel): """Grade documents using a binary score for relevance check.""" binary_score: str = Field( description="Relevance score: 'yes' if relevant, or 'no' if not relevant" ) grader_model = init_chat_model("openai:gpt-4.1", temperature=0) def grade_documents( state: MessagesState, ) -> Literal["generate_answer", "rewrite_question"]: """Determine whether the retrieved documents are relevant to the question.""" question = state["messages"][0].content context = state["messages"][-1].content prompt = GRADE_PROMPT.format(question=question, context=context) response = ( grader_model .with_structured_output(GradeDocuments).invoke( [{"role": "user", "content": prompt}] ) ) score = response.binary_score if score == "yes": return "generate_answer" else: return "rewrite_question" - 無関係なドキュメントとともにこれを実行します :
from langchain_core.messages import convert_to_messages input = { "messages": convert_to_messages( [ { "role": "user", "content": "What does Lilian Weng say about types of reward hacking?", }, { "role": "assistant", "content": "", "tool_calls": [ { "id": "1", "name": "retrieve_blog_posts", "args": {"query": "types of reward hacking"}, } ], }, {"role": "tool", "content": "meow", "tool_call_id": "1"}, ] ) } grade_documents(input)'rewrite_question'
- 関連ドキュメントが以下のように分類されることを確認します :
input = { "messages": convert_to_messages( [ { "role": "user", "content": "What does Lilian Weng say about types of reward hacking?", }, { "role": "assistant", "content": "", "tool_calls": [ { "id": "1", "name": "retrieve_blog_posts", "args": {"query": "types of reward hacking"}, } ], }, { "role": "tool", "content": "reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering", "tool_call_id": "1", }, ] ) } grade_documents(input)'generate_answer'
5. 質問の書き換え
- rewrite_question ノードを作成します。retriever ツールは無関係なドキュメントを返す可能性があり、これは元のユーザ質問を改善する必要性を示しています。そのため、rewrite_question ノードを呼び出します :
REWRITE_PROMPT = ( "Look at the input and try to reason about the underlying semantic intent / meaning.\n" "Here is the initial question:" "\n ------- \n" "{question}" "\n ------- \n" "Formulate an improved question:" ) def rewrite_question(state: MessagesState): """Rewrite the original user question.""" messages = state["messages"] question = messages[0].content prompt = REWRITE_PROMPT.format(question=question) response = response_model.invoke([{"role": "user", "content": prompt}]) return {"messages": [{"role": "user", "content": response.content}]} - Try it out:
input = { "messages": convert_to_messages( [ { "role": "user", "content": "What does Lilian Weng say about types of reward hacking?", }, { "role": "assistant", "content": "", "tool_calls": [ { "id": "1", "name": "retrieve_blog_posts", "args": {"query": "types of reward hacking"}, } ], }, {"role": "tool", "content": "meow", "tool_call_id": "1"}, ] ) } response = rewrite_question(input) print(response["messages"][-1]["content"])What are the different types of reward hacking described by Lilian Weng, and how does she explain them?
6. 回答の生成
- generate_answer ノードを構築します: 評価チェックにパスすれば、元の質問と取得したコンテキストに基づいて最終的な回答を生成できます :
GENERATE_PROMPT = ( "You are an assistant for question-answering tasks. " "Use the following pieces of retrieved context to answer the question. " "If you don't know the answer, just say that you don't know. " "Use three sentences maximum and keep the answer concise.\n" "Question: {question} \n" "Context: {context}" ) def generate_answer(state: MessagesState): """Generate an answer.""" question = state["messages"][0].content context = state["messages"][-1].content prompt = GENERATE_PROMPT.format(question=question, context=context) response = response_model.invoke([{"role": "user", "content": prompt}]) return {"messages": [response]} - Try it:
input = { "messages": convert_to_messages( [ { "role": "user", "content": "What does Lilian Weng say about types of reward hacking?", }, { "role": "assistant", "content": "", "tool_calls": [ { "id": "1", "name": "retrieve_blog_posts", "args": {"query": "types of reward hacking"}, } ], }, { "role": "tool", "content": "reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering", "tool_call_id": "1", }, ] ) } response = generate_answer(input) response["messages"][-1].pretty_print()================================== Ai Message ================================== Lilian Weng says that reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering. These categories describe different ways in which an agent might exploit flaws in the reward system. Environment or goal misspecification involves unintended behaviors due to poorly specified objectives, while reward tampering involves directly manipulating the reward signal.
7. グラフをまとめる
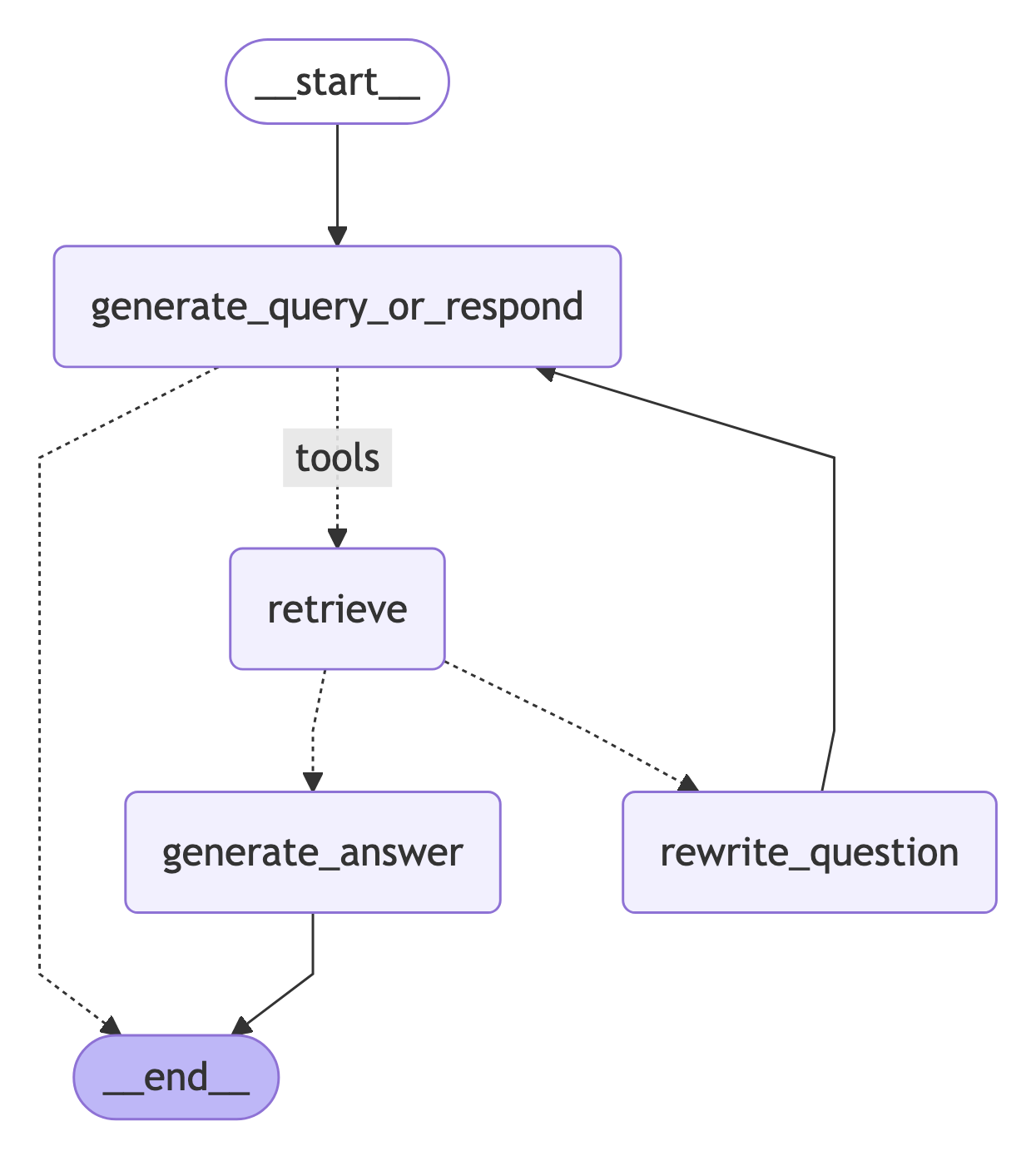
- generate_query_or_respond から始めて、retriever_tool を呼び出す必要があるか判断します
- tools_condition を使用して次のステップにルーティングします :
- generate_query_or_respond が tool_calls を返せば、retriever_tool を呼び出してコンテキストを取得します
- それ以外の場合は、ユーザに直接応答します。
- 取得したドキュメントの内容を質問への関連性について評価し (grade_documents)、次のステップにルーティングします :
- 関連性がない場合、rewrite_question を使用して質問を書き直してから、generate_query_or_respond を再度呼び出します。
- 関連性がある場合、generate_answer に進んで、取得したドキュメントとともに ToolMessage を使用して最終的なレスポンスを生成します。
from langgraph.graph import StateGraph, START, END
from langgraph.prebuilt import ToolNode
from langgraph.prebuilt import tools_condition
workflow = StateGraph(MessagesState)
# Define the nodes we will cycle between
workflow.add_node(generate_query_or_respond)
workflow.add_node("retrieve", ToolNode([retriever_tool]))
workflow.add_node(rewrite_question)
workflow.add_node(generate_answer)
workflow.add_edge(START, "generate_query_or_respond")
# Decide whether to retrieve
workflow.add_conditional_edges(
"generate_query_or_respond",
# Assess LLM decision (call `retriever_tool` tool or respond to the user)
tools_condition,
{
# Translate the condition outputs to nodes in our graph
"tools": "retrieve",
END: END,
},
)
# Edges taken after the `action` node is called.
workflow.add_conditional_edges(
"retrieve",
# Assess agent decision
grade_documents,
)
workflow.add_edge("generate_answer", END)
workflow.add_edge("rewrite_question", "generate_query_or_respond")
# Compile
graph = workflow.compile()
Visualize the graph:
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))
8. エージェント型 RAG の実行
for chunk in graph.stream(
{
"messages": [
{
"role": "user",
"content": "What does Lilian Weng say about types of reward hacking?",
}
]
}
):
for node, update in chunk.items():
print("Update from node", node)
update["messages"][-1].pretty_print()
print("\n\n")
Update from node generate_query_or_respond
================================== Ai Message ==================================
Tool Calls:
retrieve_blog_posts (call_NYu2vq4km9nNNEFqJwefWKu1)
Call ID: call_NYu2vq4km9nNNEFqJwefWKu1
Args:
query: types of reward hacking
Update from node retrieve
================================= Tool Message =================================
Name: retrieve_blog_posts
(Note: Some work defines reward tampering as a distinct category of misalignment behavior from reward hacking. But I consider reward hacking as a broader concept here.)
At a high level, reward hacking can be categorized into two types: environment or goal misspecification, and reward tampering.
Why does Reward Hacking Exist?#
Pan et al. (2022) investigated reward hacking as a function of agent capabilities, including (1) model size, (2) action space resolution, (3) observation space noise, and (4) training time. They also proposed a taxonomy of three types of misspecified proxy rewards:
Let’s Define Reward Hacking#
Reward shaping in RL is challenging. Reward hacking occurs when an RL agent exploits flaws or ambiguities in the reward function to obtain high rewards without genuinely learning the intended behaviors or completing the task as designed. In recent years, several related concepts have been proposed, all referring to some form of reward hacking:
Update from node generate_answer
================================== Ai Message ==================================
Lilian Weng categorizes reward hacking into two types: environment or goal misspecification, and reward tampering. She considers reward hacking as a broad concept that includes both of these categories. Reward hacking occurs when an agent exploits flaws or ambiguities in the reward function to achieve high rewards without performing the intended behaviors.
以上