このガイドはエージェント型システムの一般的なパターンをレビューします。これらのシステムを説明する際、「ワークフロー」と「エージェント」を区別することは有用です。
※ LangGraph 0.5 でドキュメント構成が大幅に変更されましたので、再翻訳しながら極力 Google Colab ベースで動作するようにまとめ直します。モデルは可能な限り最新版を利用し、プロンプトは日本語を使用します。
LangGraph 0.5 : エージェント開発 : ワークフローとエージェント
作成 : クラスキャット・セールスインフォメーション
作成日時 : 07/05/2025
* 本記事は langchain-ai.github.io の以下のページを独自に翻訳した上で、補足説明を加えてまとめ直しています :
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

◆ お問合せ : 下記までお願いします。
- クラスキャット セールス・インフォメーション
- sales-info@classcat.com
- ClassCatJP
LangGraph 0.5 : エージェント開発 : ワークフローとエージェント
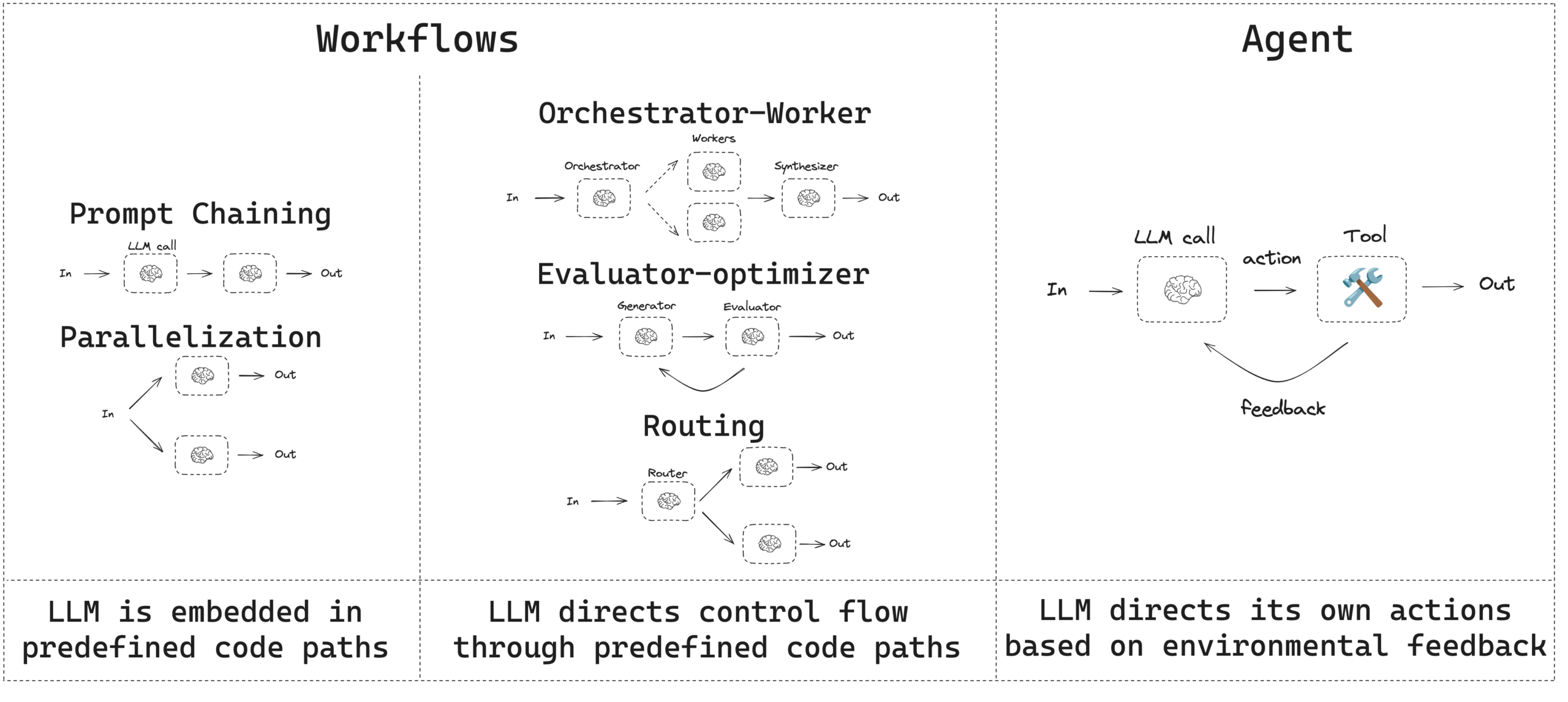
このガイドはエージェント型システムの一般的なパターンをレビューします。これらのシステムを説明する際、「ワークフロー」と「エージェント」を区別することは有用である可能性があります。この違いについて考える一つの方法は、Anthropic の Building Effective Agents ブログ記事でうまく説明されています :
ワークフローは、LLM とツールが事前定義されたコードパスを通してオーケストレーションされるシステムです。他方、エージェントは、LLM が自身のプロセスとツール使用を動的に指示し、タスクを遂行する方法の制御を維持システムです。
これらの違いを視覚化する単純な方法は以下です :
エージェントとワークフローを構築する際、LangGraph は永続性、ストリーミングそしてデバッグと配備のサポートを含む、多くのメリットを提供します。
セットアップ
構造化出力とツール呼び出しをサポートする 任意のチャットモデル を使用できます。以下では、Anthropic 用のパッケージのインストール、API キーの設定、そして構造化出力 / ツール呼び出しのテストのプロセスを示します。
インストール依存関係
%%capture --no-stderr
%pip install -U --quiet langchain_core langchain-anthropic langgraph
LLM の初期化
import os
import getpass
from langchain_anthropic import ChatAnthropic
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{var}: ")
_set_env("ANTHROPIC_API_KEY")
llm = ChatAnthropic(model="claude-4-sonnet-20250514")
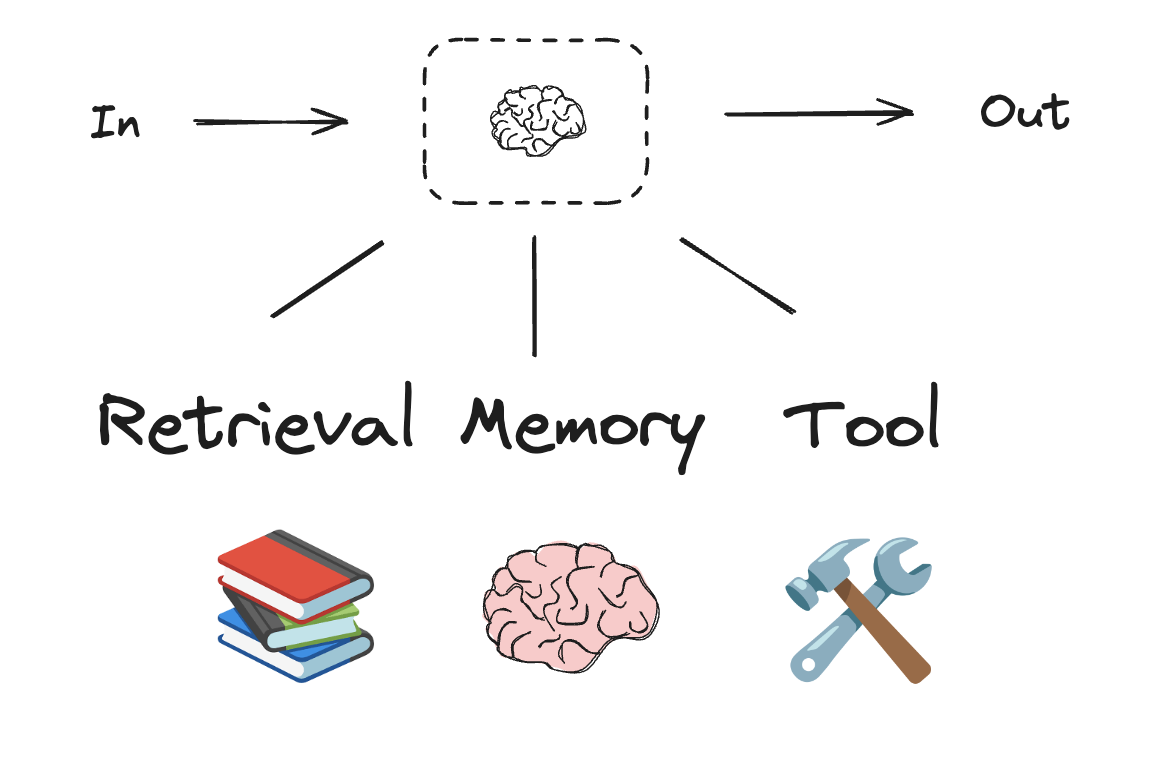
ビルディング・ブロック : 拡張 (Augmented) LLM
LLM は、ワークフローとエージェントの構築をサポートする拡張機能 (augmentations) を持っています。これは、Building Effective Agents の Anthropic ブログ記事からのこのイメージで示されるように、構造化出力 と ツール呼び出し を含みます :
# 構造化出力用スキーマ
from pydantic import BaseModel, Field
class SearchQuery(BaseModel):
search_query: str = Field(None, description="Query that is optimized web search.")
justification: str = Field(
None, description="Why this query is relevant to the user's request."
)
# 構造化出力用スキーマを使用して LLM を拡張する
structured_llm = llm.with_structured_output(SearchQuery)
# 拡張 LLM を起動
output = structured_llm.invoke("How does Calcium CT score relate to high cholesterol?")
# ツールの定義
def multiply(a: int, b: int) -> int:
return a * b
# ツールで LLM を拡張
llm_with_tools = llm.bind_tools([multiply])
# ツール呼び出しを発生させる (trigger) 入力で LLM を起動
msg = llm_with_tools.invoke("What is 2 times 3?")
# ツール呼び出しの取得
msg.tool_calls
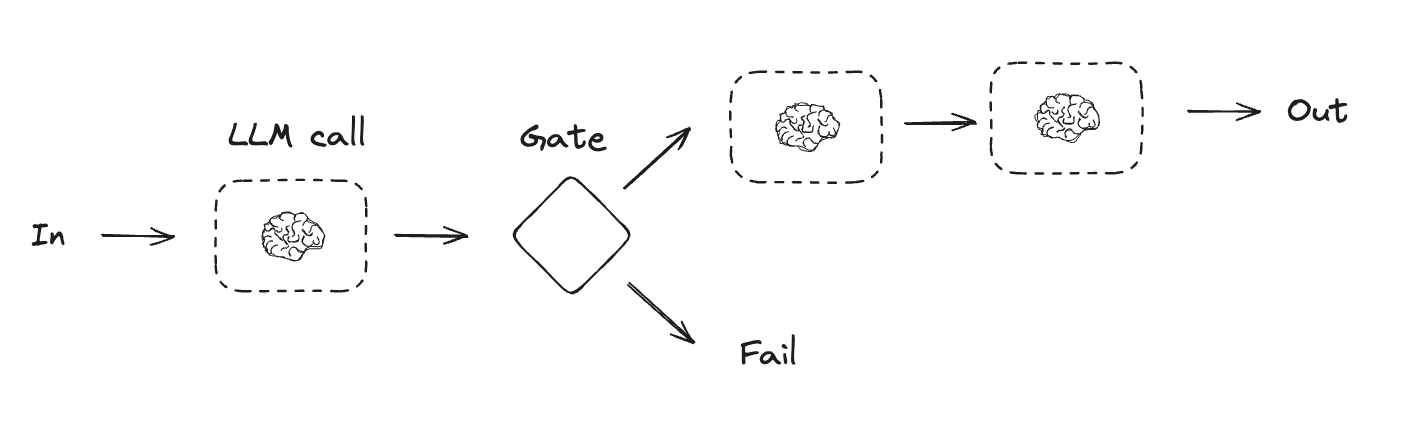
プロンプト連鎖 (chaining)
プロンプト連鎖では、各 LLM 呼び出しは前の呼び出しの出力を処理します。
次のように Building Effective Agents の Anthropic ブログで記述されています :
プロンプト連鎖はタスクを一連のステップに分解します、そこでは各 LLM 呼び出しは前の呼び出しの出力を処理します。プログラミングによるチェック (programmatic checks) (下図の “gate” 参照) を追加してプロセスが依然として順調であることを確認できます。
このワークフローを使用する場合: このワークフローはタスクが固定されたサブタスクに容易にかつ明確に分解できる状況に理想的です。メインゴールは、各 LLM 呼び出しを簡単なタスクにすることで、レイテンシーをトレードオフに精度を向上させることです。
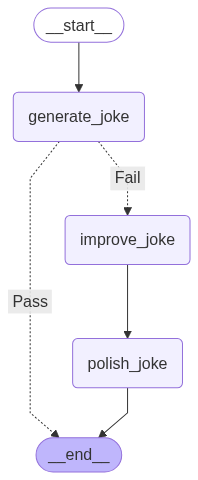
Graph API
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
# Graph state
class State(TypedDict):
topic: str
joke: str
improved_joke: str
final_joke: str
# Nodes
def generate_joke(state: State):
"""First LLM call to generate initial joke"""
msg = llm.invoke(f"Write a short joke about {state['topic']}")
return {"joke": msg.content}
def check_punchline(state: State):
"""Gate function to check if the joke has a punchline"""
# Simple check - does the joke contain "?" or "!"
if "?" in state["joke"] or "!" in state["joke"]:
return "Pass"
return "Fail"
def improve_joke(state: State):
"""Second LLM call to improve the joke"""
msg = llm.invoke(f"Make this joke funnier by adding wordplay: {state['joke']}")
return {"improved_joke": msg.content}
def polish_joke(state: State):
"""Third LLM call for final polish"""
msg = llm.invoke(f"Add a surprising twist to this joke: {state['improved_joke']}")
return {"final_joke": msg.content}
# Build workflow
workflow = StateGraph(State)
# Add nodes
workflow.add_node("generate_joke", generate_joke)
workflow.add_node("improve_joke", improve_joke)
workflow.add_node("polish_joke", polish_joke)
# Add edges to connect nodes
workflow.add_edge(START, "generate_joke")
workflow.add_conditional_edges(
"generate_joke", check_punchline, {"Fail": "improve_joke", "Pass": END}
)
workflow.add_edge("improve_joke", "polish_joke")
workflow.add_edge("polish_joke", END)
# Compile
chain = workflow.compile()
# Show workflow
display(Image(chain.get_graph().draw_mermaid_png()))
# Invoke
state = chain.invoke({"topic": "cats"})
print("Initial joke:")
print(state["joke"])
print("\n--- --- ---\n")
if "improved_joke" in state:
print("Improved joke:")
print(state["improved_joke"])
print("\n--- --- ---\n")
print("Final joke:")
print(state["final_joke"])
else:
print("Joke failed quality gate - no punchline detected!")
Initial joke: Why don't cats play poker in the jungle? Too many cheetahs! --- --- --- Joke failed quality gate - no punchline detected!
Functional API
from langgraph.func import entrypoint, task
# Tasks
@task
def generate_joke(topic: str):
"""First LLM call to generate initial joke"""
msg = llm.invoke(f"Write a short joke about {topic}")
return msg.content
def check_punchline(joke: str):
"""Gate function to check if the joke has a punchline"""
# Simple check - does the joke contain "?" or "!"
if "?" in joke or "!" in joke:
return "Fail"
return "Pass"
@task
def improve_joke(joke: str):
"""Second LLM call to improve the joke"""
msg = llm.invoke(f"Make this joke funnier by adding wordplay: {joke}")
return msg.content
@task
def polish_joke(joke: str):
"""Third LLM call for final polish"""
msg = llm.invoke(f"Add a surprising twist to this joke: {joke}")
return msg.content
@entrypoint()
def prompt_chaining_workflow(topic: str):
original_joke = generate_joke(topic).result()
if check_punchline(original_joke) == "Pass":
return original_joke
improved_joke = improve_joke(original_joke).result()
return polish_joke(improved_joke).result()
# Invoke
for step in prompt_chaining_workflow.stream("cats", stream_mode="updates"):
print(step)
print("\n")
{'generate_joke': "Why don't cats ever win races?\n\nBecause they always paws right before the finish line!"}
{'improve_joke': "Here are a few versions with enhanced wordplay:\n\n**Option 1:**\nWhy don't cats ever win races?\nBecause they always paws right before the finish line - it's their a-chilles heel!\n\n**Option 2:**\nWhy don't cats ever win races?\nBecause they always paws right before the finish line! They just can't help but paws for dramatic effect - it's truly cat-astrophic for their times!\n\n**Option 3:**\nWhy don't cats ever win races?\nBecause they always paws right before the finish line! They say it's paws-ible they could win, but they're just too purrfectionist to cross without looking good!\n\nThe second option probably works best as it layers multiple cat puns while keeping the rhythm of the original joke!"}
{'polish_joke': "Here's the joke with a surprising twist:\n\n**Why don't cats ever win races?**\nBecause they always paws right before the finish line! They just can't help but paws for dramatic effect - it's truly cat-astrophic for their times!\n\n**But here's the twist:** The cats have been *letting* the dogs win on purpose this whole time. Turns out they've been running an underground betting ring, making a fortune off everyone who bets against them. They're not just fast - they're *purr-fessional* con artists!\n\nThe real question isn't why cats don't win races... it's how long they've been playing the long game while we all thought they were just being dramatic! 🐱💰"}
{'prompt_chaining_workflow': "Here's the joke with a surprising twist:\n\n**Why don't cats ever win races?**\nBecause they always paws right before the finish line! They just can't help but paws for dramatic effect - it's truly cat-astrophic for their times!\n\n**But here's the twist:** The cats have been *letting* the dogs win on purpose this whole time. Turns out they've been running an underground betting ring, making a fortune off everyone who bets against them. They're not just fast - they're *purr-fessional* con artists!\n\nThe real question isn't why cats don't win races... it's how long they've been playing the long game while we all thought they were just being dramatic! 🐱💰"}
リソース:
- LangChain Academy – See our lesson on Prompt Chaining here.
並列化
並列化により、LLMs はタスクを同時に処理します :
LLMs はタスクを同時に処理し、それらの出力をプログラミング的に集約する場合があります。このワークフロー、並列化は 2 つの主要なバリエーションとして現れます – セクション化 (Sectioning): タスクを独立したサブタスクに分割して並列に実行します。投票 (Voting): 同じタスクを複数回実行して多様な出力を取得します。
このワークフローを使用する場合: 並列化は、分割されたサブタスクが速度のために並列化できる場合や、より信頼性の高い結果のために複数の視点や試行が必要な場合に効果的です。複数の考慮事項を含む複雑なタスクについては、LLMs は各考慮事項が個別の LLM 呼び出しにより処理され、特定の局面に注意を払うことが可能である場合、一般により良いパフォーマンスを示します。
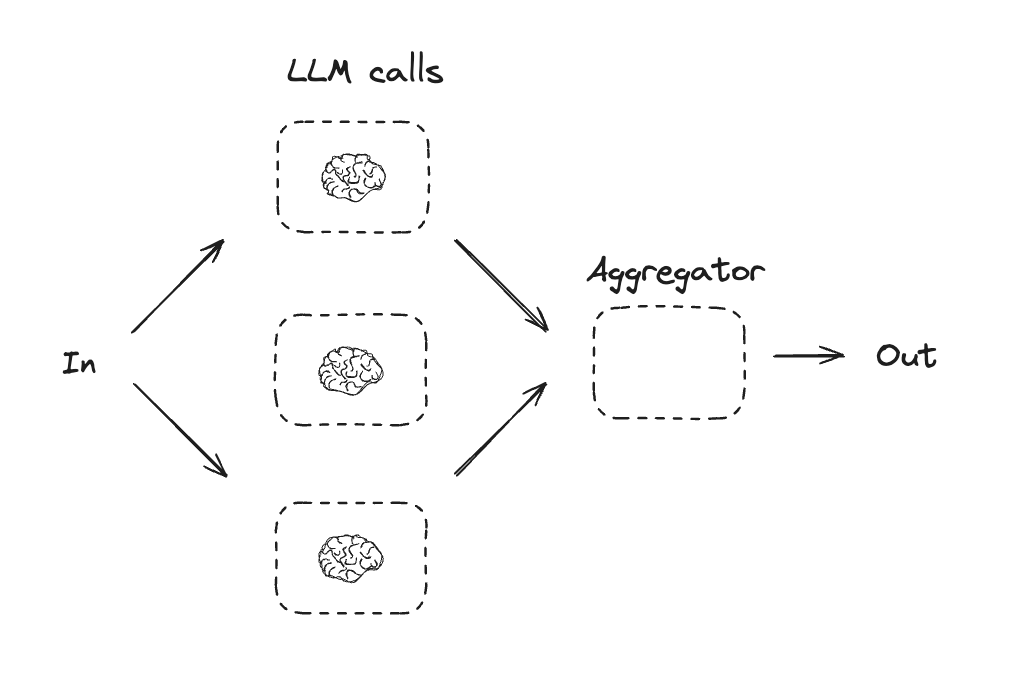
Graph API
# Graph state
class State(TypedDict):
topic: str
joke: str
story: str
poem: str
combined_output: str
# Nodes
def call_llm_1(state: State):
"""First LLM call to generate initial joke"""
msg = llm.invoke(f"Write a joke about {state['topic']}")
return {"joke": msg.content}
def call_llm_2(state: State):
"""Second LLM call to generate story"""
msg = llm.invoke(f"Write a story about {state['topic']}")
return {"story": msg.content}
def call_llm_3(state: State):
"""Third LLM call to generate poem"""
msg = llm.invoke(f"Write a poem about {state['topic']}")
return {"poem": msg.content}
def aggregator(state: State):
"""Combine the joke and story into a single output"""
combined = f"Here's a story, joke, and poem about {state['topic']}!\n\n"
combined += f"STORY:\n{state['story']}\n\n"
combined += f"JOKE:\n{state['joke']}\n\n"
combined += f"POEM:\n{state['poem']}"
return {"combined_output": combined}
# Build workflow
parallel_builder = StateGraph(State)
# Add nodes
parallel_builder.add_node("call_llm_1", call_llm_1)
parallel_builder.add_node("call_llm_2", call_llm_2)
parallel_builder.add_node("call_llm_3", call_llm_3)
parallel_builder.add_node("aggregator", aggregator)
# Add edges to connect nodes
parallel_builder.add_edge(START, "call_llm_1")
parallel_builder.add_edge(START, "call_llm_2")
parallel_builder.add_edge(START, "call_llm_3")
parallel_builder.add_edge("call_llm_1", "aggregator")
parallel_builder.add_edge("call_llm_2", "aggregator")
parallel_builder.add_edge("call_llm_3", "aggregator")
parallel_builder.add_edge("aggregator", END)
parallel_workflow = parallel_builder.compile()
# Show workflow
display(Image(parallel_workflow.get_graph().draw_mermaid_png()))
# Invoke
state = parallel_workflow.invoke({"topic": "cats"})
print(state["combined_output"])
Functional API
# Graph state
class State(TypedDict):
topic: str
joke: str
story: str
poem: str
combined_output: str
# Nodes
def call_llm_1(state: State):
"""First LLM call to generate initial joke"""
msg = llm.invoke(f"Write a joke about {state['topic']}")
return {"joke": msg.content}
def call_llm_2(state: State):
"""Second LLM call to generate story"""
msg = llm.invoke(f"Write a story about {state['topic']}")
return {"story": msg.content}
def call_llm_3(state: State):
"""Third LLM call to generate poem"""
msg = llm.invoke(f"Write a poem about {state['topic']}")
return {"poem": msg.content}
def aggregator(state: State):
"""Combine the joke and story into a single output"""
combined = f"Here's a story, joke, and poem about {state['topic']}!\n\n"
combined += f"STORY:\n{state['story']}\n\n"
combined += f"JOKE:\n{state['joke']}\n\n"
combined += f"POEM:\n{state['poem']}"
return {"combined_output": combined}
# Build workflow
parallel_builder = StateGraph(State)
# Add nodes
parallel_builder.add_node("call_llm_1", call_llm_1)
parallel_builder.add_node("call_llm_2", call_llm_2)
parallel_builder.add_node("call_llm_3", call_llm_3)
parallel_builder.add_node("aggregator", aggregator)
# Add edges to connect nodes
parallel_builder.add_edge(START, "call_llm_1")
parallel_builder.add_edge(START, "call_llm_2")
parallel_builder.add_edge(START, "call_llm_3")
parallel_builder.add_edge("call_llm_1", "aggregator")
parallel_builder.add_edge("call_llm_2", "aggregator")
parallel_builder.add_edge("call_llm_3", "aggregator")
parallel_builder.add_edge("aggregator", END)
parallel_workflow = parallel_builder.compile()
# Show workflow
display(Image(parallel_workflow.get_graph().draw_mermaid_png()))
# Invoke
state = parallel_workflow.invoke({"topic": "cats"})
print(state["combined_output"])
リソース:
- ドキュメント – See our documentation on parallelization here.
- LangChain Academy – See our lesson on parallelization here.
ルーティング
ルーティングは入力を分類してフォローアップタスクに向かわせます。”Building Effective Agents” Anthropic ブログでは以下のように記述されています :
ルーティングは入力を分類して特定のフォローアップタスクに向かわせます。このワークフローは関心の分離とより特化したプロンプトの構築を可能にします。このワークフローがないと、ある一つの種類の入力への最適化は他の入力でのパフォーマンスを劣化させる可能性があります。
このワークフローを使用する場合: ルーティングは、個別に処理するのが良い明確なカテゴリーがある複雑なタスクや、LLM や従来の分類モデル/アルゴリズムのいずれかで分類が正確に処理できるタスクに対して上手く動作します。
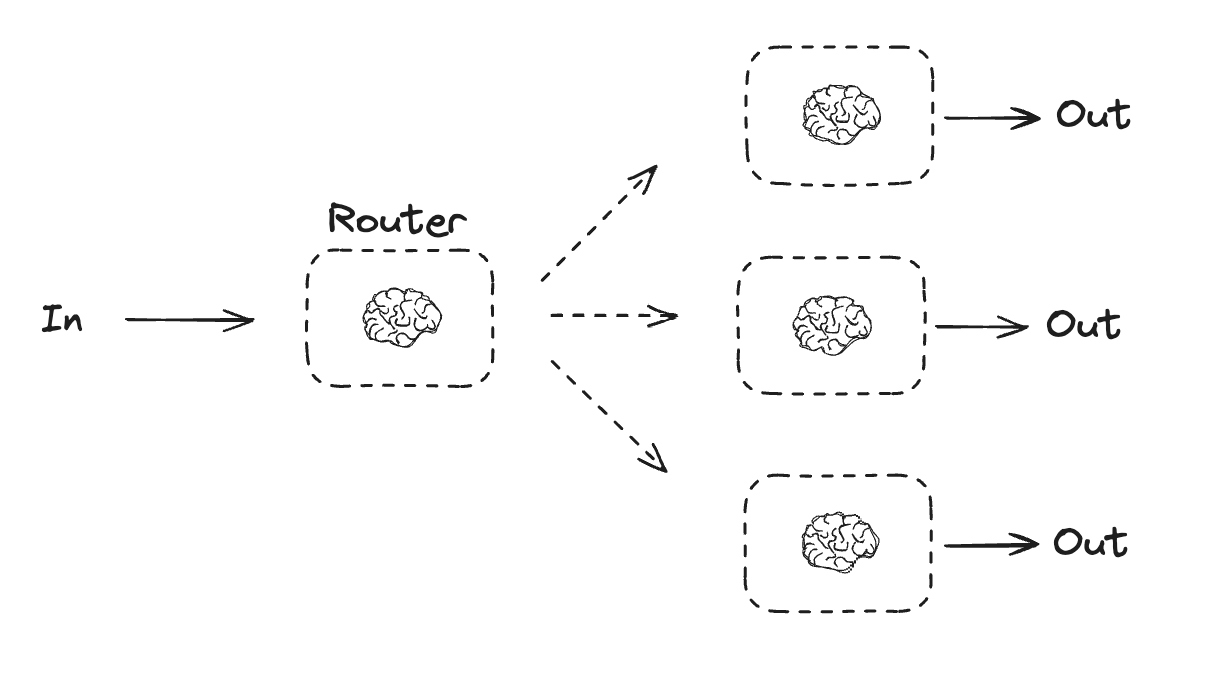
Graph API
from typing_extensions import Literal
from langchain_core.messages import HumanMessage, SystemMessage
# Schema for structured output to use as routing logic
class Route(BaseModel):
step: Literal["poem", "story", "joke"] = Field(
None, description="The next step in the routing process"
)
# Augment the LLM with schema for structured output
router = llm.with_structured_output(Route)
# State
class State(TypedDict):
input: str
decision: str
output: str
# Nodes
def llm_call_1(state: State):
"""Write a story"""
result = llm.invoke(state["input"])
return {"output": result.content}
def llm_call_2(state: State):
"""Write a joke"""
result = llm.invoke(state["input"])
return {"output": result.content}
def llm_call_3(state: State):
"""Write a poem"""
result = llm.invoke(state["input"])
return {"output": result.content}
def llm_call_router(state: State):
"""Route the input to the appropriate node"""
# Run the augmented LLM with structured output to serve as routing logic
decision = router.invoke(
[
SystemMessage(
content="Route the input to story, joke, or poem based on the user's request."
),
HumanMessage(content=state["input"]),
]
)
return {"decision": decision.step}
# Conditional edge function to route to the appropriate node
def route_decision(state: State):
# Return the node name you want to visit next
if state["decision"] == "story":
return "llm_call_1"
elif state["decision"] == "joke":
return "llm_call_2"
elif state["decision"] == "poem":
return "llm_call_3"
# Build workflow
router_builder = StateGraph(State)
# Add nodes
router_builder.add_node("llm_call_1", llm_call_1)
router_builder.add_node("llm_call_2", llm_call_2)
router_builder.add_node("llm_call_3", llm_call_3)
router_builder.add_node("llm_call_router", llm_call_router)
# Add edges to connect nodes
router_builder.add_edge(START, "llm_call_router")
router_builder.add_conditional_edges(
"llm_call_router",
route_decision,
{ # Name returned by route_decision : Name of next node to visit
"llm_call_1": "llm_call_1",
"llm_call_2": "llm_call_2",
"llm_call_3": "llm_call_3",
},
)
router_builder.add_edge("llm_call_1", END)
router_builder.add_edge("llm_call_2", END)
router_builder.add_edge("llm_call_3", END)
# Compile workflow
router_workflow = router_builder.compile()
# Show the workflow
display(Image(router_workflow.get_graph().draw_mermaid_png()))
# Invoke
state = router_workflow.invoke({"input": "Write me a joke about cats"})
print(state["output"])
Functional API
from typing_extensions import Literal
from pydantic import BaseModel
from langchain_core.messages import HumanMessage, SystemMessage
# Schema for structured output to use as routing logic
class Route(BaseModel):
step: Literal["poem", "story", "joke"] = Field(
None, description="The next step in the routing process"
)
# Augment the LLM with schema for structured output
router = llm.with_structured_output(Route)
@task
def llm_call_1(input_: str):
"""Write a story"""
result = llm.invoke(input_)
return result.content
@task
def llm_call_2(input_: str):
"""Write a joke"""
result = llm.invoke(input_)
return result.content
@task
def llm_call_3(input_: str):
"""Write a poem"""
result = llm.invoke(input_)
return result.content
def llm_call_router(input_: str):
"""Route the input to the appropriate node"""
# Run the augmented LLM with structured output to serve as routing logic
decision = router.invoke(
[
SystemMessage(
content="Route the input to story, joke, or poem based on the user's request."
),
HumanMessage(content=input_),
]
)
return decision.step
# Create workflow
@entrypoint()
def router_workflow(input_: str):
next_step = llm_call_router(input_)
if next_step == "story":
llm_call = llm_call_1
elif next_step == "joke":
llm_call = llm_call_2
elif next_step == "poem":
llm_call = llm_call_3
return llm_call(input_).result()
# Invoke
for step in router_workflow.stream("Write me a joke about cats", stream_mode="updates"):
print(step)
print("\n")
リソース:
- LangChain Academy – See our lesson on routing here.
- サンプル – Here is RAG workflow that routes questions. See our video here.
Orchestrator-ワーカー
orchestrator-ワーカーでは、orchestrator (指揮者) はタスクを分解し各サブタスクをワーカーに委任します。”Building Effective Agents” ブログ記事で記述されているように :
orchestrator-ワーカー・ワークフローでは、中心的な LLM がタスクを動的に分解し、それらをワーカー LLM に委任し、そしてその結果を統合します。
このワークフローを使用する場合: このワークフローは、必要なサブタスクを予測できない複雑なタスクに適しています (例えばコーディングでは、変更が必要なファイル数や各ファイルの変更の性質はタスクに依存しがちです)。トポロジー的には並列化に似ていますが、主な違いはその柔軟性です – サブタスクは事前定義されずに、特定の入力に基づいて orchestrator により決定されます。
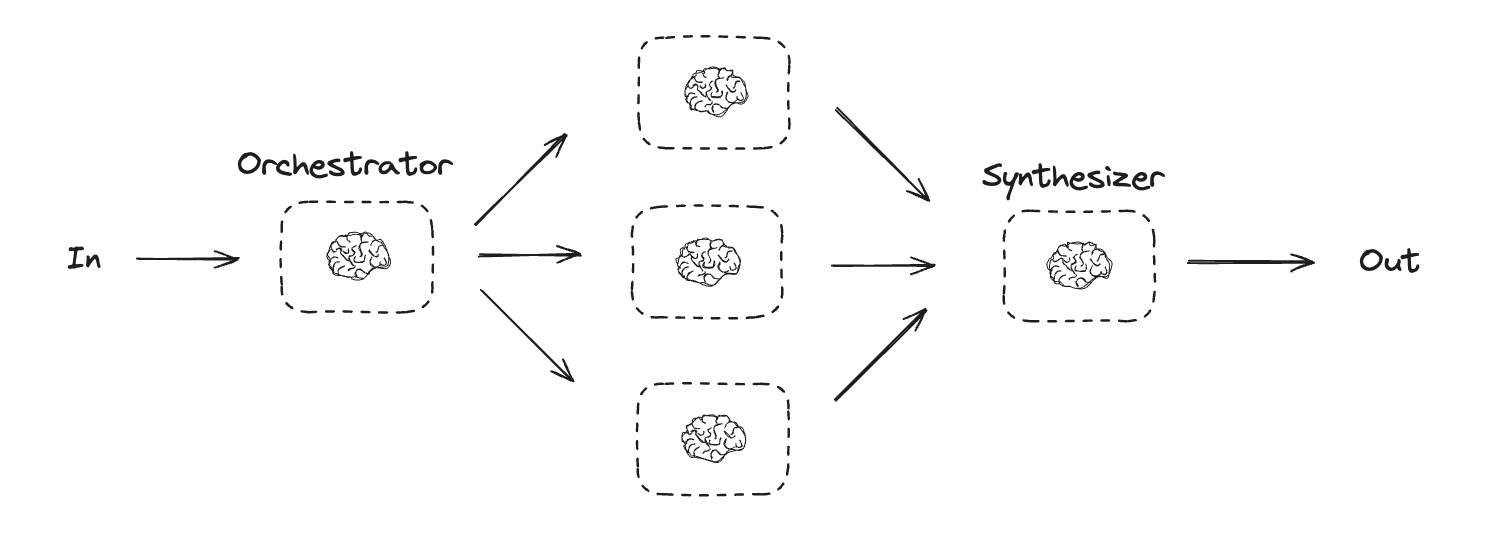
Graph API
from typing import Annotated, List
import operator
# Schema for structured output to use in planning
class Section(BaseModel):
name: str = Field(
description="Name for this section of the report.",
)
description: str = Field(
description="Brief overview of the main topics and concepts to be covered in this section.",
)
class Sections(BaseModel):
sections: List[Section] = Field(
description="Sections of the report.",
)
# Augment the LLM with schema for structured output
planner = llm.with_structured_output(Sections)
LangGraph におけるワーカーの作成
orchestrator-ワーカー・ワーカーフローは一般的ですので、LangGraph はこれを サポートする Send API を持っています。それはワーカーノードを動的に作成し、それぞれに特定の入力を送信することを可能にします。各ワーカーは独自の状態を持ち、すべてのワーカー出力は orchestrator グラフにアクセス可能な共有状態キーに書かれます。これは orchestrator にすべてのワーカー出力へのアクセスを与え、それらを最終的な出力に統合することを可能にします。以下で見れるように、セクションのリストに渡り反復し、それぞれをワーカーノードに “Send” (送信) します。See further documentation here and here.
from langgraph.types import Send
# Graph state
class State(TypedDict):
topic: str # Report topic
sections: list[Section] # List of report sections
completed_sections: Annotated[
list, operator.add
] # All workers write to this key in parallel
final_report: str # Final report
# Worker state
class WorkerState(TypedDict):
section: Section
completed_sections: Annotated[list, operator.add]
# Nodes
def orchestrator(state: State):
"""Orchestrator that generates a plan for the report"""
# Generate queries
report_sections = planner.invoke(
[
SystemMessage(content="Generate a plan for the report."),
HumanMessage(content=f"Here is the report topic: {state['topic']}"),
]
)
return {"sections": report_sections.sections}
def llm_call(state: WorkerState):
"""Worker writes a section of the report"""
# Generate section
section = llm.invoke(
[
SystemMessage(
content="Write a report section following the provided name and description. Include no preamble for each section. Use markdown formatting."
),
HumanMessage(
content=f"Here is the section name: {state['section'].name} and description: {state['section'].description}"
),
]
)
# Write the updated section to completed sections
return {"completed_sections": [section.content]}
def synthesizer(state: State):
"""Synthesize full report from sections"""
# List of completed sections
completed_sections = state["completed_sections"]
# Format completed section to str to use as context for final sections
completed_report_sections = "\n\n---\n\n".join(completed_sections)
return {"final_report": completed_report_sections}
# Conditional edge function to create llm_call workers that each write a section of the report
def assign_workers(state: State):
"""Assign a worker to each section in the plan"""
# Kick off section writing in parallel via Send() API
return [Send("llm_call", {"section": s}) for s in state["sections"]]
# Build workflow
orchestrator_worker_builder = StateGraph(State)
# Add the nodes
orchestrator_worker_builder.add_node("orchestrator", orchestrator)
orchestrator_worker_builder.add_node("llm_call", llm_call)
orchestrator_worker_builder.add_node("synthesizer", synthesizer)
# Add edges to connect nodes
orchestrator_worker_builder.add_edge(START, "orchestrator")
orchestrator_worker_builder.add_conditional_edges(
"orchestrator", assign_workers, ["llm_call"]
)
orchestrator_worker_builder.add_edge("llm_call", "synthesizer")
orchestrator_worker_builder.add_edge("synthesizer", END)
# Compile the workflow
orchestrator_worker = orchestrator_worker_builder.compile()
# Show the workflow
display(Image(orchestrator_worker.get_graph().draw_mermaid_png()))
# Invoke
state = orchestrator_worker.invoke({"topic": "Create a report on LLM scaling laws"})
from IPython.display import Markdown
Markdown(state["final_report"])
Functional API
from typing import List
# Schema for structured output to use in planning
class Section(BaseModel):
name: str = Field(
description="Name for this section of the report.",
)
description: str = Field(
description="Brief overview of the main topics and concepts to be covered in this section.",
)
class Sections(BaseModel):
sections: List[Section] = Field(
description="Sections of the report.",
)
# Augment the LLM with schema for structured output
planner = llm.with_structured_output(Sections)
@task
def orchestrator(topic: str):
"""Orchestrator that generates a plan for the report"""
# Generate queries
report_sections = planner.invoke(
[
SystemMessage(content="Generate a plan for the report."),
HumanMessage(content=f"Here is the report topic: {topic}"),
]
)
return report_sections.sections
@task
def llm_call(section: Section):
"""Worker writes a section of the report"""
# Generate section
result = llm.invoke(
[
SystemMessage(content="Write a report section."),
HumanMessage(
content=f"Here is the section name: {section.name} and description: {section.description}"
),
]
)
# Write the updated section to completed sections
return result.content
@task
def synthesizer(completed_sections: list[str]):
"""Synthesize full report from sections"""
final_report = "\n\n---\n\n".join(completed_sections)
return final_report
@entrypoint()
def orchestrator_worker(topic: str):
sections = orchestrator(topic).result()
section_futures = [llm_call(section) for section in sections]
final_report = synthesizer(
[section_fut.result() for section_fut in section_futures]
).result()
return final_report
# Invoke
report = orchestrator_worker.invoke("Create a report on LLM scaling laws")
from IPython.display import Markdown
Markdown(report)
リソース:
- LangChain Academy – See our lesson on orchestrator-worker here.
- サンプル – Here is a project that uses orchestrator-worker for report planning and writing. See our video here.
Evaluator-optimizer (評価器-optimizer)
evaluator-optimizer ワークフローでは、一つの LLM 呼び出しがレスポンスを生成する一方で、もう一つの LLM はループ内で評価とフィードバックを提供します :
evaluator-optimizer ワークフローでは、一つの LLM 呼び出しがレスポンスを生成する一方で、もう一つの LLM はループ内で評価とフィードバックを提供します。
このワークフローを使用する場合: このワークフローは、明確な評価基準があり、反復的な改良が測定可能な価値を提供する場合に特に効果的です。良い適合性の 2 つのサインは、1つ目は、人間がフィードバックを明確に表現する場合にその LLM 応答が明確に改善できることです ; そして 2 つ目は、LLM がそのようなフィードバックを提供できることです。これは、人間のライターが洗練されたドキュメントを作成する際に通過する可能性のある、反復的な執筆プロセスに類似しています。
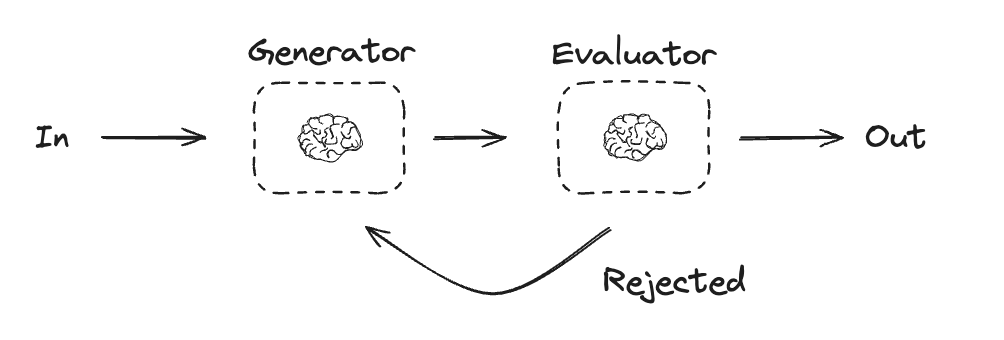
Graph API
# Graph state
class State(TypedDict):
joke: str
topic: str
feedback: str
funny_or_not: str
# Schema for structured output to use in evaluation
class Feedback(BaseModel):
grade: Literal["funny", "not funny"] = Field(
description="Decide if the joke is funny or not.",
)
feedback: str = Field(
description="If the joke is not funny, provide feedback on how to improve it.",
)
# Augment the LLM with schema for structured output
evaluator = llm.with_structured_output(Feedback)
# Nodes
def llm_call_generator(state: State):
"""LLM generates a joke"""
if state.get("feedback"):
msg = llm.invoke(
f"Write a joke about {state['topic']} but take into account the feedback: {state['feedback']}"
)
else:
msg = llm.invoke(f"Write a joke about {state['topic']}")
return {"joke": msg.content}
def llm_call_evaluator(state: State):
"""LLM evaluates the joke"""
grade = evaluator.invoke(f"Grade the joke {state['joke']}")
return {"funny_or_not": grade.grade, "feedback": grade.feedback}
# Conditional edge function to route back to joke generator or end based upon feedback from the evaluator
def route_joke(state: State):
"""Route back to joke generator or end based upon feedback from the evaluator"""
if state["funny_or_not"] == "funny":
return "Accepted"
elif state["funny_or_not"] == "not funny":
return "Rejected + Feedback"
# Build workflow
optimizer_builder = StateGraph(State)
# Add the nodes
optimizer_builder.add_node("llm_call_generator", llm_call_generator)
optimizer_builder.add_node("llm_call_evaluator", llm_call_evaluator)
# Add edges to connect nodes
optimizer_builder.add_edge(START, "llm_call_generator")
optimizer_builder.add_edge("llm_call_generator", "llm_call_evaluator")
optimizer_builder.add_conditional_edges(
"llm_call_evaluator",
route_joke,
{ # Name returned by route_joke : Name of next node to visit
"Accepted": END,
"Rejected + Feedback": "llm_call_generator",
},
)
# Compile the workflow
optimizer_workflow = optimizer_builder.compile()
# Show the workflow
display(Image(optimizer_workflow.get_graph().draw_mermaid_png()))
# Invoke
state = optimizer_workflow.invoke({"topic": "Cats"})
print(state["joke"])
Functional API
# Schema for structured output to use in evaluation
class Feedback(BaseModel):
grade: Literal["funny", "not funny"] = Field(
description="Decide if the joke is funny or not.",
)
feedback: str = Field(
description="If the joke is not funny, provide feedback on how to improve it.",
)
# Augment the LLM with schema for structured output
evaluator = llm.with_structured_output(Feedback)
# Nodes
@task
def llm_call_generator(topic: str, feedback: Feedback):
"""LLM generates a joke"""
if feedback:
msg = llm.invoke(
f"Write a joke about {topic} but take into account the feedback: {feedback}"
)
else:
msg = llm.invoke(f"Write a joke about {topic}")
return msg.content
@task
def llm_call_evaluator(joke: str):
"""LLM evaluates the joke"""
feedback = evaluator.invoke(f"Grade the joke {joke}")
return feedback
@entrypoint()
def optimizer_workflow(topic: str):
feedback = None
while True:
joke = llm_call_generator(topic, feedback).result()
feedback = llm_call_evaluator(joke).result()
if feedback.grade == "funny":
break
return joke
# Invoke
for step in optimizer_workflow.stream("Cats", stream_mode="updates"):
print(step)
print("\n")
リソース:
- サンプル – Here is an assistant that uses evaluator-optimizer to improve a report. See our video here.
- サンプル – Here is a RAG workflow that grades answers for hallucinations or errors. See our video here.
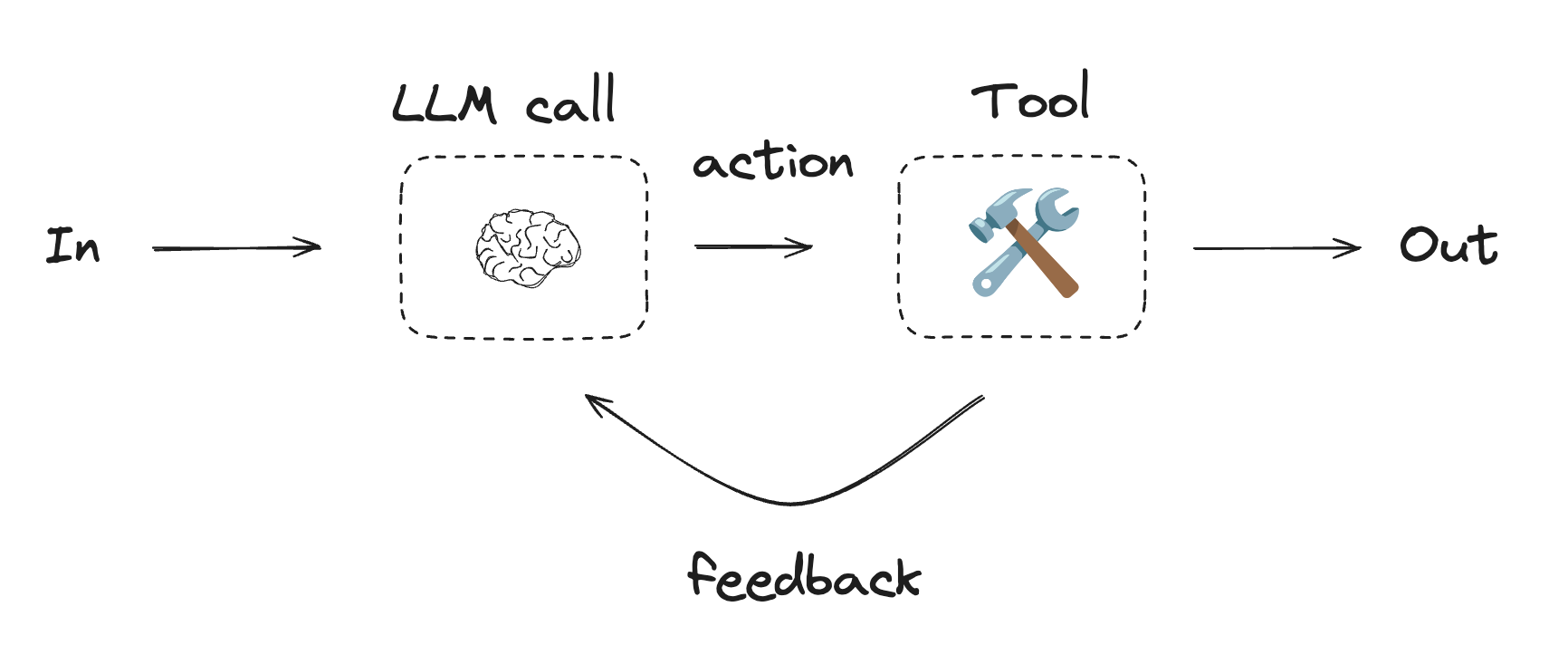
エージェント
エージェントは通常は、ループ内の環境からのフィードバックに基づいて (ツール呼び出し経由で) アクションを実行する LLM として実装されます。”Building Effective Agents” Anthropic ブログでは以下のように記述されています :
エージェントは洗練されたタスクを処理できますが、実装は単純な場合が多いです。それらは通常は、ループ内の環境からのフィードバックに基づいてツールを使用する LLM にすぎません。そのため、ツールセットとそれらのドキュメントを明確に思慮深く設計することは重要です。
エージェントを使用する場合: エージェントは、必要なステップ数を予測することが困難または不可能で、固定パスをハードコードできないオープンエンドな問題で使用できます。LLM は多くのターンの間動作する可能性があり、その意思決定にある程度の信頼をおく必要があります。エージェントの自律性は信頼できる環境でタスクをスケーリングするのに最適です。
from langchain_core.tools import tool
# Define tools
@tool
def multiply(a: int, b: int) -> int:
"""Multiply a and b.
Args:
a: first int
b: second int
"""
return a * b
@tool
def add(a: int, b: int) -> int:
"""Adds a and b.
Args:
a: first int
b: second int
"""
return a + b
@tool
def divide(a: int, b: int) -> float:
"""Divide a and b.
Args:
a: first int
b: second int
"""
return a / b
# Augment the LLM with tools
tools = [add, multiply, divide]
tools_by_name = {tool.name: tool for tool in tools}
llm_with_tools = llm.bind_tools(tools)
Graph API
from langgraph.graph import MessagesState
from langchain_core.messages import SystemMessage, HumanMessage, ToolMessage
# Nodes
def llm_call(state: MessagesState):
"""LLM decides whether to call a tool or not"""
return {
"messages": [
llm_with_tools.invoke(
[
SystemMessage(
content="You are a helpful assistant tasked with performing arithmetic on a set of inputs."
)
]
+ state["messages"]
)
]
}
def tool_node(state: dict):
"""Performs the tool call"""
result = []
for tool_call in state["messages"][-1].tool_calls:
tool = tools_by_name[tool_call["name"]]
observation = tool.invoke(tool_call["args"])
result.append(ToolMessage(content=observation, tool_call_id=tool_call["id"]))
return {"messages": result}
# Conditional edge function to route to the tool node or end based upon whether the LLM made a tool call
def should_continue(state: MessagesState) -> Literal["environment", END]:
"""Decide if we should continue the loop or stop based upon whether the LLM made a tool call"""
messages = state["messages"]
last_message = messages[-1]
# If the LLM makes a tool call, then perform an action
if last_message.tool_calls:
return "Action"
# Otherwise, we stop (reply to the user)
return END
# Build workflow
agent_builder = StateGraph(MessagesState)
# Add nodes
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("environment", tool_node)
# Add edges to connect nodes
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
{
# Name returned by should_continue : Name of next node to visit
"Action": "environment",
END: END,
},
)
agent_builder.add_edge("environment", "llm_call")
# Compile the agent
agent = agent_builder.compile()
# Show the agent
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))
# Invoke
messages = [HumanMessage(content="Add 3 and 4.")]
messages = agent.invoke({"messages": messages})
for m in messages["messages"]:
m.pretty_print()
Functional API
from langgraph.graph import add_messages
from langchain_core.messages import (
SystemMessage,
HumanMessage,
BaseMessage,
ToolCall,
)
@task
def call_llm(messages: list[BaseMessage]):
"""LLM decides whether to call a tool or not"""
return llm_with_tools.invoke(
[
SystemMessage(
content="You are a helpful assistant tasked with performing arithmetic on a set of inputs."
)
]
+ messages
)
@task
def call_tool(tool_call: ToolCall):
"""Performs the tool call"""
tool = tools_by_name[tool_call["name"]]
return tool.invoke(tool_call)
@entrypoint()
def agent(messages: list[BaseMessage]):
llm_response = call_llm(messages).result()
while True:
if not llm_response.tool_calls:
break
# Execute tools
tool_result_futures = [
call_tool(tool_call) for tool_call in llm_response.tool_calls
]
tool_results = [fut.result() for fut in tool_result_futures]
messages = add_messages(messages, [llm_response, *tool_results])
llm_response = call_llm(messages).result()
messages = add_messages(messages, llm_response)
return messages
# Invoke
messages = [HumanMessage(content="Add 3 and 4.")]
for chunk in agent.stream(messages, stream_mode="updates"):
print(chunk)
print("\n")
リソース:
- LangChain Academy – See our lesson on agents here.
- サンプル – Here is a project that uses a tool calling agent to create / store long-term memories.
Pre-built
LangGraph はまた、(create_react_agent 関数を使用して) 上記で定義されたエージェントを作成するための事前構築済みメソッドを提供しています :
from langgraph.prebuilt import create_react_agent
# Pass in:
# (1) the augmented LLM with tools
# (2) the tools list (which is used to create the tool node)
pre_built_agent = create_react_agent(llm, tools=tools)
# Show the agent
display(Image(pre_built_agent.get_graph().draw_mermaid_png()))
# Invoke
messages = [HumanMessage(content="Add 3 and 4.")]
messages = pre_built_agent.invoke({"messages": messages})
for m in messages["messages"]:
m.pretty_print()
以上