メモリは、エージェントが関連する情報を思い出す能力を与えます。メモリはエージェントのコンテキストの一部で、最適な、最もパーソナライズされた応答を提供するのに役立ちます。
Agno : ユーザガイド : コンセプト : エージェント – メモリ
作成 : クラスキャット・セールスインフォメーション
作成日時 : 07/19/2025
バージョン : Agno 1.7.4
* 本記事は docs.agno.com の以下のページを独自に翻訳した上で、補足説明を加えてまとめ直しています :
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

◆ お問合せ : 下記までお願いします。
- クラスキャット セールス・インフォメーション
- sales-info@classcat.com
- ClassCatJP
Agno ユーザガイド : コンセプト : エージェント – メモリ
メモリは、エージェントが関連する情報を思い出す能力を与えます。メモリはエージェントのコンテキストの一部で、最適な、最もパーソナライズされた応答を提供するのに役立ちます。
Note : ユーザがエージェントにスキーが好きであると伝えた場合、将来の応答はこの情報を参照してよりパーソナライズされたエクスペリエンスを提供することができます。
Agno では、メモリはチャット履歴、ユーザ (優先) 設定、そして当面のタスクに関する任意の補足情報をカバーします。Agno はすぐに利用できる 3 種類のメモリをサポートします :
- セッション・ストレージ (チャット履歴とセッション状態) : セッション・ストレージはエージェントのセッションをデータベースに保存し、エージェントが複数ターンの会話を行うことを可能にします。セッション・ストレージはまたセッション状態を保持します、これは実行にわたり永続化されます、各実行後にデータベースに保存されるからです。セッションストレージは Agno では「ストレージ」と呼ばれる短期メモリの一つの形式です。
- ユーザメモリ (ユーザ設定) : エージェントは会話を通して学習したユーザに関する洞察やファクトを保存できます。これは、エージェントがやり取りしているユーザに応答をパーソナライズするのに役立ちます。これは「ChatGPT のようなメモリ」をエージェントに追加すると考えてください。これを Agno では「メモリ」と呼びます。
- セッション・サマリー (チャット・サマリー) : エージェントはセッションの凝縮された表現を保存できます、これはチャット履歴が長過ぎる場合に有用です。これは Agno では「サマリー」と呼びます。
Info : It is relatively easy to use your own memory implementation using Agent.context.
エージェント型メモリのエキスパートになるには、以下について学習する必要があります :
Show me the code: メモリ & ストレージの実践
エージェントでメモリとストレージを使用する簡単ですが完全な例が以下です :
memory_demo.py
from agno.agent import Agent
from agno.memory.v2.db.sqlite import SqliteMemoryDb
from agno.memory.v2.memory import Memory
from agno.models.openai import OpenAIChat
from agno.storage.sqlite import SqliteStorage
from rich.pretty import pprint
# メモリ用 UserId
user_id = "ava"
# メモリとストレージ用データベースファィル
db_file = "tmp/agent.db"
# memory.v2 の初期化
memory = Memory(
# Use any model for creating memories
model=OpenAIChat(id="gpt-4.1"),
db=SqliteMemoryDb(table_name="user_memories", db_file=db_file),
)
# ストレージの初期化
storage = SqliteStorage(table_name="agent_sessions", db_file=db_file)
# エージェントの初期化
memory_agent = Agent(
model=OpenAIChat(id="gpt-4.1"),
# メモリをデータベースに保存
memory=memory,
# エージェントにメモリを更新する機能を与える
enable_agentic_memory=True,
# OR - 各レスポンス後に MemoryManager を実行
enable_user_memories=True,
# チャット履歴をデータベースに保存
storage=storage,
# チャット履歴をメッセージに追加
add_history_to_messages=True,
# 履歴実行 (history runs) 回数
num_history_runs=3,
markdown=True,
)
memory.clear()
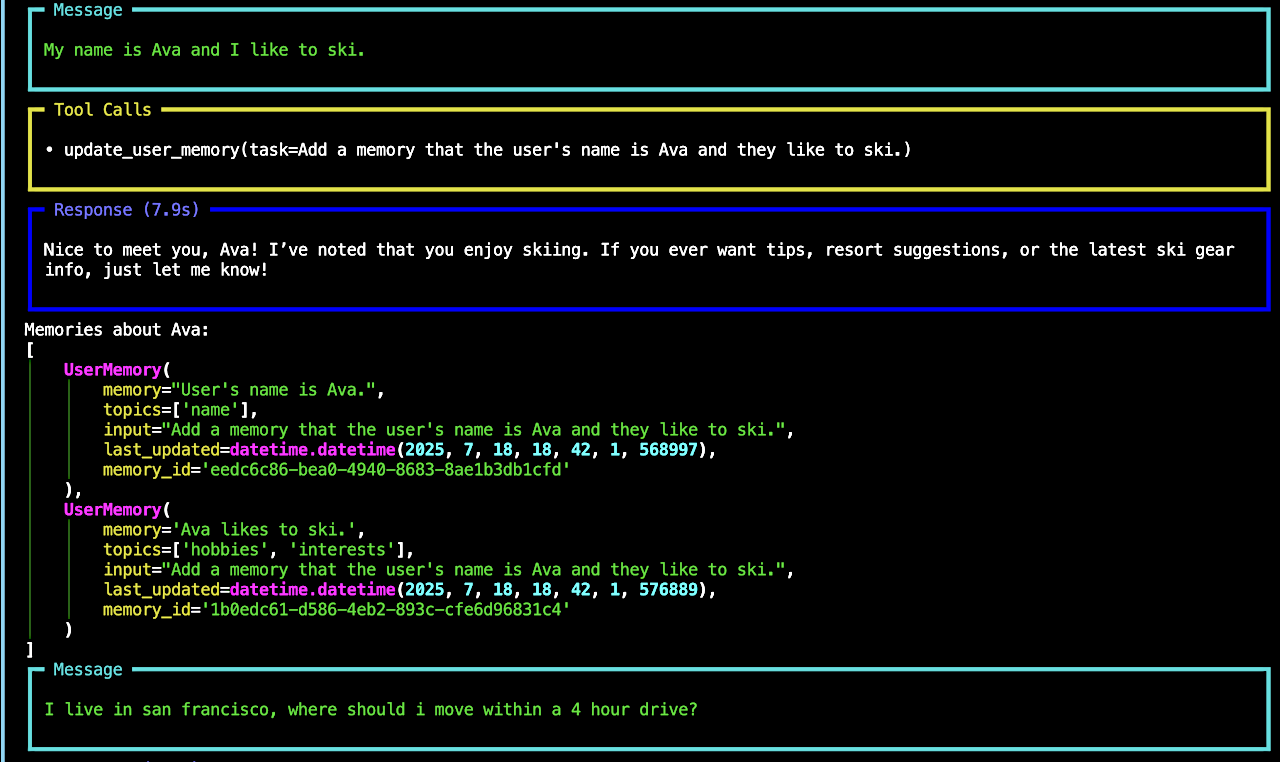
memory_agent.print_response(
"My name is Ava and I like to ski.",
user_id=user_id,
stream=True,
stream_intermediate_steps=True,
)
print("Memories about Ava:")
pprint(memory.get_user_memories(user_id=user_id))
memory_agent.print_response(
"I live in san francisco, where should i move within a 4 hour drive?",
user_id=user_id,
stream=True,
stream_intermediate_steps=True,
)
print("Memories about Ava:")
pprint(memory.get_user_memories(user_id=user_id))
Notes
- enable_agentic_memory=True は、ユーザのメモリを管理するツールをエージェントに与えます、このツールはタスクを MemoryManager クラスに渡します。enable_user_memories=True を設定することもできます、これは各ユーザメッセージ後に常に MemoryManager を実行します。
- add_history_to_messages=True はモデルに送信されたメッセージにチャット履歴を追加します、num_history_runs は追加する実行回数を決定します。
- read_chat_history=True はエージェントにチャット履歴を読み取ることを可能にするツールを追加します、num_history_runs に含まれる量よりも大きくなる可能性があります。
デフォルト・メモリ
すべてのエージェントは組み込みメモリを備えています、これはセッションのメッセージを追跡します (i.e. チャット履歴)。
agent.get_messages_for_session() を使用してこれらのメッセージにアクセスできます。
以下の方法でエージェントにチャット履歴へのアクセスを与えることができます :
- add_history_to_messages=True と num_history_runs=5 を設定して、エージェントに送信されたすべてのメッセージに直近 5 実行のメッセージを自動的に追加することができます。
- read_chat_history=True を設定して get_chat_history() ツールをエージェントに提供し、チャット履歴全体の任意のメッセージを読み取ることを可能にします。
- 最善のエクスペリエンスのためには add_history_to_messages=True, num_history_runs=3 そして read_chat_history=True の 3 つ全部を設定することを勧めます。
- また read_tool_call_history=True を設定してエージェントに get_tool_call_history() ツールを提供し、ツール呼び出しを時系列の逆順で読み取ることを可能することもできます。
Info : デフォルトメモリは実行サイクルに渡り永続化はされません。そのためスクリプトの実行が完了後、またはリクエストが終了すれば、組み込みのデフォルトメモリは失われます。
You can persist this memory in a database by adding a storage driver to the Agent.
- 組み込みメモリの例
agent_memory.py
from agno.agent import Agent from agno.models.google.gemini import Gemini from rich.pretty import pprint agent = Agent( model=Gemini(id="gemini-2.0-flash-exp"), # Set add_history_to_messages=true to add the previous chat history to the messages sent to the Model. add_history_to_messages=True, # Number of historical responses to add to the messages. num_history_responses=3, description="You are a helpful assistant that always responds in a polite, upbeat and positive manner.", ) # -*- Create a run agent.print_response("Share a 2 sentence horror story", stream=True) # -*- Print the messages in the memory pprint([m.model_dump(include={"role", "content"}) for m in agent.get_messages_for_session()]) # -*- Ask a follow up question that continues the conversation agent.print_response("What was my first message?", stream=True) # -*- Print the messages in the memory pprint([m.model_dump(include={"role", "content"}) for m in agent.get_messages_for_session()]) - 例の実行
ライブラリのインストール
pip install google-genai agnoキーのエクスポート
export GOOGLE_API_KEY=xxx例の実行
python agent_memory.py
セッション・ストレージ
組み込みメモリは現在の実行サイクルの間だけ利用可能です。スクリプトが終了するか、リクエストが終了すれば、組み込みメモリは失われます。
ストレージはエージェントのセッションと状態をデータベースかファイルに保存するのに役立ちます。
エージェントへのストレージを追加は単純でストレージドライバを提供するだけです、あとは Agno が処理します。Sqlite, Postgres, Mongo やその他、希望の任意のデータベースを使用できます。
実行サイクルに渡る永続性を実演する単純な例が以下です :
storage.py
from agno.agent import Agent
from agno.models.openai import OpenAIChat
from agno.storage.sqlite import SqliteStorage
from rich.pretty import pprint
agent = Agent(
model=OpenAIChat(id="gpt-4o-mini"),
# Fix the session id to continue the same session across execution cycles
session_id="fixed_id_for_demo",
storage=SqliteStorage(table_name="agent_sessions", db_file="tmp/data.db"),
add_history_to_messages=True,
num_history_runs=3,
)
agent.print_response("What was my last question?")
agent.print_response("What is the capital of France?")
agent.print_response("What was my last question?")
pprint(agent.get_messages_for_session())
最初にこれを実行すると、“What was my last question?” への回答は利用可能ではありません。しかし再度実行すると、エージェントは正しく回答できるようになります。セッション id を固定したので、スクリプトを実行するたびにエージェントは同じセッションから続行します。
Read more in the storage section.
ユーザメモリ
セッション履歴と状態を保存するだけでなく、エージェントは会話履歴に基づいてユーザメモリを作成することもできます。
ユーザメモリを有効にするには、エージェントに Memory オブジェクトを与えて enable_agentic_memory=True を設定します。
- ユーザメモリ例
user_memory.py
from agno.agent import Agent from agno.memory.v2.db.sqlite import SqliteMemoryDb from agno.memory.v2.memory import Memory from agno.models.google.gemini import Gemini memory_db = SqliteMemoryDb(table_name="memory", db_file="tmp/memory.db") memory = Memory(db=memory_db) john_doe_id = "john_doe@example.com" agent = Agent( model=Gemini(id="gemini-2.0-flash-exp"), memory=memory, enable_agentic_memory=True, ) # The agent can add new memories to the user's memory agent.print_response( "My name is John Doe and I like to hike in the mountains on weekends.", stream=True, user_id=john_doe_id, ) agent.print_response("What are my hobbies?", stream=True, user_id=john_doe_id) # The agent can also remove all memories from the user's memory agent.print_response( "Remove all existing memories of me. Completely clear the DB.", stream=True, user_id=john_doe_id, ) agent.print_response( "My name is John Doe and I like to paint.", stream=True, user_id=john_doe_id ) # The agent can remove specific memories from the user's memory agent.print_response("Remove any memory of my name.", stream=True, user_id=john_doe_id) - 例の実行
ライブラリのインストール
pip install google-genai agnoキーのエクスポート
export GOOGLE_API_KEY=xxx例の実行
python user_memory.py
ユーザメモリは Memory オブジェクトに保存され、複数のユーザと複数のセッションに渡り使用できるように SqliteMemoryDb に永続化されます。
セッション・サマリー
セッション・サマリーを有効にするには、エージェントで enable_session_summaries=True を設定します。
- セッション・サマリーの例
session_summary.py
from agno.agent import Agent from agno.memory.v2.db.sqlite import SqliteMemoryDb from agno.memory.v2.memory import Memory from agno.models.google.gemini import Gemini memory_db = SqliteMemoryDb(table_name="memory", db_file="tmp/memory.db") memory = Memory(db=memory_db) user_id = "jon_hamm@example.com" session_id = "1001" agent = Agent( model=Gemini(id="gemini-2.0-flash-exp"), memory=memory, enable_session_summaries=True, ) agent.print_response( "What can you tell me about quantum computing?", stream=True, user_id=user_id, session_id=session_id, ) agent.print_response( "I would also like to know about LLMs?", stream=True, user_id=user_id, session_id=session_id ) session_summary = memory.get_session_summary( user_id=user_id, session_id=session_id ) print(f"Session summary: {session_summary.summary}\n") - 例の実行
ライブラリのインストール
pip install google-genai agnoキーのエクスポート
export GOOGLE_API_KEY=xxx例の実行
python session_summary.py
以上