LangGraph も LangChain とともに 10 月のバージョン 1.0 リリースを目指しています。
Graph API と Functional API を使用したクイックスタートです。Colab 上で動作確認済みです。
LangGraph 1.0 alpha : Get started – クイックスタート on Colab
作成 : クラスキャット・セールスインフォメーション
作成日時 : 09/27/2025
バージョン : 1.0.0a3
* 本記事は docs.langchain.com の以下のページを独自に翻訳した上で、補足説明を加えてまとめ直しています。スニペットはできる限り日本語を使用しています :
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
クラスキャット 人工知能 研究開発支援サービス ⭐️ 創立30周年(30th Anniversary)🎉💐

◆ お問合せ : 下記までお願いします。
- クラスキャット セールス・インフォメーション
- sales-info@classcat.com
- ClassCatJP
![]()
LangGraph 1.0 alpha : Get started – クイックスタート on Colab
Graph API の使用
準備
%pip install -U -q langgraph "langchain[anthropic]"
ステップ 0 : ツールとモデルの定義
from langchain_core.tools import tool
from langchain.chat_models import init_chat_model
llm = init_chat_model(
"anthropic:claude-3-7-sonnet-latest",
temperature=0
)
# ツールの定義
@tool
def multiply(a: int, b: int) -> int:
"""Multiply a and b.
Args:
a: first int
b: second int
"""
return a * b
@tool
def add(a: int, b: int) -> int:
"""Adds a and b.
Args:
a: first int
b: second int
"""
return a + b
@tool
def divide(a: int, b: int) -> float:
"""Divide a and b.
Args:
a: first int
b: second int
"""
return a / b
# LLM をツールで強化します
tools = [add, multiply, divide]
tools_by_name = {tool.name: tool for tool in tools}
llm_with_tools = llm.bind_tools(tools)
ステップ 1 : 状態の定義
from langchain_core.messages import AnyMessage
from typing_extensions import TypedDict, Annotated
import operator
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], operator.add]
llm_calls: int
ステップ 2 : モデルノードの定義
from langchain_core.messages import SystemMessage
def llm_call(state: dict):
"""LLM はツールを呼び出すかどうか決定します。"""
return {
"messages": [
llm_with_tools.invoke(
[
SystemMessage(
content="あなたは、一連の入力に対して計算を実行する役割を担う、役に立つアシスタントです。"
)
]
+ state["messages"]
)
],
"llm_calls": state.get('llm_calls', 0) + 1
}
ステップ 3 : ツールノードの定義
from langchain_core.messages import ToolMessage
def tool_node(state: dict):
"""ツール呼び出しを実行します。"""
result = []
for tool_call in state["messages"][-1].tool_calls:
tool = tools_by_name[tool_call["name"]]
observation = tool.invoke(tool_call["args"])
result.append(ToolMessage(content=observation, tool_call_id=tool_call["id"]))
return {"messages": result}
ステップ 4 : 終了するかどうかを決定するロジックの定義
from typing import Literal
from langgraph.graph import StateGraph, START, END
# LLM がツール呼び出しを行ったかどうかに基づいて、ツールノードか END にルーティングする条件付きエッジ関数
def should_continue(state: MessagesState) -> Literal["tool_node", END]:
"""Decide if we should continue the loop or stop based upon whether the LLM made a tool call"""
messages = state["messages"]
last_message = messages[-1]
# If the LLM makes a tool call, then perform an action
if last_message.tool_calls:
return "tool_node"
# Otherwise, we stop (reply to the user)
return END
ステップ 5 : エージェントの構築
# Build workflow
agent_builder = StateGraph(MessagesState)
# ノードの追加
agent_builder.add_node("llm_call", llm_call)
agent_builder.add_node("tool_node", tool_node)
# ノードを接続するためにエッジの追加
agent_builder.add_edge(START, "llm_call")
agent_builder.add_conditional_edges(
"llm_call",
should_continue,
["tool_node", END]
)
agent_builder.add_edge("tool_node", "llm_call")
# エージェントのコンパイル
agent = agent_builder.compile()
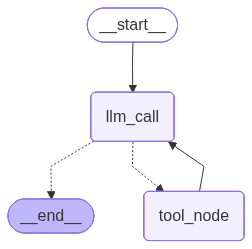
from IPython.display import Image, display
# エージェントの表示
display(Image(agent.get_graph(xray=True).draw_mermaid_png()))
# Invoke (呼び出し)
from langchain_core.messages import HumanMessage
messages = [HumanMessage(content="Add 3 and 4.")]
messages = agent.invoke({"messages": messages})
for m in messages["messages"]:
m.pretty_print()
出力例
================================ Human Message =================================
3 と 4 を足します。
================================== Ai Message ==================================
[{'text': '3と4を足す計算を実行します。', 'type': 'text'}, {'id': 'toolu_01UunbEbTQxPM7TtMrtJuNaL', 'input': {'a': 3, 'b': 4}, 'name': 'add', 'type': 'tool_use'}]
Tool Calls:
add (toolu_01UunbEbTQxPM7TtMrtJuNaL)
Call ID: toolu_01UunbEbTQxPM7TtMrtJuNaL
Args:
a: 3
b: 4
================================= Tool Message =================================
7
================================== Ai Message ==================================
3と4を足した結果は7です。
Functional API の使用
ステップ 0 : ツールとモデルの定義
from langchain_core.tools import tool
from langchain.chat_models import init_chat_model
llm = init_chat_model(
"anthropic:claude-3-7-sonnet-latest",
temperature=0
)
# Define tools
@tool
def multiply(a: int, b: int) -> int:
"""Multiply a and b.
Args:
a: first int
b: second int
"""
return a * b
@tool
def add(a: int, b: int) -> int:
"""Adds a and b.
Args:
a: first int
b: second int
"""
return a + b
@tool
def divide(a: int, b: int) -> float:
"""Divide a and b.
Args:
a: first int
b: second int
"""
return a / b
# Augment the LLM with tools
tools = [add, multiply, divide]
tools_by_name = {tool.name: tool for tool in tools}
llm_with_tools = llm.bind_tools(tools)
ステップ 1 : モデルノードの定義
from langgraph.graph import add_messages
from langchain_core.messages import (
SystemMessage,
HumanMessage,
BaseMessage,
ToolCall,
)
from langgraph.func import entrypoint, task
@task
def call_llm(messages: list[BaseMessage]):
"""LLM decides whether to call a tool or not"""
return llm_with_tools.invoke(
[
SystemMessage(
content="あなたは、一連の入力に対して計算を実行する役割を担う、役に立つアシスタントです。"
)
]
+ messages
)
ステップ 2 : ツールノードの定義
@task
def call_tool(tool_call: ToolCall):
"""ツール呼び出しの実行"""
tool = tools_by_name[tool_call["name"]]
return tool.invoke(tool_call)
ステップ 3 : エージェントの定義
@entrypoint()
def agent(messages: list[BaseMessage]):
llm_response = call_llm(messages).result()
while True:
if not llm_response.tool_calls:
break
# Execute tools
tool_result_futures = [
call_tool(tool_call) for tool_call in llm_response.tool_calls
]
tool_results = [fut.result() for fut in tool_result_futures]
messages = add_messages(messages, [llm_response, *tool_results])
llm_response = call_llm(messages).result()
messages = add_messages(messages, llm_response)
return messages
# Invoke
messages = [HumanMessage(content="Add 3 and 4.")]
for chunk in agent.stream(messages, stream_mode="updates"):
print(chunk)
print("\n")
出力例
{'call_llm': AIMessage(content=[{'text': '3と4を足す計算を実行します。', 'type': 'text'}, {'id': 'toolu_01XtHKoPmdCiJbLVBrf89S5Y', 'input': {'a': 3, 'b': 4}, 'name': 'add', 'type': 'tool_use'}], additional_kwargs={}, response_metadata={'id': 'msg_016FJwJ7d2nEPLDS7KxycjCn', 'model': 'claude-3-7-sonnet-20250219', 'stop_reason': 'tool_use', 'stop_sequence': None, 'usage': {'cache_creation': {'ephemeral_1h_input_tokens': 0, 'ephemeral_5m_input_tokens': 0}, 'cache_creation_input_tokens': 0, 'cache_read_input_tokens': 0, 'input_tokens': 620, 'output_tokens': 83, 'server_tool_use': None, 'service_tier': 'standard'}, 'model_name': 'claude-3-7-sonnet-20250219'}, id='run--924fbfa5-a36f-4af5-a713-aa7073b51e5b-0', tool_calls=[{'name': 'add', 'args': {'a': 3, 'b': 4}, 'id': 'toolu_01XtHKoPmdCiJbLVBrf89S5Y', 'type': 'tool_call'}], usage_metadata={'input_tokens': 620, 'output_tokens': 83, 'total_tokens': 703, 'input_token_details': {'cache_read': 0, 'cache_creation': 0, 'ephemeral_5m_input_tokens': 0, 'ephemeral_1h_input_tokens': 0}})}
{'call_tool': ToolMessage(content='7', name='add', tool_call_id='toolu_01XtHKoPmdCiJbLVBrf89S5Y')}
{'call_llm': AIMessage(content='3と4を足した結果は7です。', additional_kwargs={}, response_metadata={'id': 'msg_01RyQ5YbH5NRAxit6LcosNgw', 'model': 'claude-3-7-sonnet-20250219', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'cache_creation': {'ephemeral_1h_input_tokens': 0, 'ephemeral_5m_input_tokens': 0}, 'cache_creation_input_tokens': 0, 'cache_read_input_tokens': 0, 'input_tokens': 715, 'output_tokens': 16, 'server_tool_use': None, 'service_tier': 'standard'}, 'model_name': 'claude-3-7-sonnet-20250219'}, id='run--4f5ac643-a054-4d4a-af3d-352330aa224e-0', usage_metadata={'input_tokens': 715, 'output_tokens': 16, 'total_tokens': 731, 'input_token_details': {'cache_read': 0, 'cache_creation': 0, 'ephemeral_5m_input_tokens': 0, 'ephemeral_1h_input_tokens': 0}})}
{'agent': [
HumanMessage(content='3 と 4 を足します。', additional_kwargs={}, response_metadata={}, id='bb4e0361-7cee-4977-bc28-afd54623a8b0'),
AIMessage(content=[{'text': '3と4を足す計算を実行します。', 'type': 'text'}, {'id': 'toolu_01XtHKoPmdCiJbLVBrf89S5Y', 'input': {'a': 3, 'b': 4}, 'name': 'add', 'type': 'tool_use'}], additional_kwargs={}, response_metadata={'id': 'msg_016FJwJ7d2nEPLDS7KxycjCn', 'model': 'claude-3-7-sonnet-20250219', 'stop_reason': 'tool_use', 'stop_sequence': None, 'usage': {'cache_creation': {'ephemeral_1h_input_tokens': 0, 'ephemeral_5m_input_tokens': 0}, 'cache_creation_input_tokens': 0, 'cache_read_input_tokens': 0, 'input_tokens': 620, 'output_tokens': 83, 'server_tool_use': None, 'service_tier': 'standard'}, 'model_name': 'claude-3-7-sonnet-20250219'}, id='run--924fbfa5-a36f-4af5-a713-aa7073b51e5b-0', tool_calls=[{'name': 'add', 'args': {'a': 3, 'b': 4}, 'id': 'toolu_01XtHKoPmdCiJbLVBrf89S5Y', 'type': 'tool_call'}], usage_metadata={'input_tokens': 620, 'output_tokens': 83, 'total_tokens': 703, 'input_token_details': {'cache_read': 0, 'cache_creation': 0, 'ephemeral_5m_input_tokens': 0, 'ephemeral_1h_input_tokens': 0}}), ToolMessage(content='7', name='add', id='e5eb4247-d336-4a90-b065-9b7f0fbc48a0', tool_call_id='toolu_01XtHKoPmdCiJbLVBrf89S5Y'),
AIMessage(content='3と4を足した結果は7です。', additional_kwargs={}, response_metadata={'id': 'msg_01RyQ5YbH5NRAxit6LcosNgw', 'model': 'claude-3-7-sonnet-20250219', 'stop_reason': 'end_turn', 'stop_sequence': None, 'usage': {'cache_creation': {'ephemeral_1h_input_tokens': 0, 'ephemeral_5m_input_tokens': 0}, 'cache_creation_input_tokens': 0, 'cache_read_input_tokens': 0, 'input_tokens': 715, 'output_tokens': 16, 'server_tool_use': None, 'service_tier': 'standard'}, 'model_name': 'claude-3-7-sonnet-20250219'}, id='run--4f5ac643-a054-4d4a-af3d-352330aa224e-0', usage_metadata={'input_tokens': 715, 'output_tokens': 16, 'total_tokens': 731, 'input_token_details': {'cache_read': 0, 'cache_creation': 0, 'ephemeral_5m_input_tokens': 0, 'ephemeral_1h_input_tokens': 0}})
]}
以上