TensorFlow で CNN AutoEncoder – MNIST –
AutoEncoder はモデルの事前トレーニングをはじめとして様々な局面で必要になりますが、基本的には Encoder となる積層とそれを逆順に積み重ねた Decoder を用意するだけですので TensorFlow で簡単に実装できます。
今回は MNIST を題材として最初に MLP ベースの AutoEncoder を復習した後に、畳込み AutoEncoder (Convolutional AutoEncoder) を実装し、encode された特徴マップを視覚化し、decode された画像を元画像と比較してみます。
TensorFlow で MLP AutoEncoder
MLP ベースの AutoEncoder の実装は非常に簡単です。
完全結合層を並べて encoder とし、逆順の積層を decoder とするだけです。
以下の例では単純化のために encoder を1層のみとし、元画像と decode された画像を比較してみます :
【元サンプル画像】
サンプル画像は MNIST のテスト用画像を頭から 40 個集めたものです :

【1 epoch】
1 epoch 後の decode された画像。
一応それらしい画像は出力されていますが、薄ぼんやりしていて分かりにくいです :

【1 epoch(明るさ・輝度調整)】
明るさと輝度を調整してみました。元画像と比べると数字を構成する骨格自体が異なっているものも目立ちます :

【5 epochs(明るさ・輝度調整)】
やはり raw 出力では見て取れないので、明るさ・輝度を調整した後の画像を掲示しています :

【10 epochs(明るさ・輝度調整)】
だいぶ一致してきましたが細部が表現できていません :

TensorFlow で Convolutional Autoencoder
単層 MLP では十分な表現力が得られないので Convolutional Autoencoder にしてみます。
基本的な考え方は同じで、畳込み層を3層とする、ConvNet の基本モデルを使用しました。
但し、encode された画像を見やすくするために encoder 最終層の出力サイズは大きくなるように調整しています。
最初は MLP の場合と同様に decode した画像を元画像と比較してみます :
【元サンプル画像】
元サンプル画像は MLP と同じものを使います :

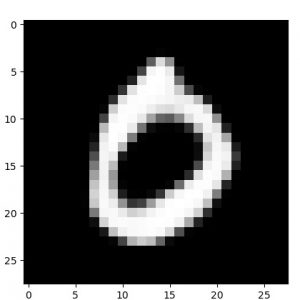
【1 epoch】
1 epoch で既に十分 decode できています。明るさ・輝度の調整も必要ありません :

【50 epochs】
50 epochs トレーニングした後の decode された画像では細部がよりクリアになっています :

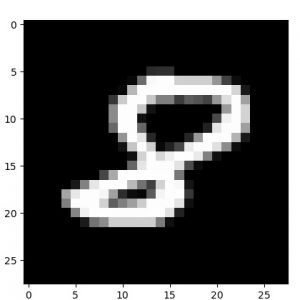
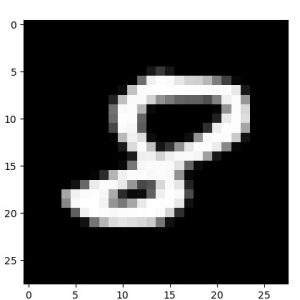
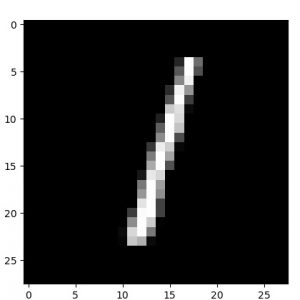
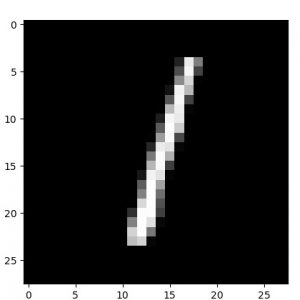
念のために単一のサンプル画像と decode された画像をトレーニング epochs で比較してみましたが、微細な違いはあるもののほぼ完璧に decode できています :
| 元サンプル画像 | 1 epoch |
|---|---|
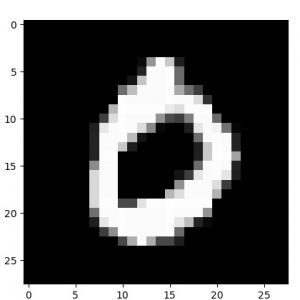
| 
|
| 10 epochs | 50 epochs |
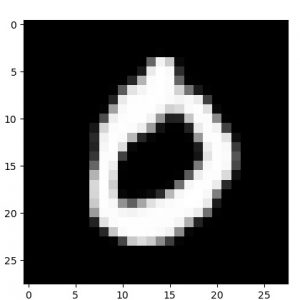
| 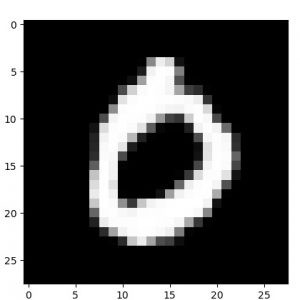 |
Convolutional Autoencoder で encode された画像
次に encode された画像をやはり epochs 数別に比較してみます。
以下は上の “0” の画像を encode した画像 (= encoder の特徴出力マップ) です。
トレーニングが進むにつれて特徴の掴みかたがより的確になっています :
【1 epoch】

【10 epochs】

【50 epochs】

他の数字でも確認しておきます。
元サンプル画像、50 epochs 後の decode された画像、そして 50 epochs 後の encode された画像群の順です :
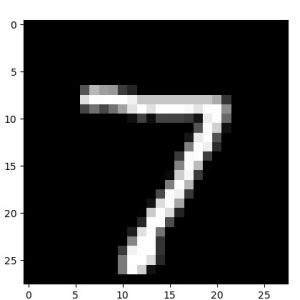
| 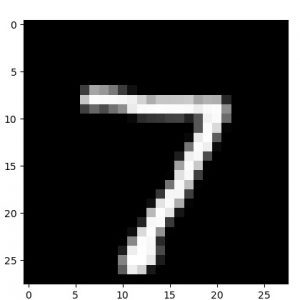 |

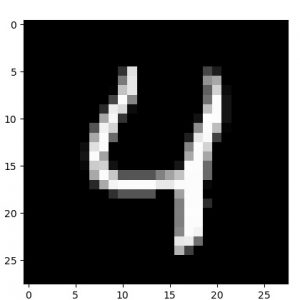
| 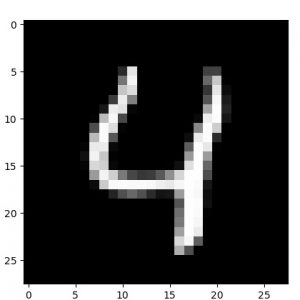 |

|  |

|  |

以上