TensorFlow VGG-16 の特徴マップの可視化
単純な ConvNet モデルで AlexNet モデルで MNIST / CIFAR-10 の特徴マップやフィルタを TensorFlow で実装して可視化した後、トレーニング済みの GoogLeNet Inception-v3 モデルを使用して特徴マップを可視化してみました。
今回は VGG-16 モデルを ImageNet 画像を使って自分でトレーニングした上で特徴マップを可視化してみました。VGG モデルは University of Oxford の VGG チームが提出した、層の深さを追求したモデルの通称ですが、VGG については TensorFlow で ConvNet VGG モデルを実装 を参照してください。
比較のために GoogLeNet Inception-v3 モデルの時と同じサンプルを使いました。
また、VGG-16 は積層がわかりやすいので、全部の層について特徴マップを示します。
特徴出力マップは適宜、明るさと輝度を調整してます。
VGG-16 TensorFlow 実装の特徴マップ
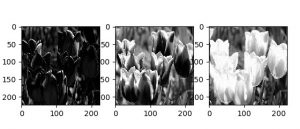
以下は、入力前のサンプル画像です。
左が元画像、右が正規化後の画像を 3 チャネルで分解してグレースケール表示したものです :

|  |
* この元画像は ImageNet からピックアップしています。版権は所有者に帰属します。
【Conv1_1】

【Conv1_2】

【MaxPool 1】112 x 112 サイズになります。

【Conv2_1】

【Conv2_2】

【MaxPool2】56 x 56 サイズになります。

【Conv3_1】

【Conv3_2】

【Conv3_3】

【MaxPool3】28 x 28 サイズになります。

【Conv4_1】

【Conv4_2】

【Conv4_3】

【MaxPool4】14 x 14 サイズになります。

【Conv5_1】

【Conv5_2】

【Conv5_3】

【MaxPool5】 7 x 7 サイズになります。

ページが長くなったので、別例は別ページ TensorFlow VGG-16 の特徴マップの可視化 (2) へ。
以上