TenosorFlow : 自動運転のための道路画像のセグメンテーション
作成 : (株)クラスキャット セールスインフォメーション
日時 : 06/24/2017
セグメンテーションは生物医学の画像処理や自動運転技術の基本の一つですが、医療画像については 2,3 の例を試してみましたので自動運転のリサーチ用の画像でセグメンテーションを試してみます。
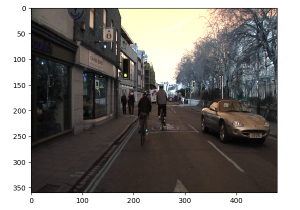
ここではシーン理解を主目的とするセマンティック・セグメンテーションのための SegNet モデルの Caffe 実装と共に提供されている CamVid データセットを題材にして TensorFlow 実装で実験してみます。CamVid データセットは道路シーンのサイズ 360 x 480 の 367 の訓練画像と 233 のテスト画像を含みます。ケンブリッジ界隈で撮られたもので昼と夕方のシーンを含みます。具体的には、下の左画像のような道路 (road) シーンが連続的に撮影されています。もちろん実際に自動車を走らせて撮影したのでしょう。
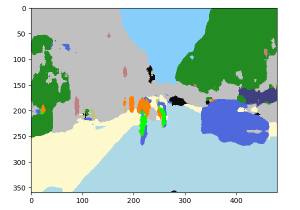
下の右画像は自前で訓練したモデルで予測したものです (● : 自動車, ● : 人間, ● : 自転車です) :

|  |
モデルと訓練
SegNet については (少し古いですが) 以下の記事がわかりやすいです :
SegNet を主題とするペーパーは幾つかありますが、以下が読みやすいです :
- SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
Vijay Badrinarayanan, Alex Kendall, Roberto Cipolla
(Submitted on 2 Nov 2015 (v1), last revised 10 Oct 2016 (this version, v3))
Abstract だけいつものように翻訳しておきます :
SegNet と呼ばれる pixel-wise なセマンティック・セグメンテーションのための新しい実用的な深層完全畳み込みニューラルネットワーク・アーキテクチャを提案します。この訓練可能なコア・セグメンテーション・エンジンは 、encoder ネットワーク、相当する decoder ネットワークそれに続く pixel-wise 分類層から成ります。encoder ネットワークのアーキテクチャは VGG 16 ネットワークの 13 畳み込み層と位相的に同一です。decoder ネットワークの役割は pixel-wise 分類のために低解像度 encoder 特徴マップを完全な入力解像度特徴マップにマップすることです。SegNet の新しさは decoder がそのより低解像度な入力特徴マップ(群)を upsample する方法にあります。特に、decoder は非線形 upsampling を実行するために、相当する encoder の max-pooling ステップで計算された pooling インデックスを使用します。これは upsample のための学習の必要性を取り除きます。upsample されたマップはスパースでそして密な特徴マップを生成するために訓練可能なフィルターで畳み込まれます。提案したアーキテクチャを広く採用されている FCN とそしてまた良く知られている DeepLab-LargeFOV, DeconvNet と比較します。この比較は良いセグメンテーション性能の獲得に関与するメモリ対精度のトレードオフを明らかにします。SegNet は主としてシーン理解アプリケーションにより動機付けられます。それ故に、推論の間にメモリと計算時間の両方の点から効率的であるようにデザインされています。また他の競合的なアーキテクチャよりも訓練可能なパラメータの数が本質的に小さいです。また道路 (road) シーンと SUN RGB-D 屋内 (indoor) シーン・セグメンテーションタスクの両者上で SegNet と他のアーキテクチャの制御されたベンチマークを実行しました。SegNet は他のアーキテクチャと比較して競合的な推論時間と memory-wise に より効率的な推論 で良い性能を提供することを示します。
実装は Caffe から TensorFlow に移しましたが、SegNet の位相そのままではなくやや簡略化したものを使用しました。
オリジナルモデルは encoder/decoder それぞれに VGG-16 を使用していますが、安直に試すには重過ぎますので。
訓練時の損失と検証精度の TensorBoard によるグラフは以下のようなものです。
100 epochs 回してみましたが、検証精度は 78 % くらいで頭打ちになりました (もちろんモデルを簡略化した影響もあるでしょう) :

結果
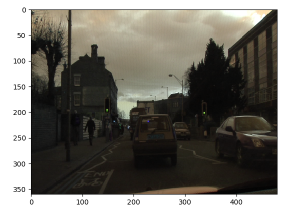
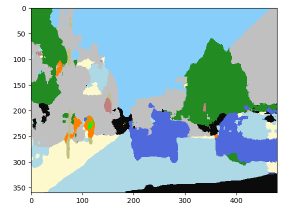
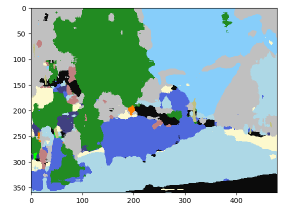
少なくとも提供されている検証データセット上で試した限りでは、結果は初期実験として見れば概ね良好です。人間の目では暗くて分かりにくい画像でも識別に問題ありません。ペーパーの abstract でも言及されていますが、モデルの完成度をあげた場合には精度とメモリや速度のトレードオフになるのでしょう。
[凡例]
● : 自動車 ; ● : 人間 ; ● : 自転車
● : 道路 ; ● : 空 ; ● 舗道 ; ● : 建物 ; ● : 木 ; ● : (未定義)
| 
|
| 
|
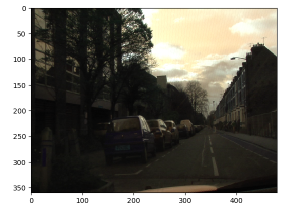
| 
|

| 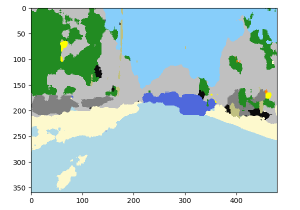 |
以下の画像は自動車について false positive です。これは訓練時に自動車の比重を大きくしているために自動車 (らしき物体) に対して過敏であるためでしょう。もっとも極端な話し、フェンスに自動車の絵が描かれている場合にはこのアプローチだけでは誤検知して当然にも思われます :

| 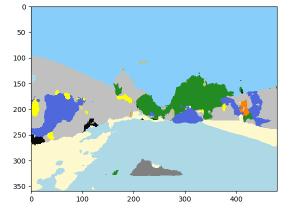 |
ImageNet
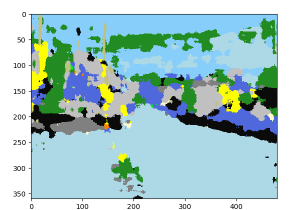
SegNet のセールスポイントは見たことのない画像に対しても効果的であることですが、提供されているデータセットだけで訓練したモデルを ImageNet 画像に適用するとさすがに結果はあまり芳しくありません。自動車の false positive もより顕著になります :

| 
|

| 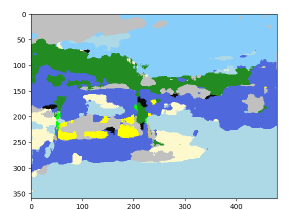 |
以上