TensorFlow : Deploy : TensorFlow Serving: アーキテクチャ概要 (翻訳)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 08/31/2017
* 本ページは、TensorFlow の本家サイトの Deploy : TensorFlow Serving – Architecture Overview を翻訳した上で
適宜、補足説明したものです:
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
TensorFlow Serving は機械学習モデルのための柔軟で、高パフォーマンスなサービング・システムで、本番環境 (= production environments) のためにデザインされています。TensorFlow Serving は同じサーバ・アーキテクチャと API を保持したまま、新しいアルゴリズムと実験を配備することを簡単にします。TensorFlow Serving は TensorFlow モデルとの独創的な統合を提供しますが、他のタイプのモデルをサーブするために簡単に拡張できます。
キー・コンセプト
TensorFlow Serving のアーキテクチャを理解するためには、以下ののキー・コンセプトを理解する必要があります :
Servable
Servable は TensorFlow Serving 内の中心的な抽象です。Servable はクライアントが計算 (例えば、検索や推論) を実行するために利用する、基礎となるオブジェクトです。
Servable のサイズや粒度 (= granularity) は柔軟です。単一の Servable は、単一のモデルへの検索テーブルの単一のシャードから推論モデルのタプルまで任意のものを含むかもしれません。
Servable は任意の型とインターフェイスから成ることができ、柔軟性と以下のような将来的な改良を可能にします :
- ストリーミングの結果
- 実験的な API
- 演算の非同期モデル
Servable はそれら自身のライフサイクルは管理しません。
典型的な servable は次を含みます :
- TensorFlow SavedModelBundle (tensorflow::Session)
- embedding や語彙検索のための検索テーブル
Servable Version
TensorFlow Serving は、単一のサーバ・インスタンスの生存時間 (= lifetime) に渡り一つまたはそれ以上の servable の version を扱うことができます。これは新たなアルゴリズムの configuration、重み、そして他のデータが時間をかけてロードされることを可能にします。version は servable の一つ以上のバージョンが同時にロードされることを可能にし、段階的な (= gradual) ロールアウトと実験をサポートします。serving 時には、クライアントは特定のモデルに対して、最新バージョンか特定のバージョン id をリクエストできます。
Servable Stream
servable stream は servable の version のシークエンスで、増加する version ナンバーによりソートされます。
Model
TensorFlow Serving は model を一つまたはそれ以上の servable として表します。機械学習されたモデルは一つまたはそれ以上の (学習された重みを含む) アルゴリズムと検索または embedding テーブルを含みます。
composite model (合成モデル) は次のどちらかとして表すことができます :
- 複数の独立した servable
- 単一の composite servable
servable はまたモデルの断片 (= fraction) にも相当するかもしれません。例えば、巨大な検索テーブルは多くの TensorFlow Serving インスタンスに渡りシャードされるでしょう。
Loader
Loader は servable のライフサイクルを管理します。Loader API は特定の学習アルゴリズム、データまたは付随する製品ユースケースからは独立な共通インフラを可能にします。特に、Loader は servable をロードとアンロードするための API を標準化します。
Source
Source は servable を開始するプラグイン・モジュールです; 各 Source はゼロまたはそれ以上の servable stream を開始します。各 stream に対して、Source はロードすることを望んだ各 version のために一つの Loader を供給します。(正確に言えば、Source は実際にはゼロまたはそれ以上の SourceAdapter と一緒に連鎖していて、鎖の最後のアイテムが Loader を発行します。)
Source のための TensorFlow Serving のインターフェイスは単純で限定的ですので、ロードするための servable を探索するためには任意のストレージ・システムを貴方に使用させます。Source は RPC のような他のメカニズムにアクセスするかもしれません。TensorFlow Serving は共通のリファレンス Source 実装を含みます。例えば、TensorFlow Serving はファイルシステムをポーリングできます。
差分更新 (= delta update) を効率的に受け取るモデルのような特別なケースのために、Source は複数の servable または version に渡り共有される状態を保持することができます。
Aspired Version
Aspired version はロードされて準備されるべき servable version のセットを表します。Source は、単一の servable stream のための servable version のこのセットと同時に通信します。Source が Manager に aspired version の新しいリストを与えたとき、それはその servable stream のための以前のリストに取って替わります。Manager はもはやリストに現れない以前にロードされた version をアンロードします。
version ローディングが実際にどのように動作するかを見るためには advanced tutorial を参照してください。
Manager
Manager は Servable の完全ライフサイクルを処理し、以下を含みます :
- Servable をロードする
- Servable をサーブする
- Servable をアンロードする
Manager は Source をリスンして全ての version を追跡します。Manager は Source のリクエストを実行しようとしますが、必要となるリソースが利用可能でない場合には aspired version のロードを拒否するかもしれません。Manager はまた “アンロード” を延期するかもしれません。例えば、少なくとも一つの version が常にロードされていることを保証するというポリシーをベースに、Manager は新しい vesion のロードが完了するまでアンロードを待つかもしれません。
TensorFlow Serving Manager は単純で、限定的なインターフェイス — GetServableHandle() — をロードされた servable インスタンスにアクセスするためにクライアントに提供します。
Core
TensorFlow Serving Core は (標準 TensorFlow Serving API を通して) servable の以下の局面を管理します :
- ライフサイクル
- メトリクス
TensorFlow Serving Core は servable と loader を opaque オブジェクトとして扱います。
Servable のライフ
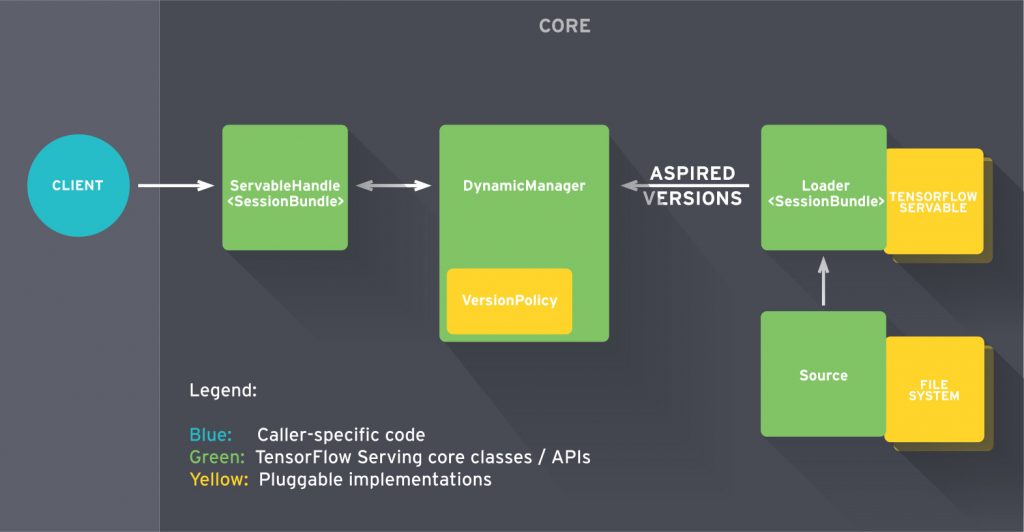
大雑把に言えば :
- Source が Servable Version のために Loader を作成する。
- Loader は Aspired Version として Manager に送られ、これはそれらをクライアント要求にロードしてサーブします。
より詳細には :
- Source プラグインが特定の version のための Loader を作成します。Loader は Servable をロードするために必要などのようなメタデータも含みます。
- Source は Manager に Aspired Version を通知するためにコールバックを使用します。
- Manager は取るべき次のアクションを決定するために設定された Version Policy を適用します、これは以前にロードされた version のアンロードあるいは新しい version のロードかもしれません。
- Manager が安全であると決定した場合、それは Loader に必要なリソースを与え、Loader に新しい version をロードするように伝えます。
- クライアントは Manager に Servable を要求します、version を明示的に指定するか最新 version を単に要求するかです。
例えば、Source が頻繁に更新されるモデル重みを持つ TensorFlow グラフを表すとします。重みはディスクのファイルにストアされます。
- Source はモデル重みの新しい version を検出します。それはディスクのモデル・データへのポインタを含む Loader を作成します。
- Source は Dynamic Manager に Aspired Version を通知します。
- Dynamic Manager は Version Policy を適用して新しい version を決定します。
- Dynamic Manager は Loader に十分なメモリがあることを伝えます。Loader は TensorFlow グラフを新しい重みでインスタンス化します。
- クライアントはモデルの最新 version へのハンドルを要求し、そして Dynamic Manager は Servable の新しい version へのハンドルを返します。
拡張性
TensorFlow Serving は幾つかの拡張ポイントを提供します、そこでは貴方は新しい機能を追加することができます。
Version Policy
Version Policy は、単一の servable stream 内の version ローディングとアンローディングのシークエンスを指定します。
TensorFlow Serving は最も良く知られたユースケースに適合する2つの policy を含みます。これらは Availability Preserving Policy (version が一つもロードされないことを回避するため; 典型的には古いものをアンロードする前に新しい version をロードします) 、そして Resource Preserving Policy (2つの version が同時にロードされ、2倍のリソースが必要となることを回避します; 新しいものをロードする前に古い vesion をアンロードします) です。model の serving 可用性が重要でリソースが低コストであるTensorFlow Serving の単純な使用のために、 Availability Preserving Policy は、古いものをアンロードする前に新しい version がロードされて準備できていることを保証します。TensorFlow Serving の洗練された使用のためには、例えば複数のサーバ・インスタンスに渡る version を管理する時、 Resource Preserving Policy は最小のリソースを要求します(新しい version をロードするための余分なバッファなし)。
Source
新しい Source は新しいファイルシステム、クラウド製品 (= offerings) そしてアルゴリズム・バックエンドをサポートできます。TensorFlow Serving は新しい source を簡単に速く作成するために幾つかの共通のビルディング・ブロックを提供します。例えば、TensorFlow Serving は単純な source まわりのポーリング挙動ををラップするユティリティを含みます。Source は特定のアルゴリズムとデータ・ホスティング servable のための Loader に密接に関係しています。
詳しくはカスタム Source をどのように作成するかについての Custom Source 文書を見てください。
Loaders
Loader はアルゴリズムとデータ・バックエンドのための拡張ポイントです。TensorFlow はそのようなアルゴリズム・バックエンドの一つです。例えば、貴方は新しいタイプの servable 機械学習モデルのインスタンスをロードし、それへのアクセスを提供し、そしてアンロードするための新しい Loader を実装するでしょう。私たちは検索テーブルと追加アルゴリズムのための Loader を作成することを予期します。
カスタム servable をどのように作成するかを学習するためには Custom Servable 文書を見てください。
Batcher
複数のリクエストの単一のリクエストへのバッチングは本質的に推論の実行のコストを減少させることができます、特に GPU のようなハードウェア・アクセラレータが存在する場合です。TensorFlow Serving はリクエスト・バッチング・ウイジェットを含み、これはクライアントに、リクエストに渡る type-specific 推論を (アルゴリズム・システムがより効率的に扱える)バッチ・リクエストに簡単にバッチ化させます。更なる情報のためには Batching Guide を見てください。
Next Steps
TensorFlow Serving を始めるには、Basic Tutorial にトライしてください。
以上