TensorFlow 機械学習ガイド : テキスト分類 (1) データの収集と調査 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 08/18/2018
* 本ページは、developers.google.com サイトの Machine Learning Guides : Text classification の以下のページを
翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。
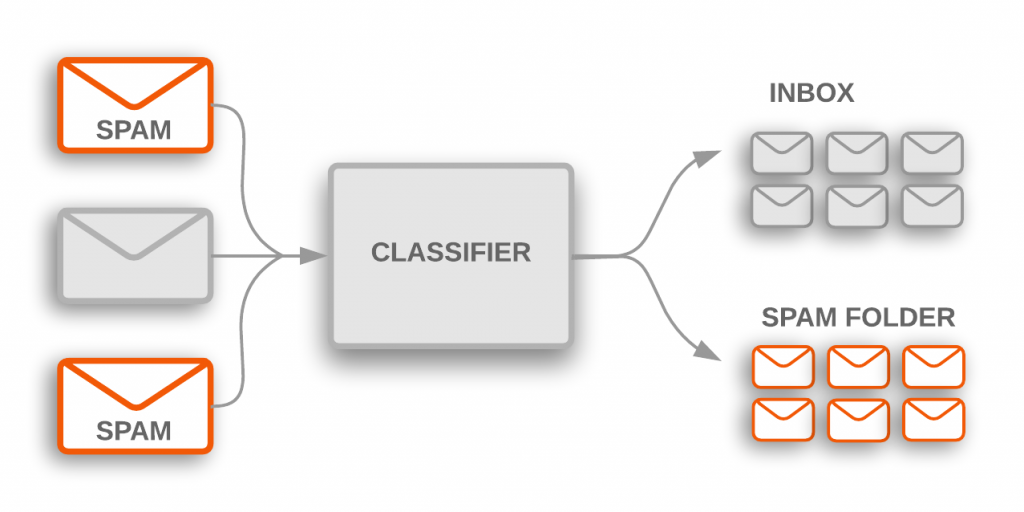
テキスト分類アルゴリズムは大規模なテキストデータを処理する様々なソフトウェア・システムの心臓部です。電子メール・ソフトウェアは incoming メールが inbox に送られるか spam フォルダにフィルタされるかを決定するためにテキスト分類を使用します。ディスカッション・フォーラムはコメントが不適切とフラグされるべきかを決定するためにテキスト分類を使用します。
これらはトピック分類の 2 つの例で、テキスト文書を事前定義されたトピックのセットの一つに分類します。多くのトピック分類問題では、このカテゴリ分けは主としてテキスト内のキーワードに基づきます。

Figure 1: トピック分類は incoming spam 電子メールに (spam フォルダにフィルタされる) フラグ付けするために使用されます。
テキスト分類の他の一般的なタイプはセンチメント解析で、その目的はテキスト内容の両極性 (= polarity) を識別します : それが表現する意見 (= opinion) のタイプです。これは二値の好き嫌い (= like/dislike) レイティングや 1 から 5 のスター・レイティングのような、より細かい意見のセットの形式を取ることができます。センチメント解析の例としては、人々がブラックパンサー映画を気に入ったか決定するための Twitter 投稿の解析や、またウォルマートのレビューから Nike シューズの新しいブランドの一般人の意見を推定することを含みます。
このガイドはテキスト分類問題を解くための幾つかの主要な機械学習ベストプラクティスを貴方に教えます。これらが学習するものです :
- 機械学習を使用してテキスト分類問題を解くための高位な、end-to-end ワークフロー
- テキスト分類問題のために正しいモデルをどのように選択するか
- 最適なモデルを TensorFlow を使用してどのように実装するか
テキスト分類ワークフロー
機械学習問題を解くために使用されるワークフローの高位な概要がここにあります :
- Step 1: データを収集する
- Step 2: データを調査する
- Step 2.5: モデルを選択する
- Step 3: データを準備する
- Step 4: モデルを構築、訓練、そして評価する
- Step 5: ハイパーパラメータを調整する
- Step 6: モデルを配備する

Figure 2: 機械学習問題を解くためのワークフロー
Step 1: データを収集する
どのような教師有り機械学習問題を解く場合でもデータの収集は最も重要なステップです。貴方のテキスト分類器は (それが構築された) データセットと同程度に良いだけです。
もし貴方が解くことを望む特定の問題を持たずに一般的なテキスト分類を調べることに興味があるだけならば、利用可能な多くのオープンソースのデータセットがあります。私達の GitHub repo でそれらの幾つかへのリンクを見つけることができます。その一方で、貴方が特定の問題に取り組んでいるのであれば、必要なデータを集める必要があるでしょう。多くの組織が彼らのデータにアクセスするため公開 API を提供しています — 例えば、Twitter API や NY Times API です。貴方が解こうとしている問題に対してこれらを活用できるかもしれません。
データを集めるときに覚えておきたい幾つかの重要なことがここにあります :
- 公開 API を使用しているならば、それらを使用する前に API の制限を理解しましょう。例えば、幾つかの API は問い合わせ可能なレートについて制限を設定しています。
- 貴方が持つ訓練例 (このガイドの残りではサンプルとして参照されます) が多ければ多いほど、より良いです。これは貴方のモデルをより良く一般化する助けとなるでしょう。
- 総てのクラスかトピックに対するサンプルの数は過度に不均衡でないことを確かなものとしてください。つまり、各クラスで同等な数のサンプルを持つべきです。
- サンプルが一般的なケースだけではなく、起こりうる入力空間を適切にカバーすることを確実にしてください。
このガイドを通して、ワークフローを示すために Internet Movie Database (IMDb) 映画レビュー・データセット を使用します。このデータセットは IMDb web サイト上の人々により投稿された映画レビューと、レビュアーが映画を好んだか否かを示す対応するラベル (ポシティブ or ネガティブ) を含みます。これはセンチメント解析問題の古典的な例です。
Step 2: データを調査する
モデルを構築して訓練することはワークフローの一部に過ぎません。貴方のデータの特性を前もって理解することはより良いモデルを構築することを可能にします。これは単純により高い精度を得ることを意味するでしょう。それはまた訓練のためにより少ないデータとより少ない計算リソースを必要とすることも意味します。
データセットをロードする
最初に、データセットを Python にロードしましょう。
def load_imdb_sentiment_analysis_dataset(data_path, seed=123):
"""Loads the IMDb movie reviews sentiment analysis dataset.
# Arguments
data_path: string, path to the data directory.
seed: int, seed for randomizer.
# Returns
A tuple of training and validation data.
Number of training samples: 25000
Number of test samples: 25000
Number of categories: 2 (0 - negative, 1 - positive)
# References
Mass et al., http://www.aclweb.org/anthology/P11-1015
Download and uncompress archive from:
http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz
"""
imdb_data_path = os.path.join(data_path, 'aclImdb')
# Load the training data
train_texts = []
train_labels = []
for category in ['pos', 'neg']:
train_path = os.path.join(imdb_data_path, 'train', category)
for fname in sorted(os.listdir(train_path)):
if fname.endswith('.txt'):
with open(os.path.join(train_path, fname)) as f:
train_texts.append(f.read())
train_labels.append(0 if category == 'neg' else 1)
# Load the validation data.
test_texts = []
test_labels = []
for category in ['pos', 'neg']:
test_path = os.path.join(imdb_data_path, 'test', category)
for fname in sorted(os.listdir(test_path)):
if fname.endswith('.txt'):
with open(os.path.join(test_path, fname)) as f:
test_texts.append(f.read())
test_labels.append(0 if category == 'neg' else 1)
# Shuffle the training data and labels.
random.seed(seed)
random.shuffle(train_texts)
random.seed(seed)
random.shuffle(train_labels)
return ((train_texts, np.array(train_labels)),
(test_texts, np.array(test_labels)))
データをチェックする
データをロードした後、その上で幾つかのチェックを実行することは良い実践です : 2, 3 のサンプルをピックアップしてそれらが貴方の想定と一致しているかどうかを手動で確認します。例えば、センチメント・ラベルがレビューのセンチメントに対応しているかを見るために 2, 3 のランダムなサンプルをプリントします。IMDb データセットからランダムに選んだレビューがここにあります : “Ten minutes worth of story stretched out into the better part of two hours. When nothing of any significance had happened at the halfway point I should have left.” 想定されるセンチメント (ネガティブ) はサンプルのラベルに適合します。
主要なメトリックを集める
ひとたびデータを検証したら、貴方のテキスト分類問題を特徴づける助けとなり得る次の重要なメトリックを集めます :
- Number of samples: 貴方がデータで持つサンプルの総数。
- Number of classes: データのトピックかカテゴリーの総数。
- Number of samples per class: クラス (トピック/カテゴリ) 毎のサンプル数。均衡の取れたデータセットでは、総てのクラスはサンプルの同様の数を持つでしょう ; 不均衡なデータセットでは、各クラスのサンプル数は大きく異なるでしょう。
- Number of words per sample: 一つのサンプルの単語の Median 数。
- Frequency distribution of words: データセットの各単語の頻度 (出現数) を示す分布。
- Distribution of sample length: データセットのサンプル毎の単語数を示す分布。
これらのメトリックについてどのような値が IMDb レビュー・データセットのためであるかを見てみましょう (単語頻度とサンプル長分布のプロットのための Figure 3 と 4 を見てください)。
| メトリック名 | メトリック値 |
| Number of samples | 25000 |
| Number of classes | 2 |
| Number of samples per class | 12500 |
| Number of words per sample | 174 |
Table 1: IMDb レビュー・データセット・メトリック
explore_data.py はこれらのメトリックを計算して解析する関数を含みます。2 つのサンプルがここにあります :
import numpy as np
import matplotlib.pyplot as plt
def get_num_words_per_sample(sample_texts):
"""Returns the median number of words per sample given corpus.
# Arguments
sample_texts: list, sample texts.
# Returns
int, median number of words per sample.
"""
num_words = [len(s.split()) for s in sample_texts]
return np.median(num_words)
def plot_sample_length_distribution(sample_texts):
"""Plots the sample length distribution.
# Arguments
samples_texts: list, sample texts.
"""
plt.hist([len(s) for s in sample_texts], 50)
plt.xlabel('Length of a sample')
plt.ylabel('Number of samples')
plt.title('Sample length distribution')
plt.show()

Figure 3: Frequency distribution of words for IMDb

Figure 4: Distribution of sample length for IMDb
以上