TensorFlow 2.4 : ガイド : Keras :- Functional API (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 01/10/2021
* 本ページは、TensorFlow org サイトの Guide – Keras の以下のページを翻訳した上で
適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
- Windows PC のブラウザからご参加が可能です。スマートデバイスもご利用可能です。
| 人工知能研究開発支援 | 人工知能研修サービス | テレワーク & オンライン授業を支援 |
| PoC(概念実証)を失敗させないための支援 (本支援はセミナーに参加しアンケートに回答した方を対象としています。 | ||
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
| 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション |
| E-Mail:sales-info@classcat.com ; WebSite: https://www.classcat.com/ |
| Facebook: https://www.facebook.com/ClassCatJP/ |

ガイド : Keras :- Functional API
セットアップ
import numpy as np import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers
イントロダクション
Keras Functional API は tf.keras.Sequential API よりもより柔軟なモデルを作成する方法です。functional API は非線形トポロジー、共有層、そしてマルチ入力と出力を持つモデルさえ扱うことができます。
主要なアイデアは深層学習モデルが通常は層の有向非巡回グラフ (DAG, directed acyclic graph) であるということです。そして Functional API は 層のグラフを構築する ための方法です。
次のモデルを考えましょう :
(input: 784-dimensional vectors)
↧
[Dense (64 units, relu activation)]
↧
[Dense (64 units, relu activation)]
↧
[Dense (10 units, softmax activation)]
↧
(output: logits of a probability distribution over 10 classes)
これは 3 層を持つ基本的なグラフです。このモデルを functional API を使用して構築するために、入力ノードを作成することから始めましょう :
inputs = keras.Input(shape=(784,))
データの shape は 784-次元ベクトルとして設定されます。バッチサイズは常に省略されます、何故ならば各サンプルの shape だけが指定されるからです。
例えば、(32, 32, 3) の shape を持つ画像を持つ場合、次を使用するでしょう :
# Just for demonstration purposes. img_inputs = keras.Input(shape=(32, 32, 3))
返される inputs は、貴方のモデルに供給する入力データの shape と dtype についての情報を含みます。ここに shape があります :
inputs.shape
TensorShape([None, 784])
ここに dtype があります :
inputs.dtype
tf.float32
この入力オブジェクト上で層を呼び出すことにより層のグラフで新しいノードを作成します :
dense = layers.Dense(64, activation="relu") x = dense(inputs)
「層呼び出し (= layer call)」アクションは “inputs” からこの作成した層への矢印を描くようなものです。入力を dense 層に「渡し」て、そして出力として x を得ます。
層のグラフに 2, 3 のより多くの層を追加しましょう :
x = layers.Dense(64, activation="relu")(x) outputs = layers.Dense(10)(x)
この時点で、層のグラフの入力と出力を指定することによりモデルを作成できます :
model = keras.Model(inputs=inputs, outputs=outputs, name="mnist_model")
モデル要約 (= summary) がどのようなものかを確認しましょう :
model.summary()
Model: "mnist_model" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) [(None, 784)] 0 _________________________________________________________________ dense (Dense) (None, 64) 50240 _________________________________________________________________ dense_1 (Dense) (None, 64) 4160 _________________________________________________________________ dense_2 (Dense) (None, 10) 650 ================================================================= Total params: 55,050 Trainable params: 55,050 Non-trainable params: 0 _________________________________________________________________
モデルをグラフとしてプロットすることもできます :
keras.utils.plot_model(model, "my_first_model.png")
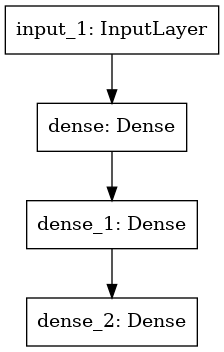
そしてオプションでプロットされたグラフで各層の入力と出力 shape を表示します :
keras.utils.plot_model(model, "my_first_model_with_shape_info.png", show_shapes=True)
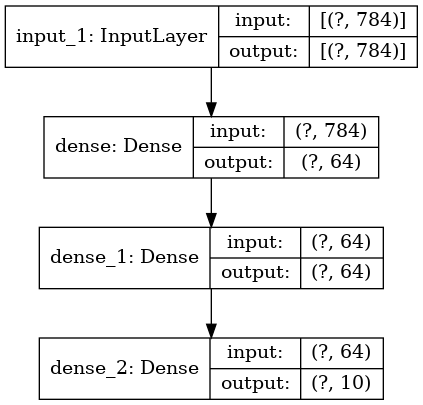
(訳注: 実際の出力)
この図とコードは殆ど同一です。コードバージョンでは、接続矢印は call 演算で置き換えられます。
「層のグラフ」は深層学習モデルのための非常に直感的なメンタルイメージで、そして functional API はこれをを密接に映すモデルを作成する方法です。
訓練、評価そして推論
訓練、評価と推論は functional API を使用して構築されたモデルのために Sequential モデルのためのものと正確に同じ方法で動作します。
ここでは、MNIST 画像データをロードし、それをベクトルに reshape し、(検証分割上でパフォーマンスを監視しながら) データ上でモデルを fit させ、それからテストデータ上でモデルを評価します :
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.reshape(60000, 784).astype("float32") / 255
x_test = x_test.reshape(10000, 784).astype("float32") / 255
model.compile(
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer=keras.optimizers.RMSprop(),
metrics=["accuracy"],
)
history = model.fit(x_train, y_train, batch_size=64, epochs=2, validation_split=0.2)
test_scores = model.evaluate(x_test, y_test, verbose=2)
print("Test loss:", test_scores[0])
print("Test accuracy:", test_scores[1])
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step Epoch 1/2 750/750 [==============================] - 3s 3ms/step - loss: 0.5905 - accuracy: 0.8360 - val_loss: 0.1903 - val_accuracy: 0.9464 Epoch 2/2 750/750 [==============================] - 2s 2ms/step - loss: 0.1721 - accuracy: 0.9501 - val_loss: 0.1507 - val_accuracy: 0.9557 313/313 - 0s - loss: 0.1509 - accuracy: 0.9550 Test loss: 0.1508905589580536 Test accuracy: 0.9549999833106995
更に読むために、訓練と評価へのガイド を見てください。
セービングとシリアライズ
モデルのセーブとシリアライゼーションは functional API を使用して構築されたモデルのために Sequential モデルのために行なうものと正確に同じ方法で動作します。functional モデルをセーブするための標準的な方法はモデル全体を単一ファイルにセーブするために model.save() を呼び出すことです。貴方は後でこのファイルから同じモデルを再作成できます、モデルを構築したコードがもはや利用可能でない場合でさえも。
このファイルは以下を含みます :
- モデルのアーキテクチャ
- モデルの重み値 (これは訓練の間に学習されました)
- もしあれば、(compile に渡された) モデルの訓練 config
- もしあれば、optimizer とその状態 (貴方がやめたところから訓練を再開するため)
model.save("path_to_my_model")
del model
# Recreate the exact same model purely from the file:
model = keras.models.load_model("path_to_my_model")
INFO:tensorflow:Assets written to: path_to_my_model/assets
詳細については、model serialization & saving ガイドを読んでください。
マルチモデルを定義するために層の同じグラフを使用する
functional API では、モデルは層のグラフ内のそれらの入力と出力を指定することにより作成されます。それは層の単一のグラフが複数のモデルを生成するために使用できることを意味しています。
下の例では、2 つのモデルをインスタンス化するために層の同じスタックを使用しています : 画像入力を 16-次元ベクトルに変えるエンコーダモデルと、訓練のための end-to-end オートエンコーダ・モデルです。
encoder_input = keras.Input(shape=(28, 28, 1), name="img") x = layers.Conv2D(16, 3, activation="relu")(encoder_input) x = layers.Conv2D(32, 3, activation="relu")(x) x = layers.MaxPooling2D(3)(x) x = layers.Conv2D(32, 3, activation="relu")(x) x = layers.Conv2D(16, 3, activation="relu")(x) encoder_output = layers.GlobalMaxPooling2D()(x) encoder = keras.Model(encoder_input, encoder_output, name="encoder") encoder.summary() x = layers.Reshape((4, 4, 1))(encoder_output) x = layers.Conv2DTranspose(16, 3, activation="relu")(x) x = layers.Conv2DTranspose(32, 3, activation="relu")(x) x = layers.UpSampling2D(3)(x) x = layers.Conv2DTranspose(16, 3, activation="relu")(x) decoder_output = layers.Conv2DTranspose(1, 3, activation="relu")(x) autoencoder = keras.Model(encoder_input, decoder_output, name="autoencoder") autoencoder.summary()
Model: "encoder" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= img (InputLayer) [(None, 28, 28, 1)] 0 _________________________________________________________________ conv2d (Conv2D) (None, 26, 26, 16) 160 _________________________________________________________________ conv2d_1 (Conv2D) (None, 24, 24, 32) 4640 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 8, 8, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 6, 6, 32) 9248 _________________________________________________________________ conv2d_3 (Conv2D) (None, 4, 4, 16) 4624 _________________________________________________________________ global_max_pooling2d (Global (None, 16) 0 ================================================================= Total params: 18,672 Trainable params: 18,672 Non-trainable params: 0 _________________________________________________________________ Model: "autoencoder" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= img (InputLayer) [(None, 28, 28, 1)] 0 _________________________________________________________________ conv2d (Conv2D) (None, 26, 26, 16) 160 _________________________________________________________________ conv2d_1 (Conv2D) (None, 24, 24, 32) 4640 _________________________________________________________________ max_pooling2d (MaxPooling2D) (None, 8, 8, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 6, 6, 32) 9248 _________________________________________________________________ conv2d_3 (Conv2D) (None, 4, 4, 16) 4624 _________________________________________________________________ global_max_pooling2d (Global (None, 16) 0 _________________________________________________________________ reshape (Reshape) (None, 4, 4, 1) 0 _________________________________________________________________ conv2d_transpose (Conv2DTran (None, 6, 6, 16) 160 _________________________________________________________________ conv2d_transpose_1 (Conv2DTr (None, 8, 8, 32) 4640 _________________________________________________________________ up_sampling2d (UpSampling2D) (None, 24, 24, 32) 0 _________________________________________________________________ conv2d_transpose_2 (Conv2DTr (None, 26, 26, 16) 4624 _________________________________________________________________ conv2d_transpose_3 (Conv2DTr (None, 28, 28, 1) 145 ================================================================= Total params: 28,241 Trainable params: 28,241 Non-trainable params: 0 _________________________________________________________________
ここでは、デコーディング・アーキテクチャをエンコーディング・アーキテクチャと厳密に対称的ですので、出力 shape は入力 shape (28, 28, 1) と同じです。
Conv2D 層の反対は Conv2DTranspose 層で、MaxPooling2D 層の反対は UpSampling2D 層です。
総てのモデルは、ちょうど層のように callable です
任意のモデルは、Input 上あるいはもう一つの他の層の出力上でそれを呼び出すことによって、それが層であるかのように扱うことができます。モデルを呼び出すことによりモデルのアーキテクチャを単に再利用しているのではなく、その重みを再利用していることに注意してください。
これを実際に見るため、ここにオートエンコーダ・サンプルの異なるテイクがあります、それはエンコーダ・モデル、デコーダ・モデルを作成し、オートエンコーダ・モデルを得るためにそれらを 2 つの呼び出し内に連鎖します :
encoder_input = keras.Input(shape=(28, 28, 1), name="original_img") x = layers.Conv2D(16, 3, activation="relu")(encoder_input) x = layers.Conv2D(32, 3, activation="relu")(x) x = layers.MaxPooling2D(3)(x) x = layers.Conv2D(32, 3, activation="relu")(x) x = layers.Conv2D(16, 3, activation="relu")(x) encoder_output = layers.GlobalMaxPooling2D()(x) encoder = keras.Model(encoder_input, encoder_output, name="encoder") encoder.summary() decoder_input = keras.Input(shape=(16,), name="encoded_img") x = layers.Reshape((4, 4, 1))(decoder_input) x = layers.Conv2DTranspose(16, 3, activation="relu")(x) x = layers.Conv2DTranspose(32, 3, activation="relu")(x) x = layers.UpSampling2D(3)(x) x = layers.Conv2DTranspose(16, 3, activation="relu")(x) decoder_output = layers.Conv2DTranspose(1, 3, activation="relu")(x) decoder = keras.Model(decoder_input, decoder_output, name="decoder") decoder.summary() autoencoder_input = keras.Input(shape=(28, 28, 1), name="img") encoded_img = encoder(autoencoder_input) decoded_img = decoder(encoded_img) autoencoder = keras.Model(autoencoder_input, decoded_img, name="autoencoder") autoencoder.summary()
Model: "encoder" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= original_img (InputLayer) [(None, 28, 28, 1)] 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 26, 26, 16) 160 _________________________________________________________________ conv2d_5 (Conv2D) (None, 24, 24, 32) 4640 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 8, 8, 32) 0 _________________________________________________________________ conv2d_6 (Conv2D) (None, 6, 6, 32) 9248 _________________________________________________________________ conv2d_7 (Conv2D) (None, 4, 4, 16) 4624 _________________________________________________________________ global_max_pooling2d_1 (Glob (None, 16) 0 ================================================================= Total params: 18,672 Trainable params: 18,672 Non-trainable params: 0 _________________________________________________________________ Model: "decoder" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= encoded_img (InputLayer) [(None, 16)] 0 _________________________________________________________________ reshape_1 (Reshape) (None, 4, 4, 1) 0 _________________________________________________________________ conv2d_transpose_4 (Conv2DTr (None, 6, 6, 16) 160 _________________________________________________________________ conv2d_transpose_5 (Conv2DTr (None, 8, 8, 32) 4640 _________________________________________________________________ up_sampling2d_1 (UpSampling2 (None, 24, 24, 32) 0 _________________________________________________________________ conv2d_transpose_6 (Conv2DTr (None, 26, 26, 16) 4624 _________________________________________________________________ conv2d_transpose_7 (Conv2DTr (None, 28, 28, 1) 145 ================================================================= Total params: 9,569 Trainable params: 9,569 Non-trainable params: 0 _________________________________________________________________ Model: "autoencoder" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= img (InputLayer) [(None, 28, 28, 1)] 0 _________________________________________________________________ encoder (Functional) (None, 16) 18672 _________________________________________________________________ decoder (Functional) (None, 28, 28, 1) 9569 ================================================================= Total params: 28,241 Trainable params: 28,241 Non-trainable params: 0 _________________________________________________________________
見れるように、モデルはネストできます : モデルはサブモデルを含むことができます (何故ならばモデルはちょうど層のようなものだからです)。モデル・ネスティングのための一般的なユースケースはアンサンブルです。例として、ここにモデルのセットを (それらの予測を平均する) 単一のモデルにどのようにアンサンブルするかがあります :
def get_model():
inputs = keras.Input(shape=(128,))
outputs = layers.Dense(1)(inputs)
return keras.Model(inputs, outputs)
model1 = get_model()
model2 = get_model()
model3 = get_model()
inputs = keras.Input(shape=(128,))
y1 = model1(inputs)
y2 = model2(inputs)
y3 = model3(inputs)
outputs = layers.average([y1, y2, y3])
ensemble_model = keras.Model(inputs=inputs, outputs=outputs)
複雑なグラフ・トポロジーを操作する
マルチ入力と出力を持つモデル
functional API はマルチ入力と出力を操作することを容易にします。これは Sequential API では処理できません。
たとえば、貴方はプライオリティによりカスタマー課題 (= issue) チケットをランク付けしてそれらを正しい部門に転送するためのシステムを構築している場合、モデルは 3 つの入力を持ちます :
- チケットのタイトル (テキスト入力)
- チケットのテキスト本体 (テキスト入力)、そして
- ユーザにより付加された任意のタグ (カテゴリカル入力)
モデルは 2 つの出力を持ちます :
- 0 と 1 の間のプライオリティ・スコア (スカラー sigmoid 出力)、そして
- チケットを処理すべき部門 (部門の集合に渡る softmax 出力)
このモデルを Functional API で数行で構築することができます :
num_tags = 12 # Number of unique issue tags
num_words = 10000 # Size of vocabulary obtained when preprocessing text data
num_departments = 4 # Number of departments for predictions
title_input = keras.Input(
shape=(None,), name="title"
) # Variable-length sequence of ints
body_input = keras.Input(shape=(None,), name="body") # Variable-length sequence of ints
tags_input = keras.Input(
shape=(num_tags,), name="tags"
) # Binary vectors of size `num_tags`
# Embed each word in the title into a 64-dimensional vector
title_features = layers.Embedding(num_words, 64)(title_input)
# Embed each word in the text into a 64-dimensional vector
body_features = layers.Embedding(num_words, 64)(body_input)
# Reduce sequence of embedded words in the title into a single 128-dimensional vector
title_features = layers.LSTM(128)(title_features)
# Reduce sequence of embedded words in the body into a single 32-dimensional vector
body_features = layers.LSTM(32)(body_features)
# Merge all available features into a single large vector via concatenation
x = layers.concatenate([title_features, body_features, tags_input])
# Stick a logistic regression for priority prediction on top of the features
priority_pred = layers.Dense(1, name="priority")(x)
# Stick a department classifier on top of the features
department_pred = layers.Dense(num_departments, name="department")(x)
# Instantiate an end-to-end model predicting both priority and department
model = keras.Model(
inputs=[title_input, body_input, tags_input],
outputs=[priority_pred, department_pred],
)
今はモデルをプロットします :
keras.utils.plot_model(model, "multi_input_and_output_model.png", show_shapes=True)
このモデルをコンパイルするとき、各出力に異なる損失を割り当てることができます。各損失に異なる重みを割り当てることさえできます — トータルの訓練損失へのそれらの寄与をモジュール化するためにです。
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=[
keras.losses.BinaryCrossentropy(from_logits=True),
keras.losses.CategoricalCrossentropy(from_logits=True),
],
loss_weights=[1.0, 0.2],
)
出力層は異なる名前を持ちますので、このように損失を指定することもできるでしょう :
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss={
"priority": keras.losses.BinaryCrossentropy(from_logits=True),
"department": keras.losses.CategoricalCrossentropy(from_logits=True),
},
loss_weights=[1.0, 0.2],
)
入力とターゲットの NumPy 配列のリストを渡すことでモデルを訓練できます :
# Dummy input data
title_data = np.random.randint(num_words, size=(1280, 10))
body_data = np.random.randint(num_words, size=(1280, 100))
tags_data = np.random.randint(2, size=(1280, num_tags)).astype("float32")
# Dummy target data
priority_targets = np.random.random(size=(1280, 1))
dept_targets = np.random.randint(2, size=(1280, num_departments))
model.fit(
{"title": title_data, "body": body_data, "tags": tags_data},
{"priority": priority_targets, "department": dept_targets},
epochs=2,
batch_size=32,
)
Epoch 1/2 40/40 [==============================] - 5s 45ms/step - loss: 1.3135 - priority_loss: 0.7064 - department_loss: 3.0354 Epoch 2/2 40/40 [==============================] - 2s 44ms/step - loss: 1.3223 - priority_loss: 0.6993 - department_loss: 3.1148 <tensorflow.python.keras.callbacks.History at 0x7ff81d30b320>
Dataset オブジェクトで fit を呼び出すとき、それは ([title_data, body_data, tags_data], [priority_targets, dept_targets]) のようなリストのタプルか、({‘title’: title_data, ‘body’: body_data, ‘tags’: tags_data}, {‘priority’: priority_targets, ‘department’: dept_targets}) のような辞書のタプルを yield するべきです。
より詳細な説明については、訓練と評価 ガイドを参照してください。
toy resnet モデル
マルチ入力と出力を持つモデルに加えて、Functional API は非線形接続トポロジー — これらは層がシークエンシャルに接続されないモデルです — を操作することも容易にします、これは Sequential API では扱えません。
このための一般的なユースケースは残差接続です。これを実演するために CIFAR10 のための toy ResNet モデルを構築しましょう :
inputs = keras.Input(shape=(32, 32, 3), name="img") x = layers.Conv2D(32, 3, activation="relu")(inputs) x = layers.Conv2D(64, 3, activation="relu")(x) block_1_output = layers.MaxPooling2D(3)(x) x = layers.Conv2D(64, 3, activation="relu", padding="same")(block_1_output) x = layers.Conv2D(64, 3, activation="relu", padding="same")(x) block_2_output = layers.add([x, block_1_output]) x = layers.Conv2D(64, 3, activation="relu", padding="same")(block_2_output) x = layers.Conv2D(64, 3, activation="relu", padding="same")(x) block_3_output = layers.add([x, block_2_output]) x = layers.Conv2D(64, 3, activation="relu")(block_3_output) x = layers.GlobalAveragePooling2D()(x) x = layers.Dense(256, activation="relu")(x) x = layers.Dropout(0.5)(x) outputs = layers.Dense(10)(x) model = keras.Model(inputs, outputs, name="toy_resnet") model.summary()
Model: "toy_resnet"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
img (InputLayer) [(None, 32, 32, 3)] 0
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 30, 30, 32) 896 img[0][0]
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, 28, 28, 64) 18496 conv2d_8[0][0]
__________________________________________________________________________________________________
max_pooling2d_2 (MaxPooling2D) (None, 9, 9, 64) 0 conv2d_9[0][0]
__________________________________________________________________________________________________
conv2d_10 (Conv2D) (None, 9, 9, 64) 36928 max_pooling2d_2[0][0]
__________________________________________________________________________________________________
conv2d_11 (Conv2D) (None, 9, 9, 64) 36928 conv2d_10[0][0]
__________________________________________________________________________________________________
add (Add) (None, 9, 9, 64) 0 conv2d_11[0][0]
max_pooling2d_2[0][0]
__________________________________________________________________________________________________
conv2d_12 (Conv2D) (None, 9, 9, 64) 36928 add[0][0]
__________________________________________________________________________________________________
conv2d_13 (Conv2D) (None, 9, 9, 64) 36928 conv2d_12[0][0]
__________________________________________________________________________________________________
add_1 (Add) (None, 9, 9, 64) 0 conv2d_13[0][0]
add[0][0]
__________________________________________________________________________________________________
conv2d_14 (Conv2D) (None, 7, 7, 64) 36928 add_1[0][0]
__________________________________________________________________________________________________
global_average_pooling2d (Globa (None, 64) 0 conv2d_14[0][0]
__________________________________________________________________________________________________
dense_6 (Dense) (None, 256) 16640 global_average_pooling2d[0][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 256) 0 dense_6[0][0]
__________________________________________________________________________________________________
dense_7 (Dense) (None, 10) 2570 dropout[0][0]
==================================================================================================
Total params: 223,242
Trainable params: 223,242
Non-trainable params: 0
__________________________________
モデルをプロットします :
keras.utils.plot_model(model, "mini_resnet.png", show_shapes=True)
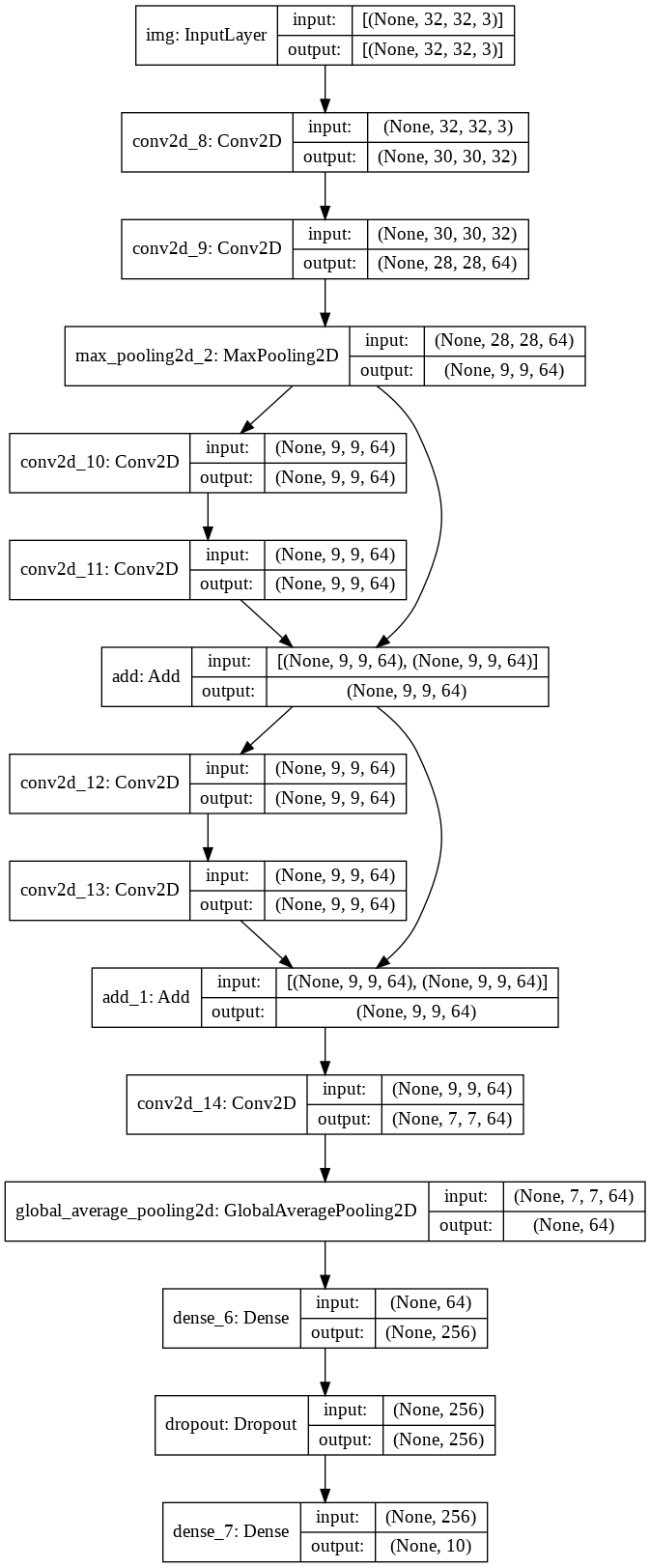
今はモデルを訓練しましょう :
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
x_train = x_train.astype("float32") / 255.0
x_test = x_test.astype("float32") / 255.0
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
model.compile(
optimizer=keras.optimizers.RMSprop(1e-3),
loss=keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=["acc"],
)
# We restrict the data to the first 1000 samples so as to limit execution time
# on Colab. Try to train on the entire dataset until convergence!
model.fit(x_train[:1000], y_train[:1000], batch_size=64, epochs=1, validation_split=0.2)
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170500096/170498071 [==============================] - 7s 0us/step 13/13 [==============================] - 5s 337ms/step - loss: 2.3085 - acc: 0.0943 - val_loss: 2.2973 - val_acc: 0.0950 <tensorflow.python.keras.callbacks.History at 0x7ff81b6525c0>
層を共有する
functional API のためのもう一つの良い使用方法は共有層を使用するモデルです。共有層は同じモデルで複数回再利用される層インスタンスです — それらは層グラフのマルチパスに対応する特徴を学習します。
共有層は類似空間 (例えば、類似語彙を特徴付けるテキストの 2 つの異なるピース) に由来する入力をエンコードするためにしばしば使用されます。それらは異なる入力に渡る情報の共有を可能にし、そしてそれらはより少ないデータ上でそのようなモデルを訓練することを可能にします。与えられた単語が入力の一つで見られるならば、それは共有層を通り抜ける総ての入力の処理に役立つでしょう。
functional API の層を共有するためには、同じ層インスタンスを複数回呼び出します。例えば、ここに2 つの異なるテキスト入力に渡り共有された Embedding 層があります :
# Embedding for 1000 unique words mapped to 128-dimensional vectors shared_embedding = layers.Embedding(1000, 128) # Variable-length sequence of integers text_input_a = keras.Input(shape=(None,), dtype="int32") # Variable-length sequence of integers text_input_b = keras.Input(shape=(None,), dtype="int32") # Reuse the same layer to encode both inputs encoded_input_a = shared_embedding(text_input_a) encoded_input_b = shared_embedding(text_input_b)
層のグラフのノードを抽出して再利用する
貴方が操作している層のグラフは静的データ構造ですので、それはアクセスして調査可能です。そしてこれは functional モデルをどのように画像としてプロットできるかです。
これはまた中間層 (グラフの「ノード」) の活性にアクセスできてそれらを他の場所で再利用できることも意味します — これは特徴抽出のようなもののために極めて有用です。
サンプルを見ましょう。これは ImageNet 上で事前訓練された重みを持つ VGG19 モデルです :
vgg19 = tf.keras.applications.VGG19()
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels.h5 574717952/574710816 [==============================] - 7s 0us/step
そしてこれらはグラフデータ構造に問い合わせて得られた、モデルの中間的な活性です :
features_list = [layer.output for layer in vgg19.layers]
新しい特徴抽出モデルを作成するためにこれらの特徴を使用できます、これは中間層の活性の値を返します :
feat_extraction_model = keras.Model(inputs=vgg19.input, outputs=features_list)
img = np.random.random((1, 224, 224, 3)).astype("float32")
extracted_features = feat_extraction_model(img)
他のものの中では、これは ニューラルスタイル・トランスファー のようなタスクのために役立ちます。
カスタム層を使用して API を拡張する
tf.keras は広範囲の組み込み層を含みます、例えば :
- 畳み込み層: Conv1D, Conv2D, Conv3D, Conv2DTranspose
- Pooling 層: MaxPooling1D, MaxPooling2D, MaxPooling3D, AveragePooling1D
- RNN 層: GRU, LSTM, ConvLSTM2D
- BatchNormalization, Dropout, Embedding 等。
しかし、もし貴方が必要なものを見つけられないならば、貴方自身の層を作成して API を拡張することは容易です。総ての層は Layer クラスをサブクラス化して以下を実装します
- call メソッド、これは層により行われる計算を指定します。
- build メソッド、これは層の重みを作成します (これは単にスタイル慣習であることに注意してください、何故ならば __init__ でも重みを作成できるからです)。
スクラッチから層を作成することについて更に学習するためには、ガイド カスタム層とモデルガイド を読んでください。
以下は tf.keras.layers.Dense の基本的な実装です :
class CustomDense(layers.Layer):
def __init__(self, units=32):
super(CustomDense, self).__init__()
self.units = units
def build(self, input_shape):
self.w = self.add_weight(
shape=(input_shape[-1], self.units),
initializer="random_normal",
trainable=True,
)
self.b = self.add_weight(
shape=(self.units,), initializer="random_normal", trainable=True
)
def call(self, inputs):
return tf.matmul(inputs, self.w) + self.b
inputs = keras.Input((4,))
outputs = CustomDense(10)(inputs)
model = keras.Model(inputs, outputs)
貴方のカスタム層でシリアライゼーションのサポートのためには、層インスタンスのコンストラクタ引数を返す get_config メソッドを定義します :
class CustomDense(layers.Layer):
def __init__(self, units=32):
super(CustomDense, self).__init__()
self.units = units
def build(self, input_shape):
self.w = self.add_weight(
shape=(input_shape[-1], self.units),
initializer="random_normal",
trainable=True,
)
self.b = self.add_weight(
shape=(self.units,), initializer="random_normal", trainable=True
)
def call(self, inputs):
return tf.matmul(inputs, self.w) + self.b
def get_config(self):
return {"units": self.units}
inputs = keras.Input((4,))
outputs = CustomDense(10)(inputs)
model = keras.Model(inputs, outputs)
config = model.get_config()
new_model = keras.Model.from_config(config, custom_objects={"CustomDense": CustomDense})
オプションで、クラスメソッド from_config(cls, config) を実装します、これはその config 辞書が与えられたときに層インスタンスを再作成するときに使用されます。from_config のデフォルト実装は :
def from_config(cls, config): return cls(**config)
いつ functional API を使用するか
新しいモデルを作成するために Keras functional API を使用するべきか、単に Model クラスを直接的にサブクラス化するべきでしょうか?一般に、functional API は高位で、より安全で容易で、そしてサブクラス化されたモデルがサポートしない多くの特徴を持ちます。
けれども、層の有向非巡回グラフのように容易には表現できないモデルを構築するとき、モデルのサブクラス化は貴方により大きな柔軟性を与えます。例えば、貴方は Tree-RNN を functional API では実装できないでしょう、Model を直接的にサブクラス化しなければならないでしょう。
functional API とモデル・サブクラス化の間の違いを深く見るためには、What are Symbolic and Imperative APIs in TensorFlow 2.0? を読んでください。
Functional API の強み
以下の特性はシーケンシャル・モデルに対しても総て真ですが (それはまたデータ構造です)、それらはサブクラス化されたモデルについては真ではありません (それは Python バイトコードであり、データ構造ではありません)。
より冗長ではありません (= Less verbose)
No super(MyClass, self).__init__(…), no def call(self, …):, 等。
以下を :
inputs = keras.Input(shape=(32,)) x = layers.Dense(64, activation='relu')(inputs) outputs = layers.Dense(10)(x) mlp = keras.Model(inputs, outputs)
サブクラス化されたバージョンと比較してください :
class MLP(keras.Model):
def __init__(self, **kwargs):
super(MLP, self).__init__(**kwargs)
self.dense_1 = layers.Dense(64, activation='relu')
self.dense_2 = layers.Dense(10)
def call(self, inputs):
x = self.dense_1(inputs)
return self.dense_2(x)
# Instantiate the model.
mlp = MLP()
# Necessary to create the model's state.
# The model doesn't have a state until it's called at least once.
_ = mlp(tf.zeros((1, 32)))
接続グラフを定義する間のモデル検証
functional API では、入力仕様 (shape と dtype) が (Input を使用して) 前もって作成されます。層を呼び出すたびに、その層はそれに渡された仕様が仮定に適合するかをチェックして、そしてそうでないならば役立つエラーメッセージをあげます。
これは functional API で構築できるどのようなモデルも実行されることを保証します。(収束関連のデバッグ以外の) 総てのデバッグはモデル構築時に静的に発生し、実行時ではありません。これはコンパイラの型チェックに類似しています。
functional モデルはプロット可能で調査可能です
モデルをグラフとしてプロットできます、そしてこのグラフの中間ノードに容易にアクセスできます。例えば、前のサンプルで見たように、中間層の活性を抽出して再利用するためにです :
features_list = [layer.output for layer in vgg19.layers] feat_extraction_model = keras.Model(inputs=vgg19.input, outputs=features_list)
functional モデルはシリアライズやクローンが可能です
functional モデルはコードのピースというよりもデータ構造ですから、それは安全にシリアライズ可能で (どのような元のコードにもアクセスすることなく) 正確に同じモデルを再作成することを可能にする単一ファイルとしてセーブできます。serialization & saving guide を見てください。
サブクラス化モデルをシリアライズするには、実装者がモデルレベルで get_config() と from_config() メソッドを指定する必要があります。
Functional API の弱み
それは動的アーキテクチャをサポートしません
functional API はモデルを層の DAG として扱います。これは殆どの深層学習アーキテクチャに対して真ですが、総てではありません — 例えば、再帰 (= recursive) ネットワークや Tree RNN はこの仮定に従いませんし functional API では実装できません。
API スタイルを混在させて適合させる (= mix-and-match)
functional API かモデルのサブクラス化の間で選択することは貴方をモデルの一つのカテゴリに制限する二者択一ではありません。tf.keras API の総てのモデルはそれらがシーケンシャル・モデルか、functional モデルか、あるいはスクラッチから書かれたサブクラス化モデルであろうと、互いに相互作用できます。
サブクラス化モデルや層の一部として functional モデルやシーケンシャル・モデルを貴方は常に利用できます :
units = 32
timesteps = 10
input_dim = 5
# Define a Functional model
inputs = keras.Input((None, units))
x = layers.GlobalAveragePooling1D()(inputs)
outputs = layers.Dense(1)(x)
model = keras.Model(inputs, outputs)
class CustomRNN(layers.Layer):
def __init__(self):
super(CustomRNN, self).__init__()
self.units = units
self.projection_1 = layers.Dense(units=units, activation="tanh")
self.projection_2 = layers.Dense(units=units, activation="tanh")
# Our previously-defined Functional model
self.classifier = model
def call(self, inputs):
outputs = []
state = tf.zeros(shape=(inputs.shape[0], self.units))
for t in range(inputs.shape[1]):
x = inputs[:, t, :]
h = self.projection_1(x)
y = h + self.projection_2(state)
state = y
outputs.append(y)
features = tf.stack(outputs, axis=1)
print(features.shape)
return self.classifier(features)
rnn_model = CustomRNN()
_ = rnn_model(tf.zeros((1, timesteps, input_dim)))
(1, 10, 32)
functional API で任意のサブクラス化層やモデルをそれが (以下のパターンの一つに従う) call メソッドを実装する限りは使用することができます :
- call(self, inputs, **kwargs) — ここで inputs は tensor か tensor のネスト構造 (e.g. tensor のリスト) で、そしてここで **kwargs は非 tensor 引数 (非 inputs) です。
- call(self, inputs, training=None, **kwargs) — ここで training は層が訓練モードか推論モードで動作するべきかを示すブーリアンです。
- call(self, inputs, mask=None, **kwargs) — ここで mask はブーリアンのマスク tensor です (例えば、RNN のために有用です)。
- call(self, inputs, training=None, mask=None, **kwargs) — もちろんマスキングと訓練固有の動作の両者を同時に持つことができます。
加えて、貴方のカスタム層やモデルで get_config メソッドを実装する場合、貴方がそれで作成する functional モデルは依然としてシリアライズ可能でクローン可能です。
ここに functional モデルで使用される、スクラッチから書かれた、カスタム RNN の素早いサンプルがあります :
units = 32
timesteps = 10
input_dim = 5
batch_size = 16
class CustomRNN(layers.Layer):
def __init__(self):
super(CustomRNN, self).__init__()
self.units = units
self.projection_1 = layers.Dense(units=units, activation="tanh")
self.projection_2 = layers.Dense(units=units, activation="tanh")
self.classifier = layers.Dense(1)
def call(self, inputs):
outputs = []
state = tf.zeros(shape=(inputs.shape[0], self.units))
for t in range(inputs.shape[1]):
x = inputs[:, t, :]
h = self.projection_1(x)
y = h + self.projection_2(state)
state = y
outputs.append(y)
features = tf.stack(outputs, axis=1)
return self.classifier(features)
# Note that you specify a static batch size for the inputs with the `batch_shape`
# arg, because the inner computation of `CustomRNN` requires a static batch size
# (when you create the `state` zeros tensor).
inputs = keras.Input(batch_shape=(batch_size, timesteps, input_dim))
x = layers.Conv1D(32, 3)(inputs)
outputs = CustomRNN()(x)
model = keras.Model(inputs, outputs)
rnn_model = CustomRNN()
_ = rnn_model(tf.zeros((1, 10, 5)))
以上