Keras 2 : examples : SimCLR : 対照事前学習を使用した半教師あり画像分類 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 12/14/2021 (keras 2.7.0)
* 本ページは、Keras の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
- Code examples : Computer Vision : Semi-supervised image classification using contrastive pretraining with SimCLR (Author: András Béres)
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP

Keras 2 : examples : SimCLR : 対照事前学習を使用した半教師あり画像分類
Description: STL-10 データセット上の半教師あり画像分類のための SimCLR による対照事前学習。
イントロダクション
半教師あり学習
半教師あり学習は 部分的にラベル付けされたデータセット を扱う機械学習パラダイムです。現実世界で深層学習を適用するとき、通常はそれを上手く動作させるために大規模なデータセットを集める必要があります。けれども、ラベル付けのコストがデータセットサイズに応じて線形にスケールするのに対して (各サンプルへのラベル付けは一定の時間がかかります)、モデル性能はそれに 劣線形 にスケールするだけです。これはより多くのサンプルへのラベル付けはよりコスト効率的でないことを意味します、その一方でラベル付けされていないデータの収集は一般に安価です、それは通常は大量に容易に利用可能だからです。
半教師あり学習は、部分的にラベル付けられたデータセットだけを必要としてラベル付けられていないサンプルを学習に上手く利用することでラベル効率的であることにより、この問題を解決することを提示します。
このサンプルでは、STL-10 半教師ありデータセット上で (ラベルを全く使用しないで) 対照学習によりエンコーダを事前訓練し、それからラベル付けされたサブセットだけを使用して再調整します。
対照学習
最も高いレベルでは、対照学習の裏の主要なアイデアは自己教師あり手法で 画像増強に対して不変である表現を学習する ことです。この目的の一つの問題は自明な劣化解法を持つことです : 表現が定数であり、入力画像に全く依存しない場合です。
対照学習は目的を次のように変更することでこのトラップを回避します : 表現空間内で同じ画像の増強バージョン/ビューの表現を互いに近づける一方で (ポジティブの対比)、同時に異なる画像を互いに遠ざけます (ネガティブの対比)。
そのような対照的なアプローチの一つは SimCLR で、これはこの目的を最適化するために必要な中核コンポーネントを本質的に識別し、この単純なアプローチをスケールすることで高いパフォーマンスを達成できます。
もう一つのアプローチは SimSiam ( Keras サンプル ) です、SimCLR との主要な違いは前者はその損失においてネガティブを使用しないことです。そのため、明示的に自明な解を防ぐのではなく、代わりに、アーキテクチャ設計により暗黙的に回避しています (predictor ネットワークを使用した非対称エンコーディングパスと、最終層でバッチ正規化 (BatchNorm) が適用されます)。
SimCLR の参考文献については、公式 Google AI ブログ投稿 を確認してください、そしてビジョンと言語の両者に渡る自己教師あり学習の概要については このブログ投稿 を確認してください。
セットアップ
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow import keras
from tensorflow.keras import layers
ハイパーパラメータのセットアップ
# Dataset hyperparameters
unlabeled_dataset_size = 100000
labeled_dataset_size = 5000
image_size = 96
image_channels = 3
# Algorithm hyperparameters
num_epochs = 20
batch_size = 525 # Corresponds to 200 steps per epoch
width = 128
temperature = 0.1
# Stronger augmentations for contrastive, weaker ones for supervised training
contrastive_augmentation = {"min_area": 0.25, "brightness": 0.6, "jitter": 0.2}
classification_augmentation = {"min_area": 0.75, "brightness": 0.3, "jitter": 0.1}
データセット
訓練の間、ラベル付けされていない画像の大量のバッチをラベル付けられた画像の少量のバッチとともに同時にロードします。
def prepare_dataset():
# Labeled and unlabeled samples are loaded synchronously
# with batch sizes selected accordingly
steps_per_epoch = (unlabeled_dataset_size + labeled_dataset_size) // batch_size
unlabeled_batch_size = unlabeled_dataset_size // steps_per_epoch
labeled_batch_size = labeled_dataset_size // steps_per_epoch
print(
f"batch size is {unlabeled_batch_size} (unlabeled) + {labeled_batch_size} (labeled)"
)
unlabeled_train_dataset = (
tfds.load("stl10", split="unlabelled", as_supervised=True, shuffle_files=True)
.shuffle(buffer_size=10 * unlabeled_batch_size)
.batch(unlabeled_batch_size)
)
labeled_train_dataset = (
tfds.load("stl10", split="train", as_supervised=True, shuffle_files=True)
.shuffle(buffer_size=10 * labeled_batch_size)
.batch(labeled_batch_size)
)
test_dataset = (
tfds.load("stl10", split="test", as_supervised=True)
.batch(batch_size)
.prefetch(buffer_size=tf.data.AUTOTUNE)
)
# Labeled and unlabeled datasets are zipped together
train_dataset = tf.data.Dataset.zip(
(unlabeled_train_dataset, labeled_train_dataset)
).prefetch(buffer_size=tf.data.AUTOTUNE)
return train_dataset, labeled_train_dataset, test_dataset
# Load STL10 dataset
train_dataset, labeled_train_dataset, test_dataset = prepare_dataset()
batch size is 500 (unlabeled) + 25 (labeled)
画像増強
対照学習のための 2 つの最も重要な画像増強は以下です :
- クロッピング : モデルが同じ画像の異なる部分を同様にエンコードすることを強制します、それを RandomTranslation と RandomZoom 層で実装します。
- カラー jitter : カラーヒストグラムを歪めることにより、タスクへの自明なカラーヒストグラム・ベースの解法を防ぎます。それを実装する原則的な方法はカラー空間におけるアフィン変換です。
このサンプルではランダム水平反転も使用します。
少ないラベル付けされたサンプル上での過剰適合を回避するために、教師あり分類に対してより弱いものと一緒に、より強い増強が対照学習のために適用されます。
カスタム前処理層としてランダムなカラー jitter を実装します。データ増強を前処理層として使用することは以下の 2 つの利点があります :
- データ増強は GPU 上でバッチで実行されますので、(Colab ノートブックや個人のマシンのような) 制約された CPU リソースを持つ環境のデータパイプラインが訓練の妨げ (ボトルネック) になることはありません。
- 配備がより簡単です、データ前処理パイプラインがモデルにカプセル化されていて、配備するときに再実装する必要がないからです。
# Distorts the color distibutions of images
class RandomColorAffine(layers.Layer):
def __init__(self, brightness=0, jitter=0, **kwargs):
super().__init__(**kwargs)
self.brightness = brightness
self.jitter = jitter
def call(self, images, training=True):
if training:
batch_size = tf.shape(images)[0]
# Same for all colors
brightness_scales = 1 + tf.random.uniform(
(batch_size, 1, 1, 1), minval=-self.brightness, maxval=self.brightness
)
# Different for all colors
jitter_matrices = tf.random.uniform(
(batch_size, 1, 3, 3), minval=-self.jitter, maxval=self.jitter
)
color_transforms = (
tf.eye(3, batch_shape=[batch_size, 1]) * brightness_scales
+ jitter_matrices
)
images = tf.clip_by_value(tf.matmul(images, color_transforms), 0, 1)
return images
# Image augmentation module
def get_augmenter(min_area, brightness, jitter):
zoom_factor = 1.0 - tf.sqrt(min_area)
return keras.Sequential(
[
keras.Input(shape=(image_size, image_size, image_channels)),
layers.Rescaling(1 / 255),
layers.RandomFlip("horizontal"),
layers.RandomTranslation(zoom_factor / 2, zoom_factor / 2),
layers.RandomZoom((-zoom_factor, 0.0), (-zoom_factor, 0.0)),
RandomColorAffine(brightness, jitter),
]
)
def visualize_augmentations(num_images):
# Sample a batch from a dataset
images = next(iter(train_dataset))[0][0][:num_images]
# Apply augmentations
augmented_images = zip(
images,
get_augmenter(**classification_augmentation)(images),
get_augmenter(**contrastive_augmentation)(images),
get_augmenter(**contrastive_augmentation)(images),
)
row_titles = [
"Original:",
"Weakly augmented:",
"Strongly augmented:",
"Strongly augmented:",
]
plt.figure(figsize=(num_images * 2.2, 4 * 2.2), dpi=100)
for column, image_row in enumerate(augmented_images):
for row, image in enumerate(image_row):
plt.subplot(4, num_images, row * num_images + column + 1)
plt.imshow(image)
if column == 0:
plt.title(row_titles[row], loc="left")
plt.axis("off")
plt.tight_layout()
visualize_augmentations(num_images=8)

エンコーダ・アーキテクチャ
# Define the encoder architecture
def get_encoder():
return keras.Sequential(
[
keras.Input(shape=(image_size, image_size, image_channels)),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),
layers.Flatten(),
layers.Dense(width, activation="relu"),
],
name="encoder",
)
教師ありベースラインモデル
ベースライン教師ありモデルはランダム初期化を使用して訓練されます。
# Baseline supervised training with random initialization
baseline_model = keras.Sequential(
[
keras.Input(shape=(image_size, image_size, image_channels)),
get_augmenter(**classification_augmentation),
get_encoder(),
layers.Dense(10),
],
name="baseline_model",
)
baseline_model.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc")],
)
baseline_history = baseline_model.fit(
labeled_train_dataset, epochs=num_epochs, validation_data=test_dataset
)
print(
"Maximal validation accuracy: {:.2f}%".format(
max(baseline_history.history["val_acc"]) * 100
)
)
Epoch 1/20 200/200 [==============================] - 8s 26ms/step - loss: 2.1769 - acc: 0.1794 - val_loss: 1.7424 - val_acc: 0.3341 Epoch 2/20 200/200 [==============================] - 3s 16ms/step - loss: 1.8366 - acc: 0.3139 - val_loss: 1.6184 - val_acc: 0.3989 Epoch 3/20 200/200 [==============================] - 3s 16ms/step - loss: 1.6331 - acc: 0.3912 - val_loss: 1.5344 - val_acc: 0.4125 Epoch 4/20 200/200 [==============================] - 3s 16ms/step - loss: 1.5439 - acc: 0.4216 - val_loss: 1.4052 - val_acc: 0.4712 Epoch 5/20 200/200 [==============================] - 4s 17ms/step - loss: 1.4576 - acc: 0.4575 - val_loss: 1.4337 - val_acc: 0.4729 Epoch 6/20 200/200 [==============================] - 3s 17ms/step - loss: 1.3723 - acc: 0.4875 - val_loss: 1.4054 - val_acc: 0.4746 Epoch 7/20 200/200 [==============================] - 3s 17ms/step - loss: 1.3445 - acc: 0.5066 - val_loss: 1.3030 - val_acc: 0.5200 Epoch 8/20 200/200 [==============================] - 3s 17ms/step - loss: 1.3015 - acc: 0.5255 - val_loss: 1.2720 - val_acc: 0.5378 Epoch 9/20 200/200 [==============================] - 3s 16ms/step - loss: 1.2244 - acc: 0.5452 - val_loss: 1.3211 - val_acc: 0.5220 Epoch 10/20 200/200 [==============================] - 3s 17ms/step - loss: 1.2204 - acc: 0.5494 - val_loss: 1.2898 - val_acc: 0.5381 Epoch 11/20 200/200 [==============================] - 4s 17ms/step - loss: 1.1359 - acc: 0.5766 - val_loss: 1.2138 - val_acc: 0.5648 Epoch 12/20 200/200 [==============================] - 3s 17ms/step - loss: 1.1228 - acc: 0.5855 - val_loss: 1.2602 - val_acc: 0.5429 Epoch 13/20 200/200 [==============================] - 3s 17ms/step - loss: 1.0853 - acc: 0.6000 - val_loss: 1.2716 - val_acc: 0.5591 Epoch 14/20 200/200 [==============================] - 3s 17ms/step - loss: 1.0632 - acc: 0.6078 - val_loss: 1.2832 - val_acc: 0.5591 Epoch 15/20 200/200 [==============================] - 3s 16ms/step - loss: 1.0268 - acc: 0.6157 - val_loss: 1.1712 - val_acc: 0.5882 Epoch 16/20 200/200 [==============================] - 3s 17ms/step - loss: 0.9594 - acc: 0.6440 - val_loss: 1.2904 - val_acc: 0.5573 Epoch 17/20 200/200 [==============================] - 3s 17ms/step - loss: 0.9524 - acc: 0.6517 - val_loss: 1.1854 - val_acc: 0.5955 Epoch 18/20 200/200 [==============================] - 3s 17ms/step - loss: 0.9118 - acc: 0.6672 - val_loss: 1.1974 - val_acc: 0.5845 Epoch 19/20 200/200 [==============================] - 3s 17ms/step - loss: 0.9187 - acc: 0.6686 - val_loss: 1.1703 - val_acc: 0.6025 Epoch 20/20 200/200 [==============================] - 3s 17ms/step - loss: 0.8520 - acc: 0.6911 - val_loss: 1.1312 - val_acc: 0.6149 Maximal validation accuracy: 61.49%
(訳者注: 実験結果)
Epoch 1/20 200/200 [==============================] - 17s 36ms/step - loss: 2.0508 - acc: 0.2278 - val_loss: 1.7167 - val_acc: 0.3490 Epoch 2/20 200/200 [==============================] - 9s 44ms/step - loss: 1.7145 - acc: 0.3536 - val_loss: 1.5843 - val_acc: 0.3916 Epoch 3/20 200/200 [==============================] - 8s 41ms/step - loss: 1.5769 - acc: 0.3972 - val_loss: 1.4358 - val_acc: 0.4556 Epoch 4/20 200/200 [==============================] - 8s 40ms/step - loss: 1.4740 - acc: 0.4504 - val_loss: 1.3911 - val_acc: 0.4800 Epoch 5/20 200/200 [==============================] - 8s 40ms/step - loss: 1.4283 - acc: 0.4598 - val_loss: 1.3607 - val_acc: 0.4921 Epoch 6/20 200/200 [==============================] - 8s 42ms/step - loss: 1.3713 - acc: 0.4876 - val_loss: 1.3316 - val_acc: 0.5173 Epoch 7/20 200/200 [==============================] - 8s 40ms/step - loss: 1.3207 - acc: 0.5086 - val_loss: 1.3403 - val_acc: 0.5182 Epoch 8/20 200/200 [==============================] - 8s 40ms/step - loss: 1.2562 - acc: 0.5342 - val_loss: 1.3192 - val_acc: 0.5161 Epoch 9/20 200/200 [==============================] - 8s 39ms/step - loss: 1.2132 - acc: 0.5440 - val_loss: 1.2324 - val_acc: 0.5518 Epoch 10/20 200/200 [==============================] - 8s 38ms/step - loss: 1.1714 - acc: 0.5738 - val_loss: 1.2343 - val_acc: 0.5508 Epoch 11/20 200/200 [==============================] - 8s 39ms/step - loss: 1.1422 - acc: 0.5806 - val_loss: 1.2960 - val_acc: 0.5379 Epoch 12/20 200/200 [==============================] - 8s 40ms/step - loss: 1.0808 - acc: 0.6024 - val_loss: 1.2793 - val_acc: 0.5445 Epoch 13/20 200/200 [==============================] - 8s 38ms/step - loss: 1.0427 - acc: 0.6176 - val_loss: 1.1666 - val_acc: 0.5847 Epoch 14/20 200/200 [==============================] - 8s 37ms/step - loss: 1.0280 - acc: 0.6294 - val_loss: 1.2528 - val_acc: 0.5567 Epoch 15/20 200/200 [==============================] - 7s 36ms/step - loss: 0.9782 - acc: 0.6428 - val_loss: 1.1969 - val_acc: 0.5724 Epoch 16/20 200/200 [==============================] - 7s 35ms/step - loss: 0.9576 - acc: 0.6508 - val_loss: 1.1399 - val_acc: 0.6001 Epoch 17/20 200/200 [==============================] - 7s 36ms/step - loss: 0.9238 - acc: 0.6582 - val_loss: 1.2620 - val_acc: 0.5854 Epoch 18/20 200/200 [==============================] - 7s 35ms/step - loss: 0.8944 - acc: 0.6768 - val_loss: 1.1618 - val_acc: 0.6089 Epoch 19/20 200/200 [==============================] - 7s 34ms/step - loss: 0.8675 - acc: 0.6850 - val_loss: 1.2403 - val_acc: 0.5901 Epoch 20/20 200/200 [==============================] - 7s 33ms/step - loss: 0.8384 - acc: 0.6916 - val_loss: 1.1158 - val_acc: 0.6288 Maximal validation accuracy: 62.88% CPU times: user 3min 31s, sys: 1min, total: 4min 32s Wall time: 3min 13s
対照事前学習のための自己教師ありモデル
ラベルのない画像上でエンコーダを対照損失で事前訓練します。非線形投影ヘッドがエンコーダの上に取り付けられます、それはエンコーダの表現の品質を改善するからです。
InfoNCE/NT-Xent/N-pairs 損失を使用します、これは以下のように解釈できます :
- バッチの各画像をそれが独自のクラスを持つかのように扱います。
- そして各「クラス」に対して 2 つのサンプル (増強ビューのペア) を持ちます。
- 各ビューの表現は総ての可能なペアの一つと比較されます (増強バージョンの両者に対して)。
- 比較された表現の temperature-scaled コサイン類似度をロジットとして使用します。
- 最後に、カテゴリカル交差エントロピーを「分類」損失として使用します。
事前訓練されるパフォーマンスを監視するために以下の 2 つのメトリクスが使用されます :
- 対照精度 (SimCLR Table 5) : 自己教師ありメトリックで、画像の表現が (現在のバッチの別の画像の表現よりも) 異なる増強バージョンのものに類似しているケースの比率です。自己教師ありメトリクスは、ラベルのないサンプルがある場合でさえ、ハイパーパラメータ調整のために使用できます。
- 線形プロービング (= probing) 精度 : 線形プロービングは自己教師あり分類器を評価するための一般的なメトリックです。それはエンコーダの特徴の上で訓練されたロジスティック回帰分類器の精度として計算されます。このケースでは、これは凍結されたエンコーダの上の単一 dense 層を訓練することにより成されます。分類器が事前訓練段階の後に訓練される従来のアプローチに反して、このサンプルでは事前訓練の間にそれを訓練することに注意してください。これは精度を僅かに低下させるかもしれませんが、そのようにして訓練の間のその値を監視することができて、それは実験とデバッグに役立ちます。
もう一つの広く使用されている教師ありメトリックは KNN 精度 です、これはエンコーダの特徴の上で訓練される KNN 分類器の精度で、このサンプルでは実装されません。
# Define the contrastive model with model-subclassing
class ContrastiveModel(keras.Model):
def __init__(self):
super().__init__()
self.temperature = temperature
self.contrastive_augmenter = get_augmenter(**contrastive_augmentation)
self.classification_augmenter = get_augmenter(**classification_augmentation)
self.encoder = get_encoder()
# Non-linear MLP as projection head
self.projection_head = keras.Sequential(
[
keras.Input(shape=(width,)),
layers.Dense(width, activation="relu"),
layers.Dense(width),
],
name="projection_head",
)
# Single dense layer for linear probing
self.linear_probe = keras.Sequential(
[layers.Input(shape=(width,)), layers.Dense(10)], name="linear_probe"
)
self.encoder.summary()
self.projection_head.summary()
self.linear_probe.summary()
def compile(self, contrastive_optimizer, probe_optimizer, **kwargs):
super().compile(**kwargs)
self.contrastive_optimizer = contrastive_optimizer
self.probe_optimizer = probe_optimizer
# self.contrastive_loss will be defined as a method
self.probe_loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
self.contrastive_loss_tracker = keras.metrics.Mean(name="c_loss")
self.contrastive_accuracy = keras.metrics.SparseCategoricalAccuracy(
name="c_acc"
)
self.probe_loss_tracker = keras.metrics.Mean(name="p_loss")
self.probe_accuracy = keras.metrics.SparseCategoricalAccuracy(name="p_acc")
@property
def metrics(self):
return [
self.contrastive_loss_tracker,
self.contrastive_accuracy,
self.probe_loss_tracker,
self.probe_accuracy,
]
def contrastive_loss(self, projections_1, projections_2):
# InfoNCE loss (information noise-contrastive estimation)
# NT-Xent loss (normalized temperature-scaled cross entropy)
# Cosine similarity: the dot product of the l2-normalized feature vectors
projections_1 = tf.math.l2_normalize(projections_1, axis=1)
projections_2 = tf.math.l2_normalize(projections_2, axis=1)
similarities = (
tf.matmul(projections_1, projections_2, transpose_b=True) / self.temperature
)
# The similarity between the representations of two augmented views of the
# same image should be higher than their similarity with other views
batch_size = tf.shape(projections_1)[0]
contrastive_labels = tf.range(batch_size)
self.contrastive_accuracy.update_state(contrastive_labels, similarities)
self.contrastive_accuracy.update_state(
contrastive_labels, tf.transpose(similarities)
)
# The temperature-scaled similarities are used as logits for cross-entropy
# a symmetrized version of the loss is used here
loss_1_2 = keras.losses.sparse_categorical_crossentropy(
contrastive_labels, similarities, from_logits=True
)
loss_2_1 = keras.losses.sparse_categorical_crossentropy(
contrastive_labels, tf.transpose(similarities), from_logits=True
)
return (loss_1_2 + loss_2_1) / 2
def train_step(self, data):
(unlabeled_images, _), (labeled_images, labels) = data
# Both labeled and unlabeled images are used, without labels
images = tf.concat((unlabeled_images, labeled_images), axis=0)
# Each image is augmented twice, differently
augmented_images_1 = self.contrastive_augmenter(images, training=True)
augmented_images_2 = self.contrastive_augmenter(images, training=True)
with tf.GradientTape() as tape:
features_1 = self.encoder(augmented_images_1, training=True)
features_2 = self.encoder(augmented_images_2, training=True)
# The representations are passed through a projection mlp
projections_1 = self.projection_head(features_1, training=True)
projections_2 = self.projection_head(features_2, training=True)
contrastive_loss = self.contrastive_loss(projections_1, projections_2)
gradients = tape.gradient(
contrastive_loss,
self.encoder.trainable_weights + self.projection_head.trainable_weights,
)
self.contrastive_optimizer.apply_gradients(
zip(
gradients,
self.encoder.trainable_weights + self.projection_head.trainable_weights,
)
)
self.contrastive_loss_tracker.update_state(contrastive_loss)
# Labels are only used in evalutation for an on-the-fly logistic regression
preprocessed_images = self.classification_augmenter(
labeled_images, training=True
)
with tf.GradientTape() as tape:
# the encoder is used in inference mode here to avoid regularization
# and updating the batch normalization paramers if they are used
features = self.encoder(preprocessed_images, training=False)
class_logits = self.linear_probe(features, training=True)
probe_loss = self.probe_loss(labels, class_logits)
gradients = tape.gradient(probe_loss, self.linear_probe.trainable_weights)
self.probe_optimizer.apply_gradients(
zip(gradients, self.linear_probe.trainable_weights)
)
self.probe_loss_tracker.update_state(probe_loss)
self.probe_accuracy.update_state(labels, class_logits)
return {m.name: m.result() for m in self.metrics}
def test_step(self, data):
labeled_images, labels = data
# For testing the components are used with a training=False flag
preprocessed_images = self.classification_augmenter(
labeled_images, training=False
)
features = self.encoder(preprocessed_images, training=False)
class_logits = self.linear_probe(features, training=False)
probe_loss = self.probe_loss(labels, class_logits)
self.probe_loss_tracker.update_state(probe_loss)
self.probe_accuracy.update_state(labels, class_logits)
# Only the probe metrics are logged at test time
return {m.name: m.result() for m in self.metrics[2:]}
# Contrastive pretraining
pretraining_model = ContrastiveModel()
pretraining_model.compile(
contrastive_optimizer=keras.optimizers.Adam(),
probe_optimizer=keras.optimizers.Adam(),
)
pretraining_history = pretraining_model.fit(
train_dataset, epochs=num_epochs, validation_data=test_dataset
)
print(
"Maximal validation accuracy: {:.2f}%".format(
max(pretraining_history.history["val_p_acc"]) * 100
)
)
Model: "encoder" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_4 (Conv2D) (None, 47, 47, 128) 3584 _________________________________________________________________ conv2d_5 (Conv2D) (None, 23, 23, 128) 147584 _________________________________________________________________ conv2d_6 (Conv2D) (None, 11, 11, 128) 147584 _________________________________________________________________ conv2d_7 (Conv2D) (None, 5, 5, 128) 147584 _________________________________________________________________ flatten_1 (Flatten) (None, 3200) 0 _________________________________________________________________ dense_2 (Dense) (None, 128) 409728 ================================================================= Total params: 856,064 Trainable params: 856,064 Non-trainable params: 0 _________________________________________________________________ Model: "projection_head" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_3 (Dense) (None, 128) 16512 _________________________________________________________________ dense_4 (Dense) (None, 128) 16512 ================================================================= Total params: 33,024 Trainable params: 33,024 Non-trainable params: 0 _________________________________________________________________ Model: "linear_probe" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense_5 (Dense) (None, 10) 1290 ================================================================= Total params: 1,290 Trainable params: 1,290 Non-trainable params: 0 _________________________________________________________________ Epoch 1/20 200/200 [==============================] - 70s 325ms/step - c_loss: 4.7788 - c_acc: 0.1340 - p_loss: 2.2030 - p_acc: 0.1922 - val_p_loss: 2.1043 - val_p_acc: 0.2540 Epoch 2/20 200/200 [==============================] - 67s 323ms/step - c_loss: 3.4836 - c_acc: 0.3047 - p_loss: 2.0159 - p_acc: 0.3030 - val_p_loss: 1.9833 - val_p_acc: 0.3120 Epoch 3/20 200/200 [==============================] - 65s 322ms/step - c_loss: 2.9157 - c_acc: 0.4187 - p_loss: 1.8896 - p_acc: 0.3598 - val_p_loss: 1.8621 - val_p_acc: 0.3556 Epoch 4/20 200/200 [==============================] - 67s 322ms/step - c_loss: 2.5837 - c_acc: 0.4867 - p_loss: 1.7965 - p_acc: 0.3912 - val_p_loss: 1.7400 - val_p_acc: 0.4006 Epoch 5/20 200/200 [==============================] - 67s 322ms/step - c_loss: 2.3462 - c_acc: 0.5403 - p_loss: 1.6961 - p_acc: 0.4138 - val_p_loss: 1.6655 - val_p_acc: 0.4190 Epoch 6/20 200/200 [==============================] - 65s 321ms/step - c_loss: 2.2214 - c_acc: 0.5714 - p_loss: 1.6325 - p_acc: 0.4322 - val_p_loss: 1.6242 - val_p_acc: 0.4366 Epoch 7/20 200/200 [==============================] - 67s 322ms/step - c_loss: 2.0618 - c_acc: 0.6098 - p_loss: 1.5793 - p_acc: 0.4470 - val_p_loss: 1.5348 - val_p_acc: 0.4663 Epoch 8/20 200/200 [==============================] - 65s 322ms/step - c_loss: 1.9532 - c_acc: 0.6360 - p_loss: 1.5173 - p_acc: 0.4652 - val_p_loss: 1.5248 - val_p_acc: 0.4700 Epoch 9/20 200/200 [==============================] - 65s 322ms/step - c_loss: 1.8487 - c_acc: 0.6602 - p_loss: 1.4631 - p_acc: 0.4798 - val_p_loss: 1.4587 - val_p_acc: 0.4905 Epoch 10/20 200/200 [==============================] - 65s 322ms/step - c_loss: 1.7837 - c_acc: 0.6767 - p_loss: 1.4310 - p_acc: 0.4992 - val_p_loss: 1.4265 - val_p_acc: 0.4924 Epoch 11/20 200/200 [==============================] - 65s 321ms/step - c_loss: 1.7133 - c_acc: 0.6955 - p_loss: 1.3764 - p_acc: 0.5090 - val_p_loss: 1.3663 - val_p_acc: 0.5169 Epoch 12/20 200/200 [==============================] - 66s 322ms/step - c_loss: 1.6655 - c_acc: 0.7064 - p_loss: 1.3511 - p_acc: 0.5140 - val_p_loss: 1.3779 - val_p_acc: 0.5071 Epoch 13/20 200/200 [==============================] - 67s 322ms/step - c_loss: 1.6110 - c_acc: 0.7198 - p_loss: 1.3182 - p_acc: 0.5282 - val_p_loss: 1.3259 - val_p_acc: 0.5303 Epoch 14/20 200/200 [==============================] - 66s 321ms/step - c_loss: 1.5727 - c_acc: 0.7312 - p_loss: 1.2965 - p_acc: 0.5308 - val_p_loss: 1.2858 - val_p_acc: 0.5422 Epoch 15/20 200/200 [==============================] - 67s 322ms/step - c_loss: 1.5477 - c_acc: 0.7361 - p_loss: 1.2751 - p_acc: 0.5432 - val_p_loss: 1.2795 - val_p_acc: 0.5472 Epoch 16/20 200/200 [==============================] - 65s 321ms/step - c_loss: 1.5127 - c_acc: 0.7448 - p_loss: 1.2562 - p_acc: 0.5498 - val_p_loss: 1.2731 - val_p_acc: 0.5461 Epoch 17/20 200/200 [==============================] - 67s 321ms/step - c_loss: 1.4811 - c_acc: 0.7517 - p_loss: 1.2306 - p_acc: 0.5574 - val_p_loss: 1.2439 - val_p_acc: 0.5630 Epoch 18/20 200/200 [==============================] - 67s 321ms/step - c_loss: 1.4598 - c_acc: 0.7576 - p_loss: 1.2215 - p_acc: 0.5544 - val_p_loss: 1.2352 - val_p_acc: 0.5623 Epoch 19/20 200/200 [==============================] - 65s 321ms/step - c_loss: 1.4349 - c_acc: 0.7631 - p_loss: 1.2161 - p_acc: 0.5662 - val_p_loss: 1.2670 - val_p_acc: 0.5479 Epoch 20/20 200/200 [==============================] - 66s 321ms/step - c_loss: 1.4159 - c_acc: 0.7691 - p_loss: 1.2044 - p_acc: 0.5656 - val_p_loss: 1.2204 - val_p_acc: 0.5624 Maximal validation accuracy: 56.30%
_________________________________________________________________ Epoch 1/20 200/200 [==============================] - 57s 246ms/step - c_loss: 4.6610 - c_acc: 0.1476 - p_loss: 2.2421 - p_acc: 0.1658 - val_p_loss: 2.0948 - val_p_acc: 0.2559 Epoch 2/20 200/200 [==============================] - 51s 246ms/step - c_loss: 3.3137 - c_acc: 0.3381 - p_loss: 2.0254 - p_acc: 0.3070 - val_p_loss: 1.9363 - val_p_acc: 0.3462 Epoch 3/20 200/200 [==============================] - 50s 237ms/step - c_loss: 2.7812 - c_acc: 0.4478 - p_loss: 1.8806 - p_acc: 0.3726 - val_p_loss: 1.8496 - val_p_acc: 0.3514 Epoch 4/20 200/200 [==============================] - 50s 239ms/step - c_loss: 2.4409 - c_acc: 0.5209 - p_loss: 1.7658 - p_acc: 0.3976 - val_p_loss: 1.7120 - val_p_acc: 0.4115 Epoch 5/20 200/200 [==============================] - 49s 234ms/step - c_loss: 2.1790 - c_acc: 0.5812 - p_loss: 1.6827 - p_acc: 0.4170 - val_p_loss: 1.6411 - val_p_acc: 0.4313 Epoch 6/20 200/200 [==============================] - 48s 231ms/step - c_loss: 2.0178 - c_acc: 0.6201 - p_loss: 1.6230 - p_acc: 0.4338 - val_p_loss: 1.6055 - val_p_acc: 0.4367 Epoch 7/20 200/200 [==============================] - 49s 233ms/step - c_loss: 1.9009 - c_acc: 0.6490 - p_loss: 1.5630 - p_acc: 0.4548 - val_p_loss: 1.5397 - val_p_acc: 0.4521 Epoch 8/20 200/200 [==============================] - 49s 233ms/step - c_loss: 1.8067 - c_acc: 0.6726 - p_loss: 1.5106 - p_acc: 0.4640 - val_p_loss: 1.4932 - val_p_acc: 0.4651 Epoch 9/20 200/200 [==============================] - 49s 232ms/step - c_loss: 1.7326 - c_acc: 0.6902 - p_loss: 1.4579 - p_acc: 0.4754 - val_p_loss: 1.4573 - val_p_acc: 0.4810 Epoch 10/20 200/200 [==============================] - 50s 236ms/step - c_loss: 1.6749 - c_acc: 0.7058 - p_loss: 1.4170 - p_acc: 0.4856 - val_p_loss: 1.4091 - val_p_acc: 0.4961 Epoch 11/20 200/200 [==============================] - 49s 234ms/step - c_loss: 1.6262 - c_acc: 0.7163 - p_loss: 1.3703 - p_acc: 0.5076 - val_p_loss: 1.4089 - val_p_acc: 0.5017 Epoch 12/20 200/200 [==============================] - 49s 236ms/step - c_loss: 1.5657 - c_acc: 0.7310 - p_loss: 1.3394 - p_acc: 0.5244 - val_p_loss: 1.3493 - val_p_acc: 0.5173 Epoch 13/20 200/200 [==============================] - 48s 227ms/step - c_loss: 1.5415 - c_acc: 0.7392 - p_loss: 1.3126 - p_acc: 0.5300 - val_p_loss: 1.3238 - val_p_acc: 0.5268 Epoch 14/20 200/200 [==============================] - 48s 229ms/step - c_loss: 1.4853 - c_acc: 0.7507 - p_loss: 1.2853 - p_acc: 0.5314 - val_p_loss: 1.2914 - val_p_acc: 0.5400 Epoch 15/20 200/200 [==============================] - 48s 230ms/step - c_loss: 1.4662 - c_acc: 0.7569 - p_loss: 1.2666 - p_acc: 0.5418 - val_p_loss: 1.2769 - val_p_acc: 0.5461 Epoch 16/20 200/200 [==============================] - 48s 230ms/step - c_loss: 1.4265 - c_acc: 0.7662 - p_loss: 1.2407 - p_acc: 0.5510 - val_p_loss: 1.2515 - val_p_acc: 0.5508 Epoch 17/20 200/200 [==============================] - 48s 228ms/step - c_loss: 1.4006 - c_acc: 0.7727 - p_loss: 1.2277 - p_acc: 0.5584 - val_p_loss: 1.2793 - val_p_acc: 0.5444 Epoch 18/20 200/200 [==============================] - 48s 228ms/step - c_loss: 1.3809 - c_acc: 0.7777 - p_loss: 1.2033 - p_acc: 0.5718 - val_p_loss: 1.2451 - val_p_acc: 0.5536 Epoch 19/20 200/200 [==============================] - 48s 228ms/step - c_loss: 1.3765 - c_acc: 0.7788 - p_loss: 1.1982 - p_acc: 0.5710 - val_p_loss: 1.2477 - val_p_acc: 0.5599 Epoch 20/20 200/200 [==============================] - 48s 231ms/step - c_loss: 1.3493 - c_acc: 0.7866 - p_loss: 1.1875 - p_acc: 0.5720 - val_p_loss: 1.2058 - val_p_acc: 0.5740 Maximal validation accuracy: 57.40% CPU times: user 26min 54s, sys: 2min 50s, total: 29min 45s Wall time: 23min 33s
事前訓練済みエンコーダの教師あり再調整
次にエンコーダを、その上に単一のランダムに初期化された完全結合分類器を装着して、ラベルのあるサンプル上で再調整します。
# Supervised finetuning of the pretrained encoder
finetuning_model = keras.Sequential(
[
layers.Input(shape=(image_size, image_size, image_channels)),
get_augmenter(**classification_augmentation),
pretraining_model.encoder,
layers.Dense(10),
],
name="finetuning_model",
)
finetuning_model.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc")],
)
finetuning_history = finetuning_model.fit(
labeled_train_dataset, epochs=num_epochs, validation_data=test_dataset
)
print(
"Maximal validation accuracy: {:.2f}%".format(
max(finetuning_history.history["val_acc"]) * 100
)
)
Epoch 1/20 200/200 [==============================] - 4s 17ms/step - loss: 1.9942 - acc: 0.2554 - val_loss: 1.4278 - val_acc: 0.4647 Epoch 2/20 200/200 [==============================] - 3s 16ms/step - loss: 1.5209 - acc: 0.4373 - val_loss: 1.3119 - val_acc: 0.5170 Epoch 3/20 200/200 [==============================] - 3s 17ms/step - loss: 1.3210 - acc: 0.5132 - val_loss: 1.2328 - val_acc: 0.5529 Epoch 4/20 200/200 [==============================] - 3s 17ms/step - loss: 1.1932 - acc: 0.5603 - val_loss: 1.1328 - val_acc: 0.5872 Epoch 5/20 200/200 [==============================] - 3s 17ms/step - loss: 1.1217 - acc: 0.5984 - val_loss: 1.1508 - val_acc: 0.5906 Epoch 6/20 200/200 [==============================] - 3s 16ms/step - loss: 1.0665 - acc: 0.6176 - val_loss: 1.2544 - val_acc: 0.5753 Epoch 7/20 200/200 [==============================] - 3s 16ms/step - loss: 0.9890 - acc: 0.6510 - val_loss: 1.0107 - val_acc: 0.6409 Epoch 8/20 200/200 [==============================] - 3s 16ms/step - loss: 0.9775 - acc: 0.6468 - val_loss: 1.0907 - val_acc: 0.6150 Epoch 9/20 200/200 [==============================] - 3s 17ms/step - loss: 0.9105 - acc: 0.6736 - val_loss: 1.1057 - val_acc: 0.6183 Epoch 10/20 200/200 [==============================] - 3s 17ms/step - loss: 0.8658 - acc: 0.6895 - val_loss: 1.1794 - val_acc: 0.5938 Epoch 11/20 200/200 [==============================] - 3s 17ms/step - loss: 0.8503 - acc: 0.6946 - val_loss: 1.0764 - val_acc: 0.6325 Epoch 12/20 200/200 [==============================] - 3s 17ms/step - loss: 0.7973 - acc: 0.7193 - val_loss: 1.0065 - val_acc: 0.6561 Epoch 13/20 200/200 [==============================] - 3s 16ms/step - loss: 0.7516 - acc: 0.7319 - val_loss: 1.0955 - val_acc: 0.6345 Epoch 14/20 200/200 [==============================] - 3s 16ms/step - loss: 0.7504 - acc: 0.7406 - val_loss: 1.1041 - val_acc: 0.6386 Epoch 15/20 200/200 [==============================] - 3s 16ms/step - loss: 0.7419 - acc: 0.7324 - val_loss: 1.0680 - val_acc: 0.6492 Epoch 16/20 200/200 [==============================] - 3s 17ms/step - loss: 0.7318 - acc: 0.7265 - val_loss: 1.1635 - val_acc: 0.6313 Epoch 17/20 200/200 [==============================] - 3s 17ms/step - loss: 0.6904 - acc: 0.7505 - val_loss: 1.0826 - val_acc: 0.6503 Epoch 18/20 200/200 [==============================] - 3s 17ms/step - loss: 0.6389 - acc: 0.7714 - val_loss: 1.1260 - val_acc: 0.6364 Epoch 19/20 200/200 [==============================] - 3s 16ms/step - loss: 0.6355 - acc: 0.7829 - val_loss: 1.0750 - val_acc: 0.6554 Epoch 20/20 200/200 [==============================] - 3s 17ms/step - loss: 0.6279 - acc: 0.7758 - val_loss: 1.0465 - val_acc: 0.6604 Maximal validation accuracy: 66.04%
Epoch 1/20 200/200 [==============================] - 16s 61ms/step - loss: 1.7879 - acc: 0.3124 - val_loss: 1.5504 - val_acc: 0.4453 Epoch 2/20 200/200 [==============================] - 6s 31ms/step - loss: 1.4117 - acc: 0.4716 - val_loss: 1.3243 - val_acc: 0.5123 Epoch 3/20 200/200 [==============================] - 7s 32ms/step - loss: 1.2341 - acc: 0.5522 - val_loss: 1.2372 - val_acc: 0.5424 Epoch 4/20 200/200 [==============================] - 6s 30ms/step - loss: 1.1313 - acc: 0.5872 - val_loss: 1.1218 - val_acc: 0.5943 Epoch 5/20 200/200 [==============================] - 6s 31ms/step - loss: 1.0624 - acc: 0.6212 - val_loss: 1.1013 - val_acc: 0.6012 Epoch 6/20 200/200 [==============================] - 6s 31ms/step - loss: 1.0155 - acc: 0.6348 - val_loss: 1.0468 - val_acc: 0.6271 Epoch 7/20 200/200 [==============================] - 6s 31ms/step - loss: 0.9770 - acc: 0.6486 - val_loss: 1.0407 - val_acc: 0.6309 Epoch 8/20 200/200 [==============================] - 6s 31ms/step - loss: 0.9058 - acc: 0.6770 - val_loss: 1.1168 - val_acc: 0.6190 Epoch 9/20 200/200 [==============================] - 6s 31ms/step - loss: 0.8768 - acc: 0.6788 - val_loss: 1.0395 - val_acc: 0.6329 Epoch 10/20 200/200 [==============================] - 6s 31ms/step - loss: 0.8488 - acc: 0.6978 - val_loss: 1.2707 - val_acc: 0.5889 Epoch 11/20 200/200 [==============================] - 6s 31ms/step - loss: 0.8140 - acc: 0.7044 - val_loss: 1.0013 - val_acc: 0.6554 Epoch 12/20 200/200 [==============================] - 7s 33ms/step - loss: 0.7885 - acc: 0.7182 - val_loss: 1.0651 - val_acc: 0.6521 Epoch 13/20 200/200 [==============================] - 6s 31ms/step - loss: 0.7769 - acc: 0.7202 - val_loss: 1.0589 - val_acc: 0.6369 Epoch 14/20 200/200 [==============================] - 6s 31ms/step - loss: 0.7146 - acc: 0.7446 - val_loss: 1.1355 - val_acc: 0.6301 Epoch 15/20 200/200 [==============================] - 6s 30ms/step - loss: 0.7041 - acc: 0.7484 - val_loss: 1.1911 - val_acc: 0.6151 Epoch 16/20 200/200 [==============================] - 6s 31ms/step - loss: 0.6802 - acc: 0.7634 - val_loss: 1.0836 - val_acc: 0.6451 Epoch 17/20 200/200 [==============================] - 6s 31ms/step - loss: 0.6422 - acc: 0.7678 - val_loss: 1.0711 - val_acc: 0.6514 Epoch 18/20 200/200 [==============================] - 6s 31ms/step - loss: 0.6303 - acc: 0.7698 - val_loss: 1.1025 - val_acc: 0.6392 Epoch 19/20 200/200 [==============================] - 6s 31ms/step - loss: 0.6219 - acc: 0.7808 - val_loss: 1.0282 - val_acc: 0.6786 Epoch 20/20 200/200 [==============================] - 6s 31ms/step - loss: 0.5853 - acc: 0.7916 - val_loss: 1.0457 - val_acc: 0.6637 Maximal validation accuracy: 67.86% CPU times: user 3min 29s, sys: 17.6 s, total: 3min 47s Wall time: 3min
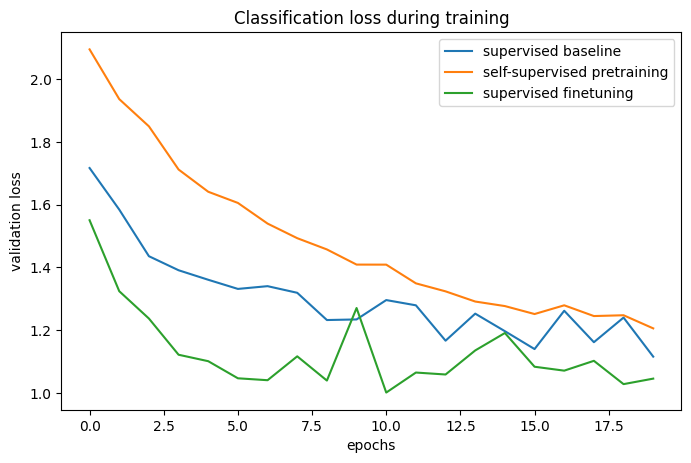
ベースラインに対する比較
# The classification accuracies of the baseline and the pretraining + finetuning process:
def plot_training_curves(pretraining_history, finetuning_history, baseline_history):
for metric_key, metric_name in zip(["acc", "loss"], ["accuracy", "loss"]):
plt.figure(figsize=(8, 5), dpi=100)
plt.plot(
baseline_history.history[f"val_{metric_key}"], label="supervised baseline"
)
plt.plot(
pretraining_history.history[f"val_p_{metric_key}"],
label="self-supervised pretraining",
)
plt.plot(
finetuning_history.history[f"val_{metric_key}"],
label="supervised finetuning",
)
plt.legend()
plt.title(f"Classification {metric_name} during training")
plt.xlabel("epochs")
plt.ylabel(f"validation {metric_name}")
plot_training_curves(pretraining_history, finetuning_history, baseline_history)



以上