🦜️🔗LangChain : モジュール : 検索 (翻訳/解説)
翻訳 : (株)クラスキャット セールスインフォメーション
作成日時 : 08/30/2023
* 本ページは、LangChain の以下のドキュメントを翻訳した上で適宜、補足説明したものです:
* サンプルコードの動作確認はしておりますが、必要な場合には適宜、追加改変しています。
* ご自由にリンクを張って頂いてかまいませんが、sales-info@classcat.com までご一報いただけると嬉しいです。

- 人工知能研究開発支援
- 人工知能研修サービス(経営者層向けオンサイト研修)
- テクニカルコンサルティングサービス
- 実証実験(プロトタイプ構築)
- アプリケーションへの実装
- 人工知能研修サービス
- PoC(概念実証)を失敗させないための支援
- お住まいの地域に関係なく Web ブラウザからご参加頂けます。事前登録 が必要ですのでご注意ください。
◆ お問合せ : 本件に関するお問い合わせ先は下記までお願いいたします。
- 株式会社クラスキャット セールス・マーケティング本部 セールス・インフォメーション
- sales-info@classcat.com ; Web: www.classcat.com ; ClassCatJP
🦜️🔗 LangChain : モジュール : 検索
多くの LLM アプリケーションはモデルの訓練セットの一部ではないユーザ固有のデータを必要とします。これを実現する主要な方法は検索増強生成 (Retrieval Augmented Generation, RAG) を通してです。このプロセスでは、外部データは取得されてから生成ステップを実行するときに LLM に渡されます。
LangChain は単純なものから複雑なものまで RAG アプリケーションのためのビルディングブロックすべてを提供します。ドキュメントのこのセクションは検索ステップに関連するすべてをカバーします – e.g. データの取得。これは単純に思われますが、微妙に複雑である可能性があります。これは幾つかの主要モジュールを含みます。
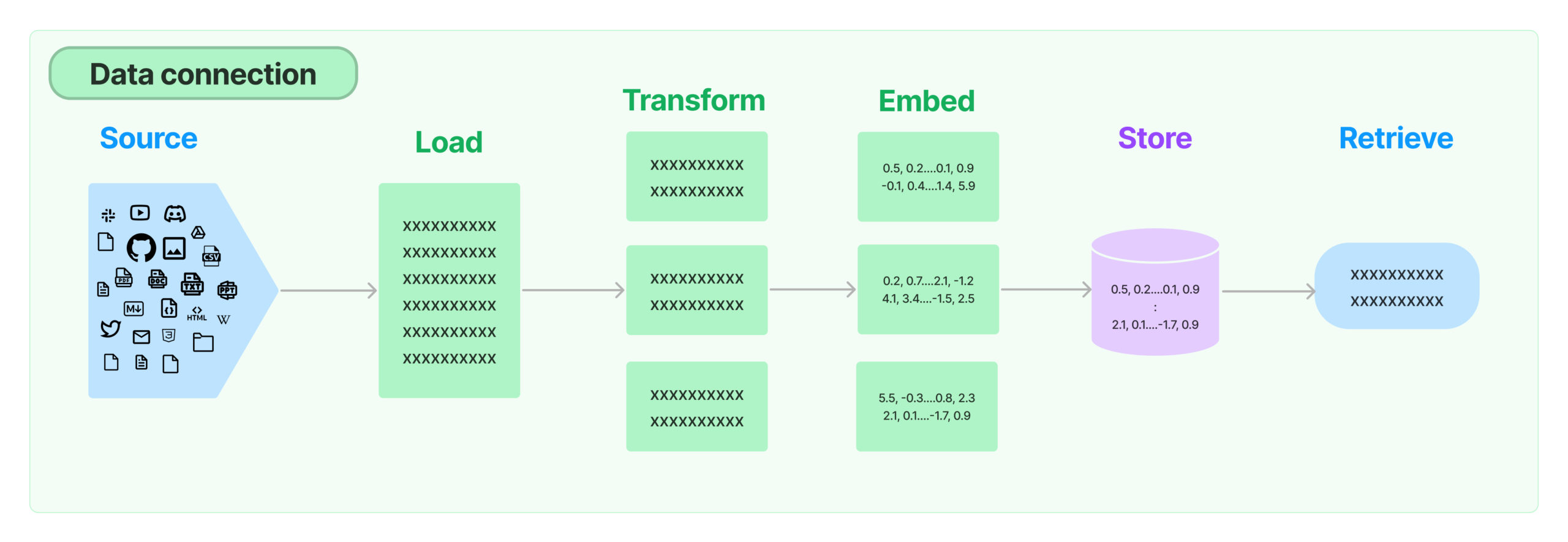
多くの様々なソースからドキュメントをロードします。LangChain は 100 以上の様々な文書ローダ、そして AirByte や Unstructured のようなこの空間内の他の主要なプロバイダーとの統合を提供しています。すべてのタイプの場所 (プライベート s3 バケット, 公開 Web サイト) からすべての種類のドキュメント (html, PDF, コード) をロードするための統合を提供します。
検索の主要パートはドキュメントの関連部分だけを取得することです。これは検索のためにドキュメントを最良に準備する幾つかの変換ステップを含みます。ここでの主要なものの一つは大規模ドキュメントを小さいチャンクに分割 (or チャンク化) することです。LangChain はこれを行なうための幾つかの様々なアルゴリズムと、特定のドキュメントタイプ (コード, markdown 等) に最適化されたロジックを提供しています。
検索のもう一つの主要パートはドキュメント用の埋め込みの作成になります。埋め込みはテキストの意味論的 (semantic) 意味 (meaning) を捉え、類似しているテキストの別のピースを素早く効率的に見つけることを可能にします。LangChain は、オープンソースからプロプライエタリな API まで 25 以上の様々な埋め込みプロバイダーと手法との統合を提供し、ニーズに最適なものを選択することを可能にします。LangChain は標準インターフェイスを公開し、モデル間で簡単に交換できることを可能にします。
埋め込みの増大により、これらの埋め込みの効率的なストレージと検索をサポートするデータベースのニーズが現われました。LangChain は、オープンソースのローカルのものからクラウドにホストされたプロプライエタリなものまで 50 以上の様々なベクトルストアとの統合を提供し、ニーズに最適なものを選択することを可能にします。LangChain は標準インターフェイスを公開し、ベクトルストア間で簡単に交換できることを可能にします。
データがデータベースにストアされれば、それを依然として検索する必要があります。LangChain は多くの様々な検索アルゴリズムをサポートし、最も価値を付加できる場所の一つです。始めるのが簡単な基本的な手法をサポートします – つまり単純セマンティック検索です。ただし、パフォーマンスを向上させるためにこの上にアルゴリズムのコレクションも追加しました。これらは以下を含みます :
- 親ドキュメント Retriever : これは、親ドキュメント毎に複数の埋め込みを作成することを可能にし、より小さいチャンクを検索しながら大きいコンテキストを返すことを可能にします。
- 自己クエリー Retriever : ユーザ質問は単なる意味論的なものではなく、メタデータフィルタとして最良に表現できるあるロジックを表現するものへの参照を含むことも多いです。自己クエリーはクエリー内に存在する他のメタデータフィルタからのクエリーの意味論的部分を解析することを可能にします。
- アンサンブル Retriever : 時に複数の異なるソースからドキュメントを取得したい場合、あるいは複数の異なるアルゴリズムを使用したい場合があるかもしれません。アンサンブル retriever はこれを簡単に行なうことを可能にします。
- And more!
以上