Double Q-Learning
Async-DQN は パックマンの攻略 で試していますが、今回は Double Q-Learning をベースにスペースインベーダの攻略をしてみます。
参照論文は以下 :
Deep Reinforcement Learning with Double Q-learning
H. v. Hasseltand, A. Guez and D. Silver
Google DeepMind
H. v. Hasseltand, A. Guez and D. Silver
Google DeepMind
Abstract : 通常の Q 学習アルゴリズムはある条件下では行動価値 (action values) を過大評価することが知られています。そのような過大評価が共通のものか、性能を害するか、一般的に防げるかについては知られていません。このペーパーでは、これら全ての疑問に肯定的に答えます。特に、最初に最近の DQN アルゴリズムが Atari 2600 domain の幾つかのゲームでは本質的な過大評価の害を受けることを示します。そして Double Q-learning アルゴリズムの背後のアイデアが large-scale 関数近似 (large-scale function approximation) で動作するために一般化できることを示します。DQN アルゴリズムへの特定の実装を提案し結果的なアルゴリズムが観測される過大評価を減じるだけでなく、幾つかのゲームではより良いパフォーマンスにつながることを示します。
TensorFlow でスペースインベーダ攻略
パックマンで Async-DQN を試したので、スペースインベーダで Double Q-Learning を試してみました。実装のポイントはネットワークを2つ持つことです。
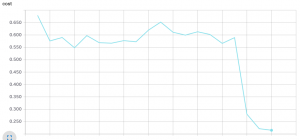
左図は 2.0e+5 ステップまでの損失グラフ、右図は 1.0e+5 ステップのころの評価結果です :
|  |
以上